Gradients qui disparaissent et qui explosent
Deep learning intermédiaire avec PyTorch

Michal Oleszak
Machine Learning Engineer
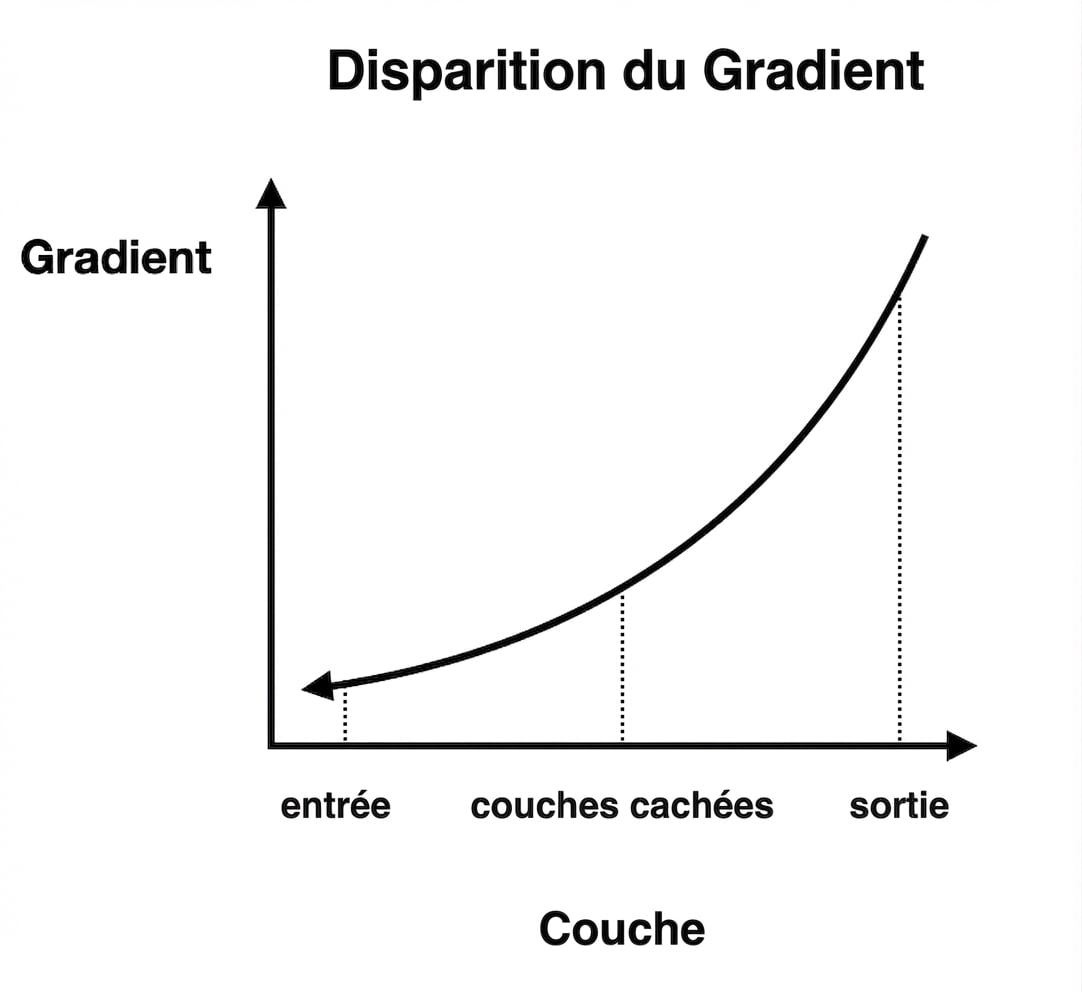
Gradients qui disparaissent
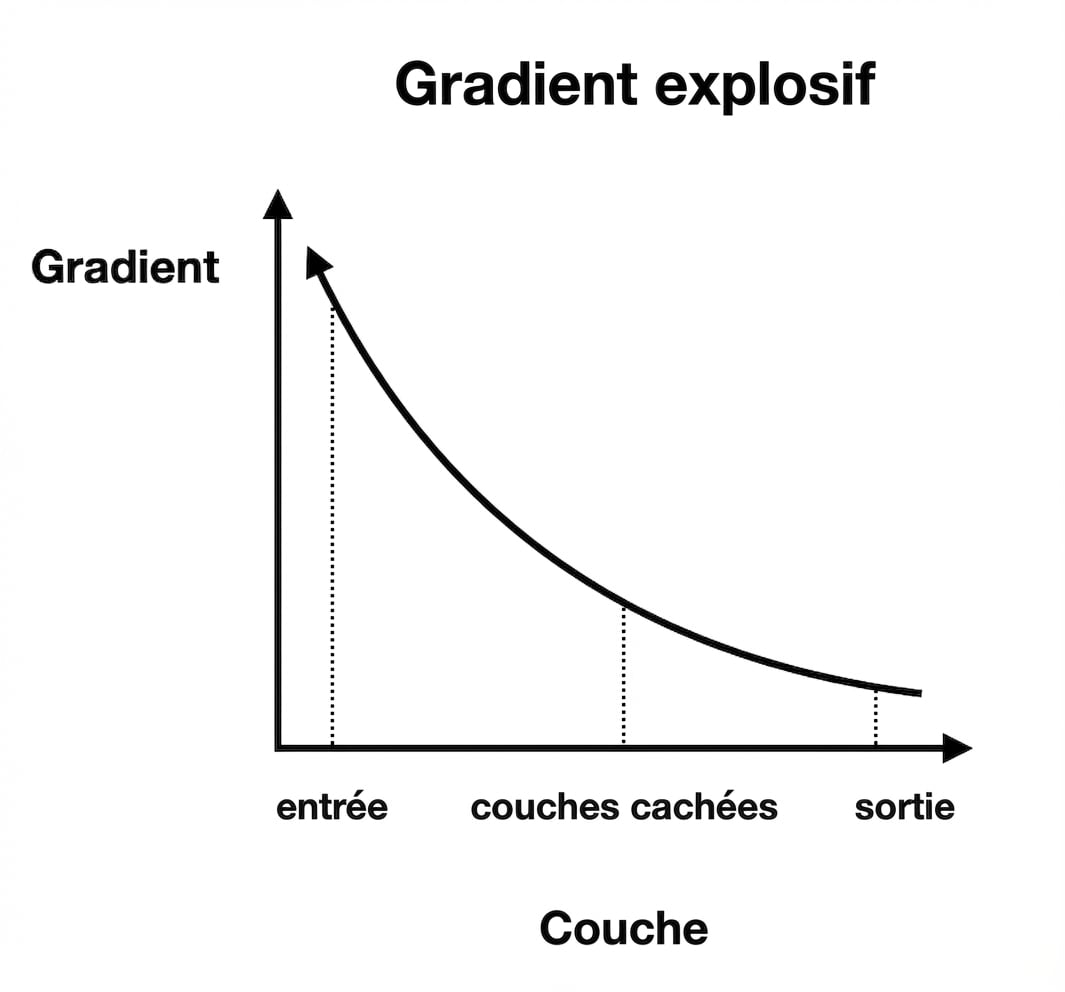
Gradients qui explosent
Solution aux gradients instables
- Bonne initialisation des poids
- Bonnes activations
- Normalisation par lot

Fonctions d’activation
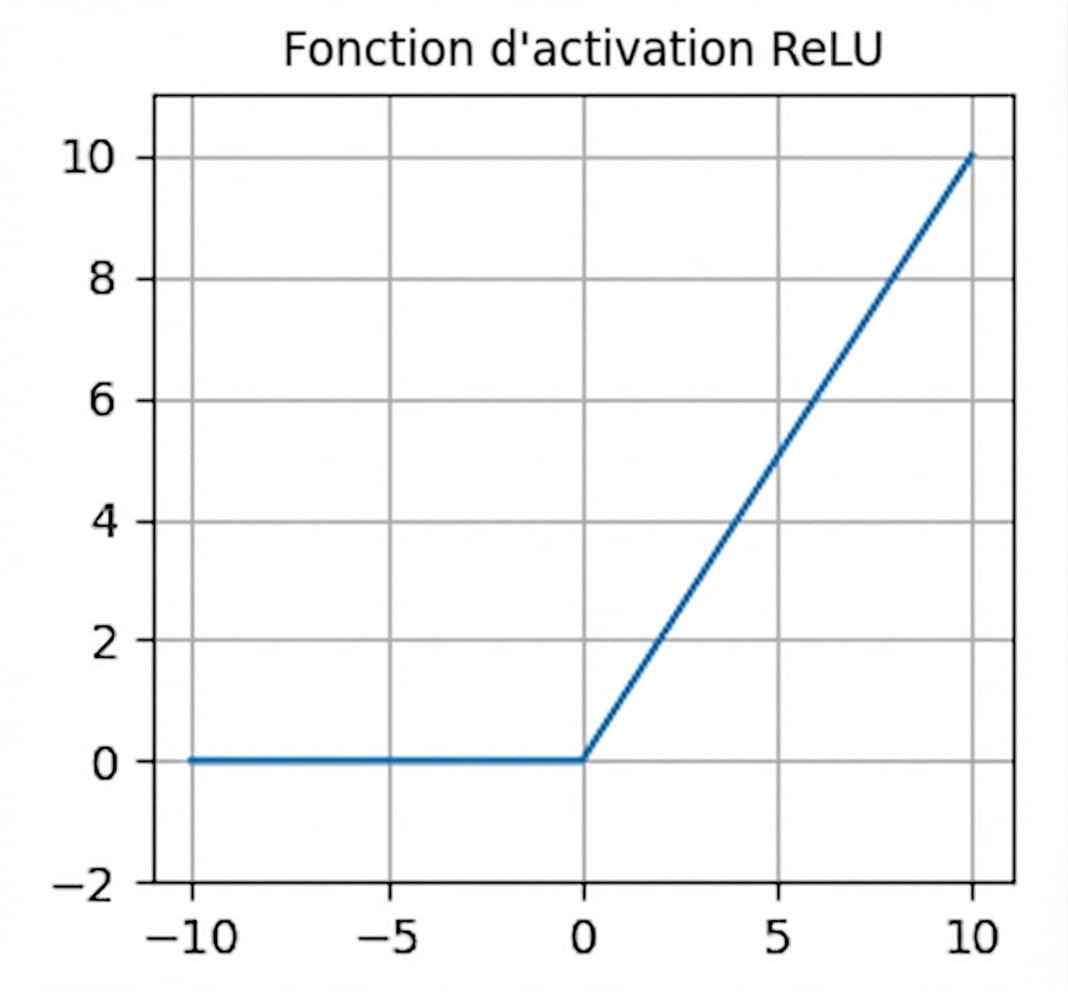
- Souvent l’activation par défaut
nn.functional.relu()- Zéro pour les entrées négatives — neurones « morts »
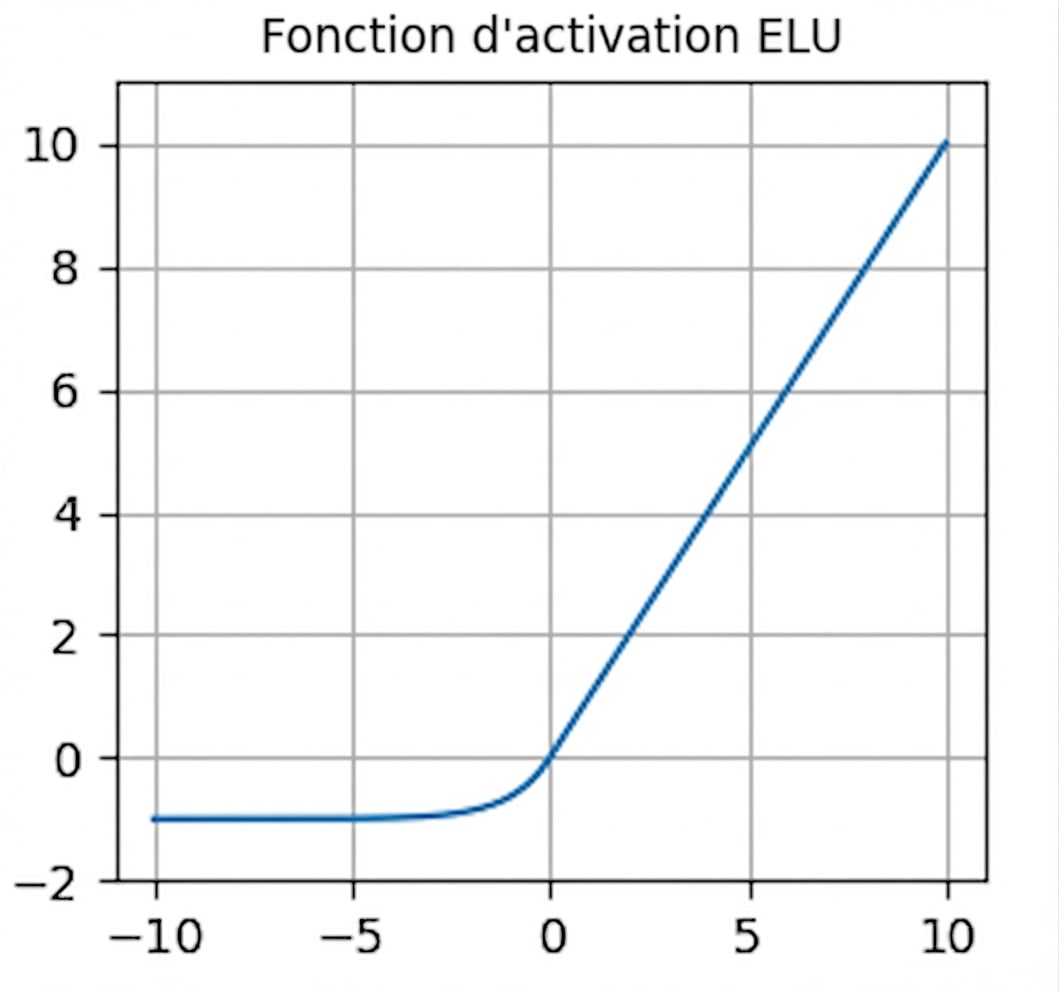
nn.functional.elu()- Gradients non nuls pour les valeurs négatives — évite les neurones « morts »
- Sortie moyenne proche de zéro — limite les gradients qui disparaissent

