Tools des Dateningenieurs
Einführung in das Data Engineering

Vincent Vankrunkelsven
Data Engineer @ DataCamp
Datenbanken


Verarbeitung
Datenplanung
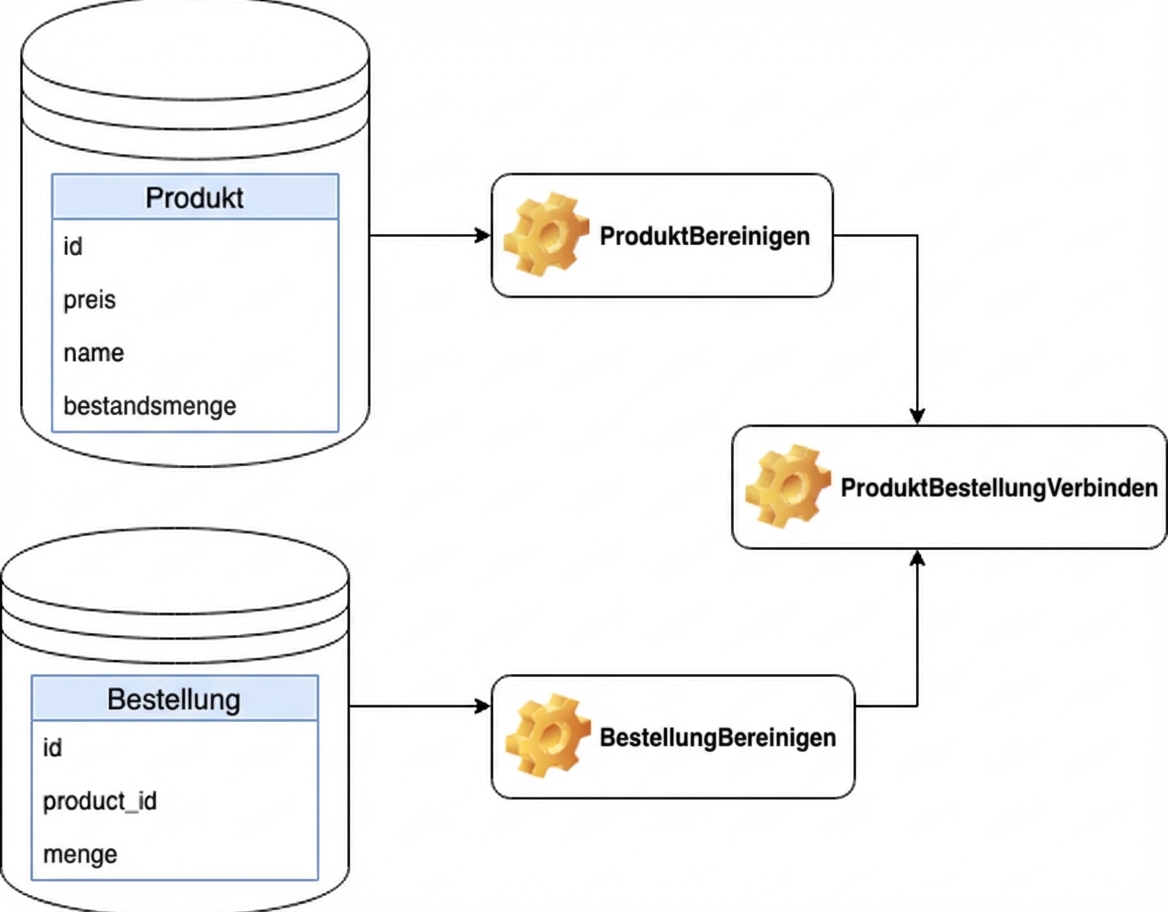
JoinProductOrder muss nach CleanProduct und CleanOrder laufen
Bereits vorhandene Tools
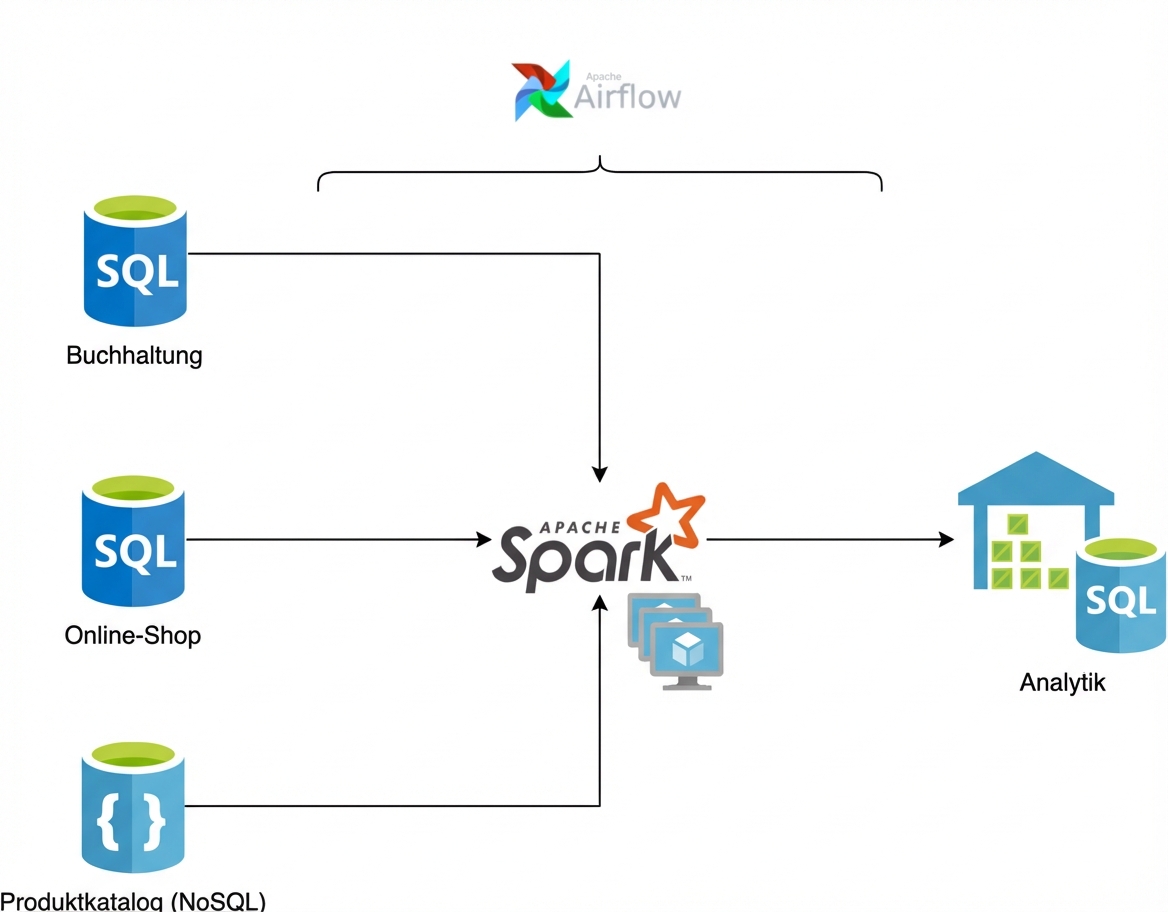
Datenbanken


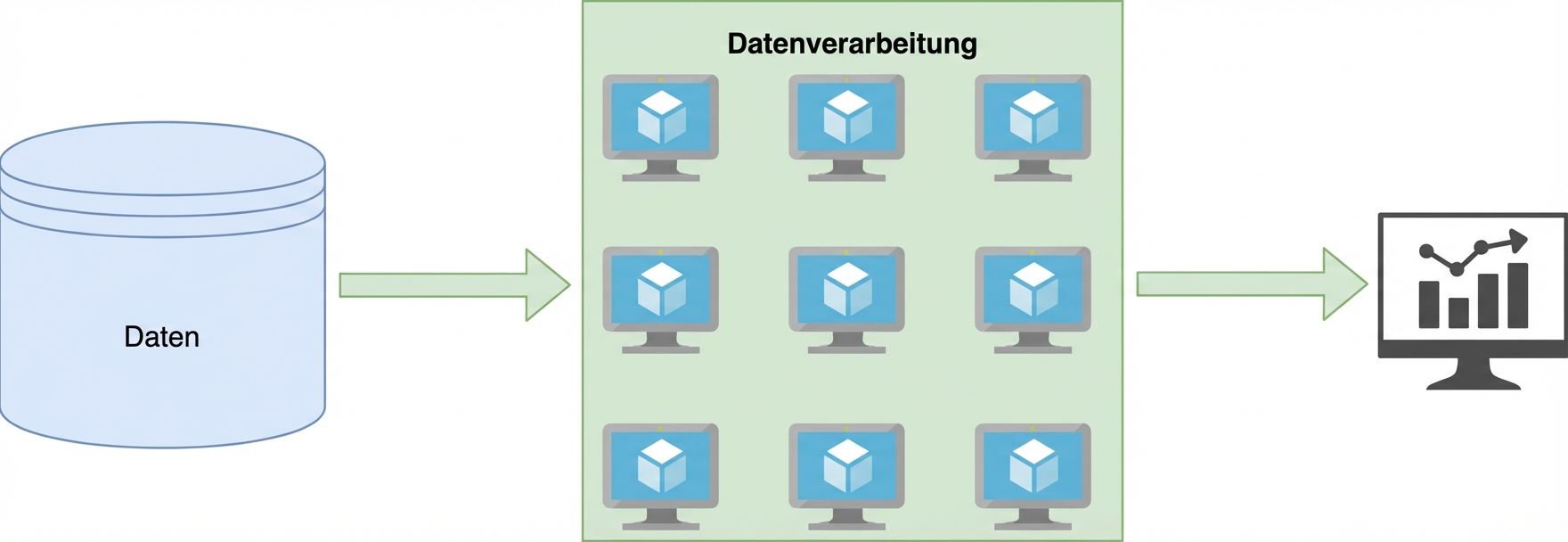
Verarbeitung
![]()
![]()
Datenplanung
![]()
![]()

Ein Datenverarbeitungsworkflow