Das Laden
Einführung in das Data Engineering

Vincent Vankrunkelsven
Data Engineer @ DataCamp
Datenbanken für Analyse oder für Anwendung
Analyse

- Aggregierte Abfragen
- Online-Analyseverarbeitung (OLAP)
Anwendungen

- Viele Transaktionen
- Online-Transaktionsverarbeitung (OLTP)
Spalten- und zeilenorientiert
Analyse
- Spaltenorientiert

- Abfragen zu Teilmengen von Spalten
- Parallelisierung
Anwendungen
- Zeilenorientiert
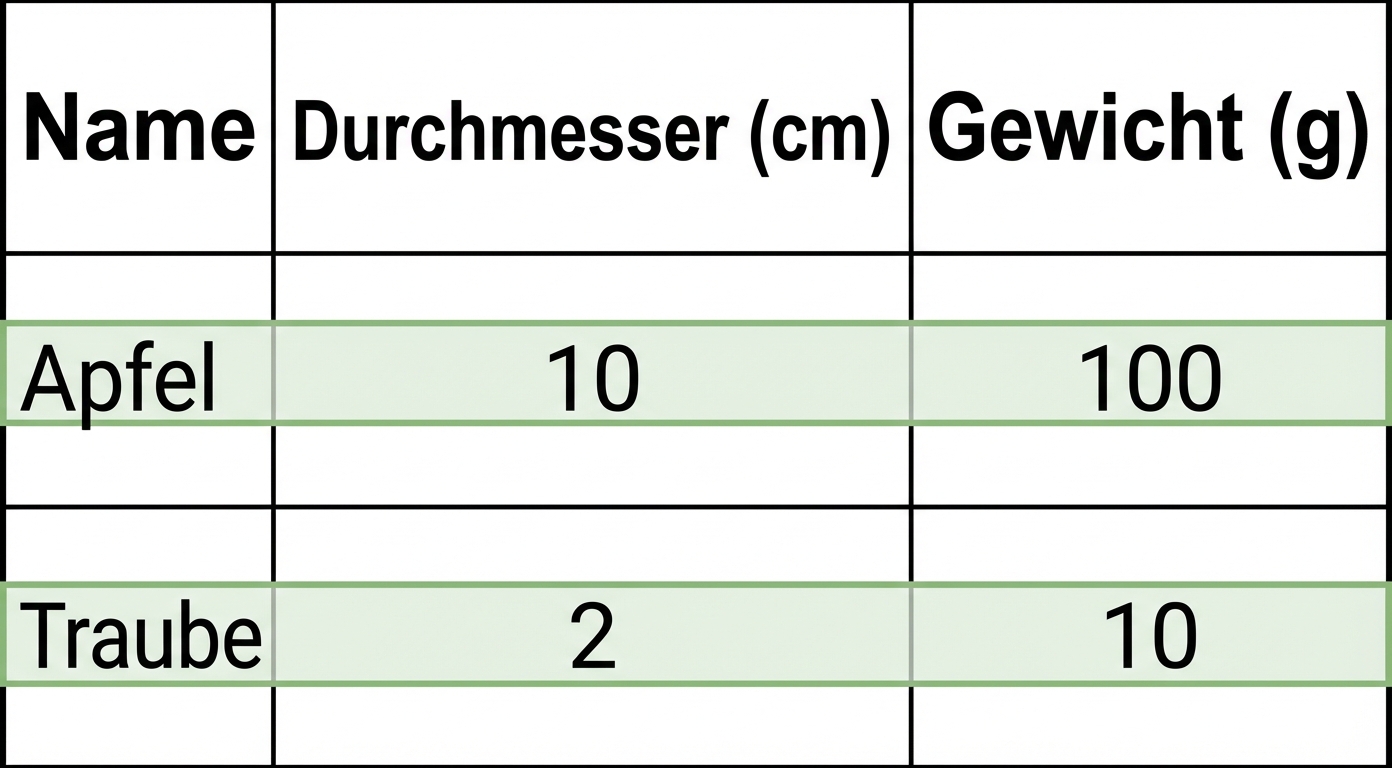
- Pro Datensatz gespeichert
- Pro Transaktion hinzugefügt
- z.B. schnelles Hinzufügen von Kunden
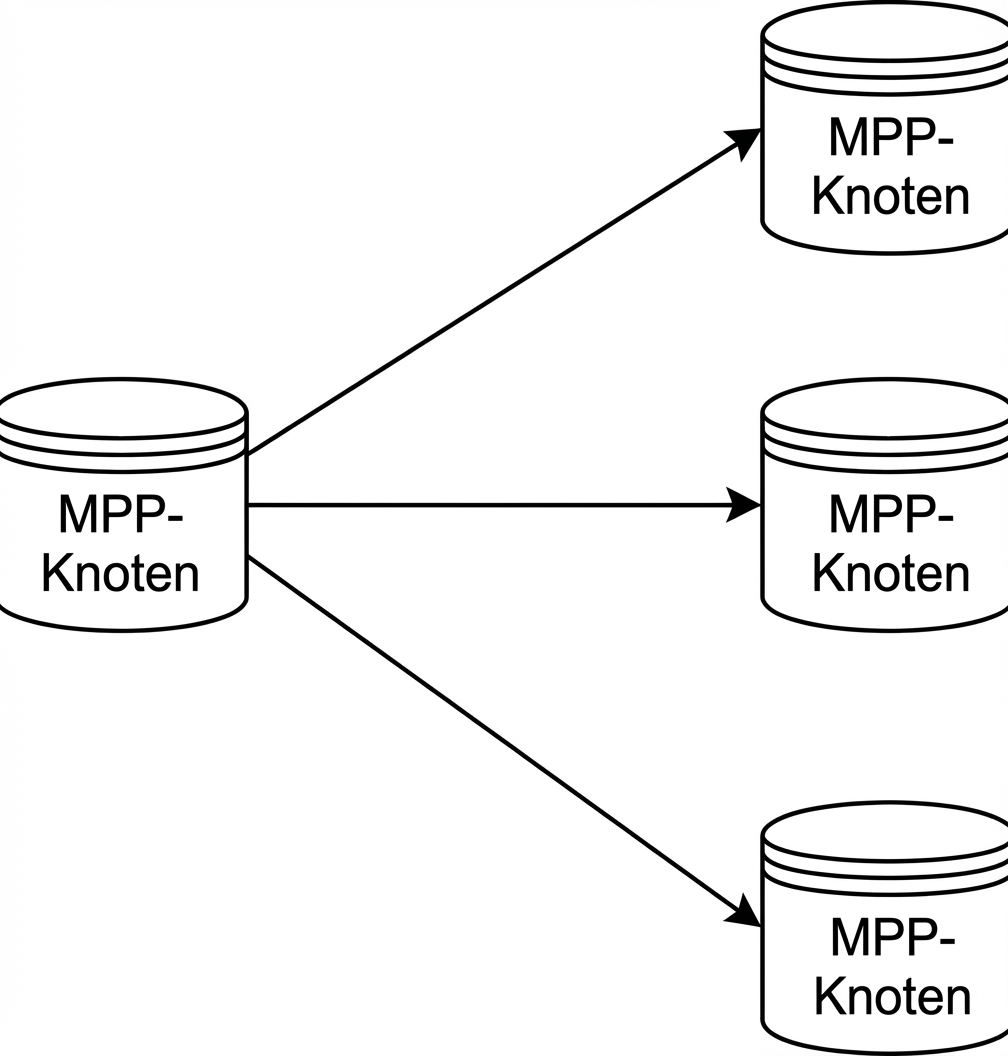
MPP-Datenbanken
Massively Parallel Processing Databases