Frameworks des parallelen Rechnens
Einführung in das Data Engineering

Vincent Vankrunkelsven
Data Engineer @ DataCamp
![]()
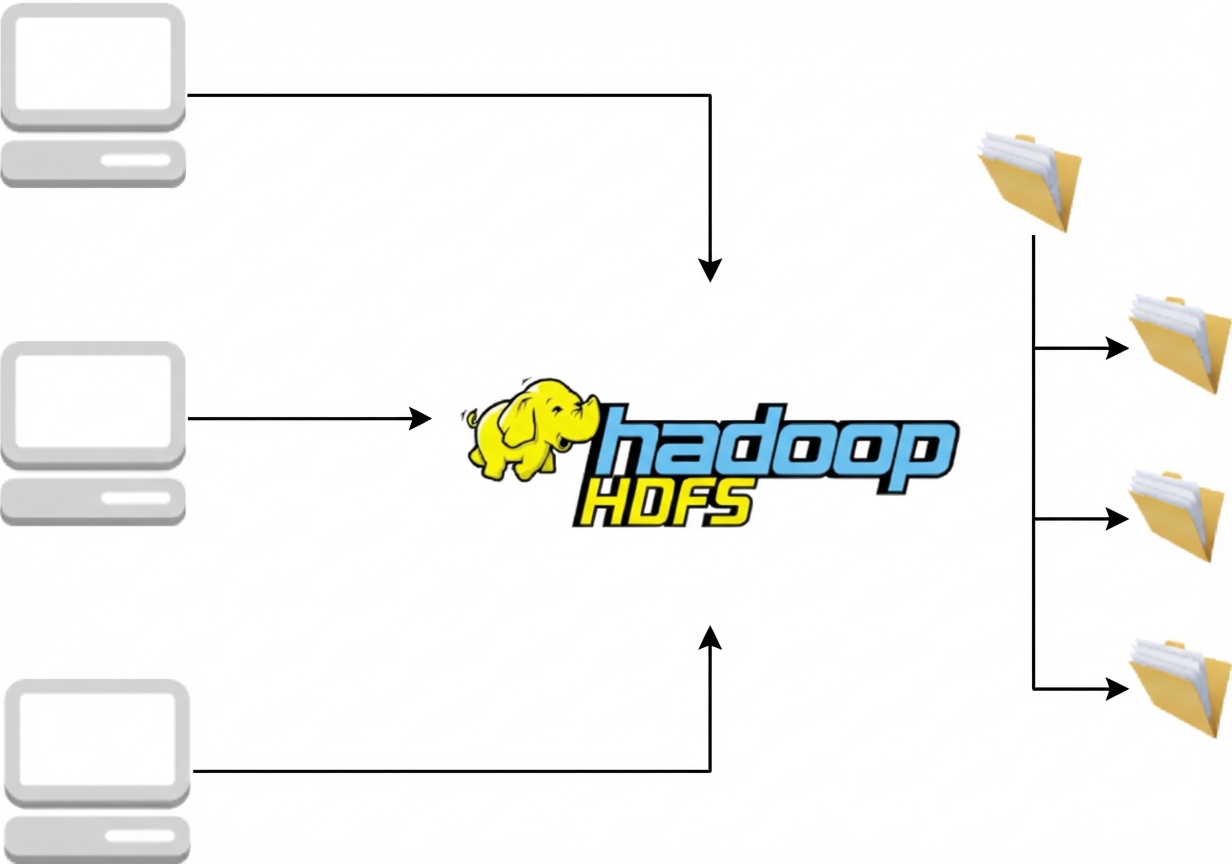
HDFS
MapReduce
![]()

Hive
- Läuft auf Hadoop
- Structured Query Language (strukturierte Abfragesprache): Hive SQL
- Anfangs MapReduce, jetzt andere Tools
![]()
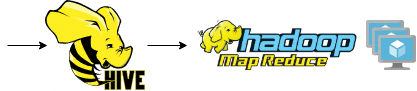
Hive: ein Beispiel
![]()
- Vermeidet Schreibvorgänge auf die Festplatte
- Betreut von der Apache Software Foundation

