Optimizing AI for speed, cost and quality
AI-Assisted Coding for Developers

Francesca Donadoni
AI Curriculum Manager, DataCamp
Metrics

Metrics

Metrics

Model benchmarking
$$
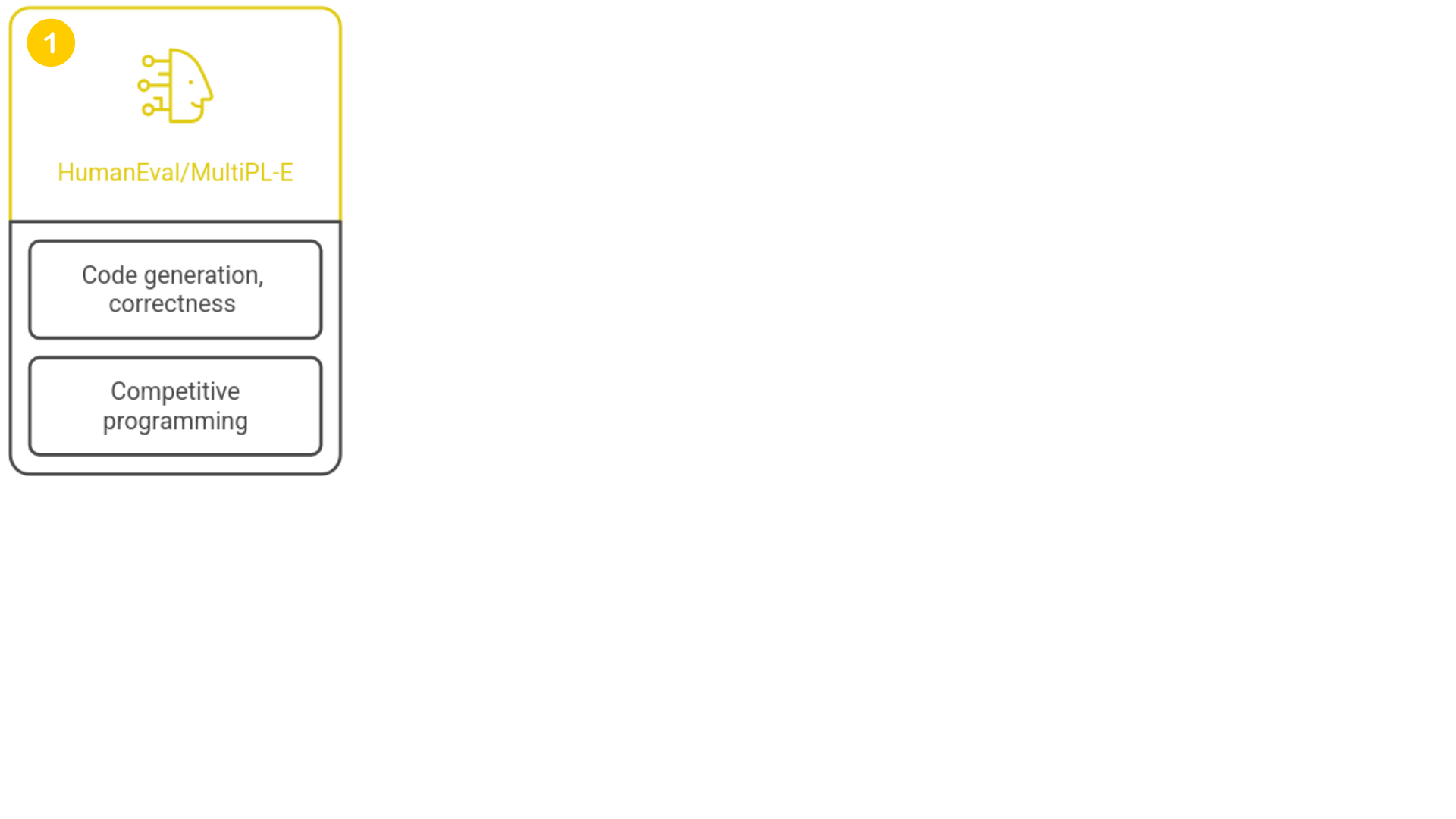
1 https://github.com/openai/human-eval
Model benchmarking
$$
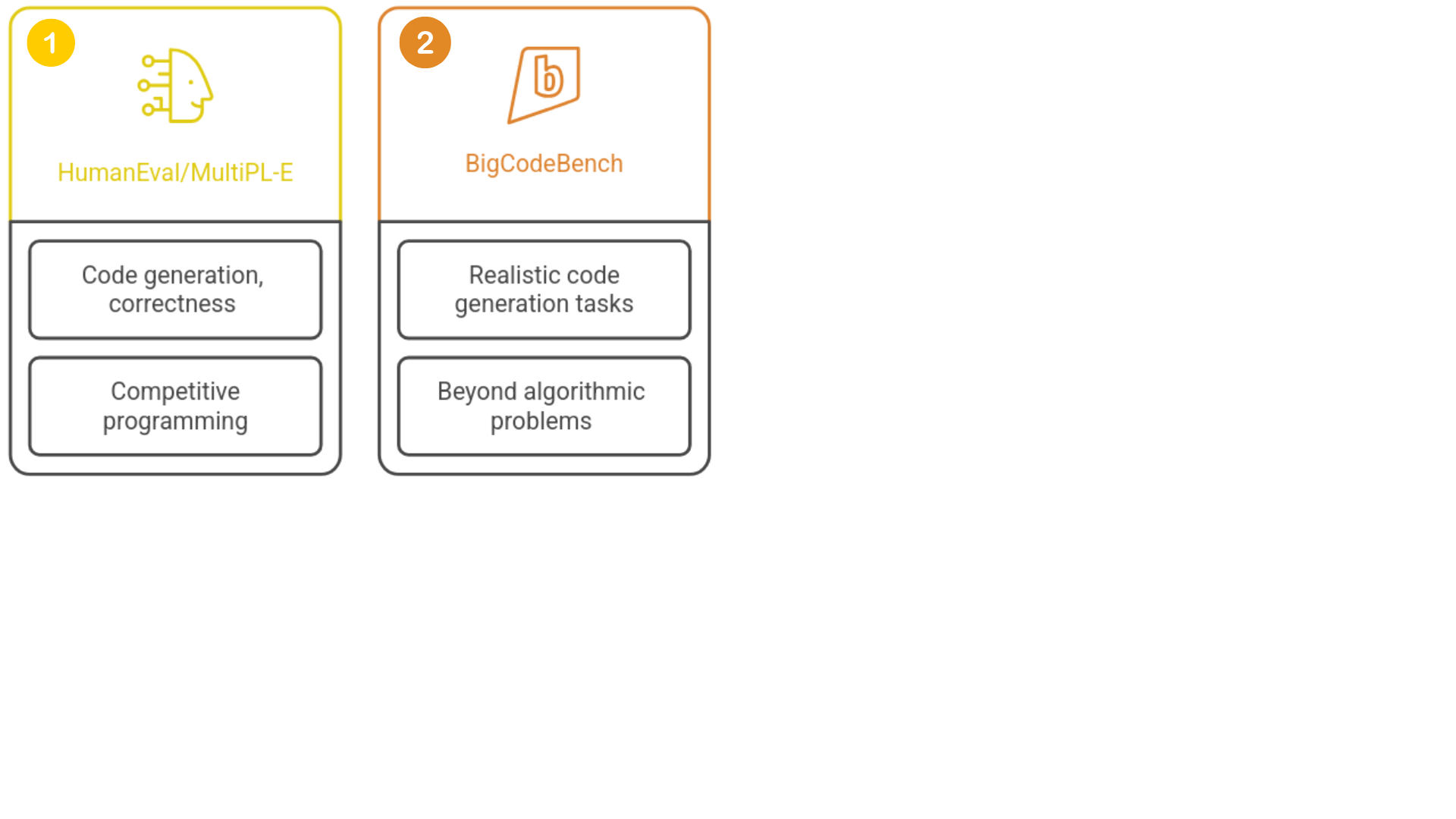
1 https://github.com/bigcode-project/bigcodebench
Model benchmarking
$$
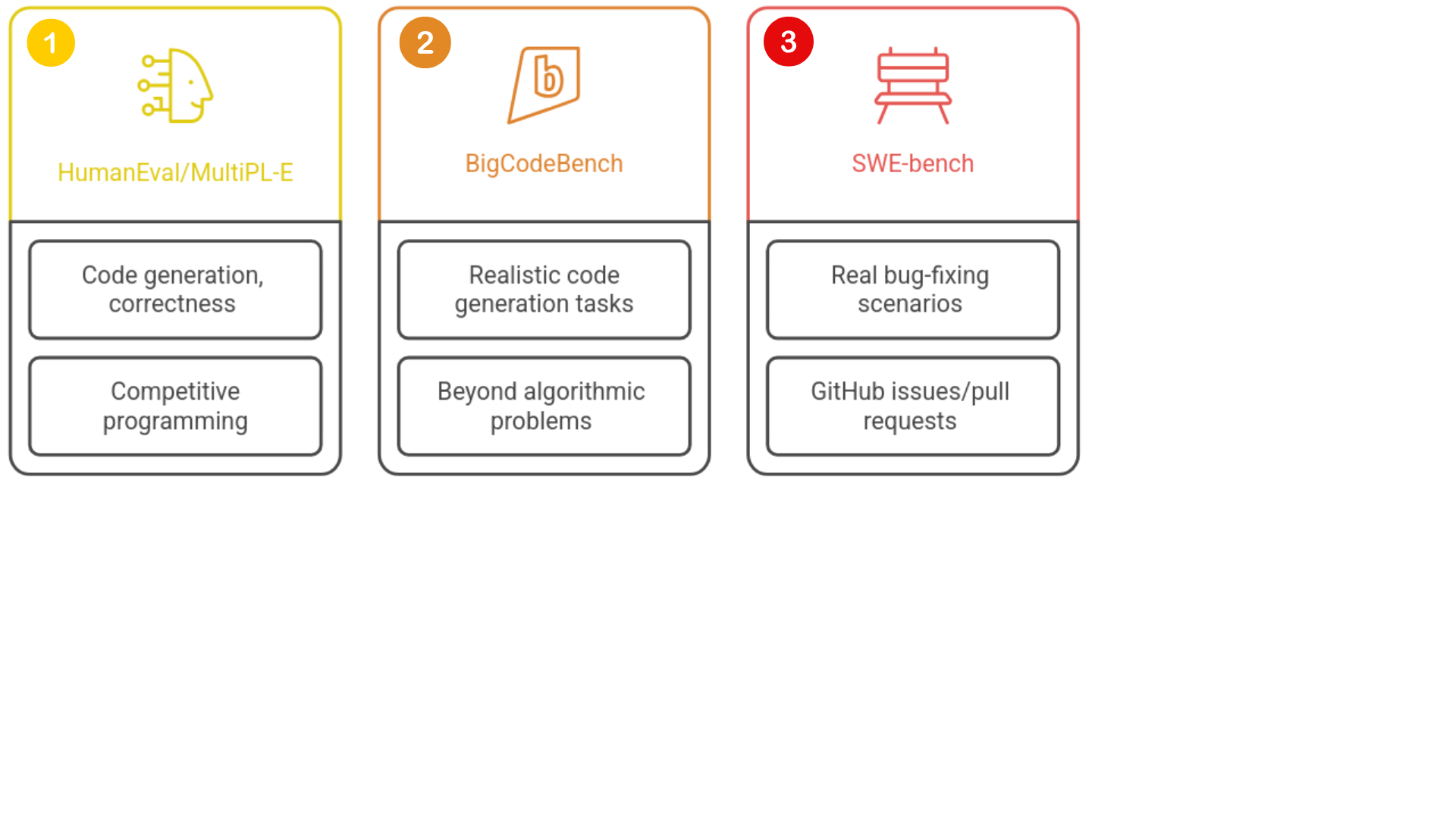
1 https://github.com/SWE-bench/SWE-bench
Model benchmarking
$$
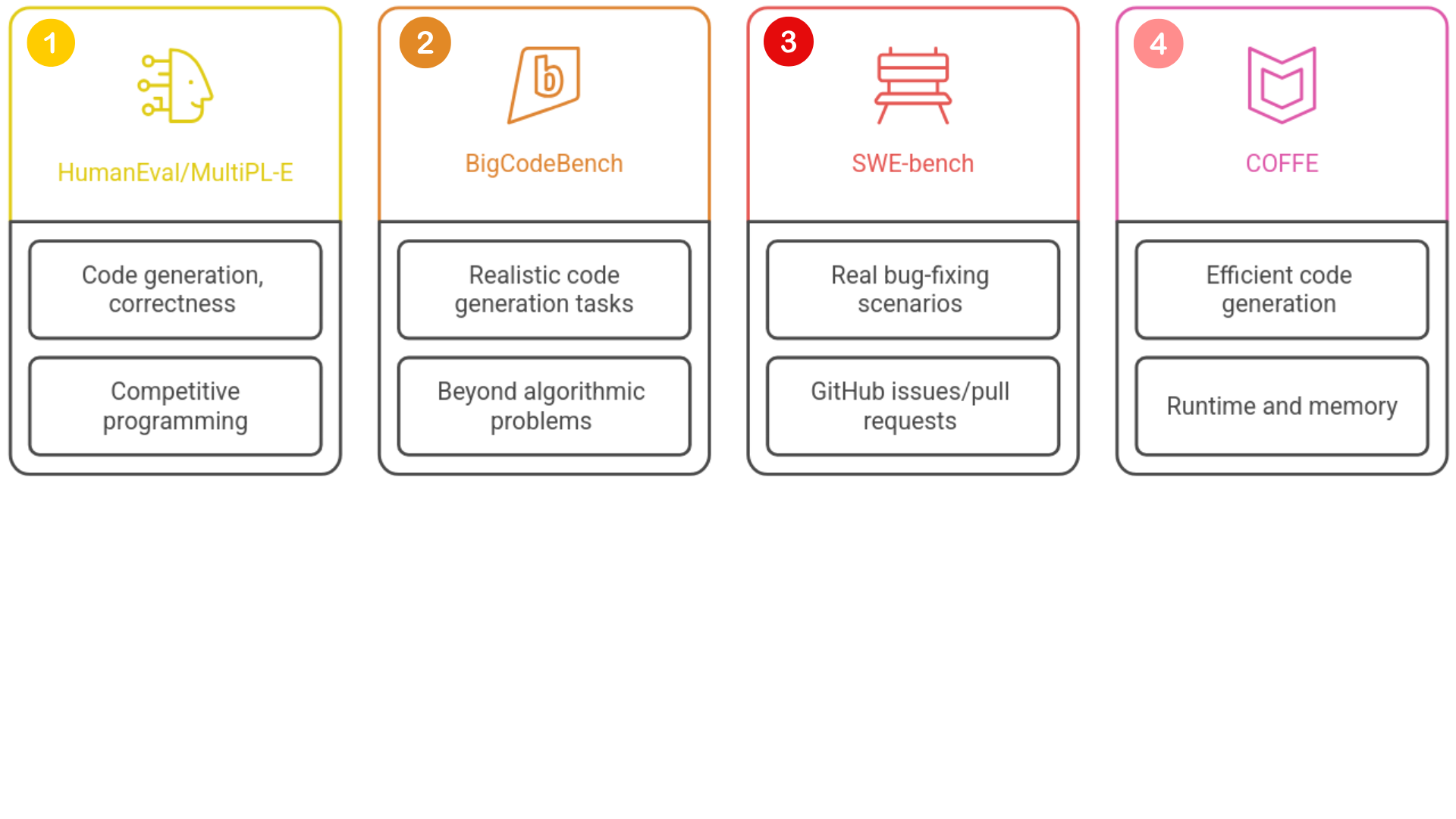
1 https://github.com/JohnnyPeng18/Coffe
Prompt versioning

Prompt versioning
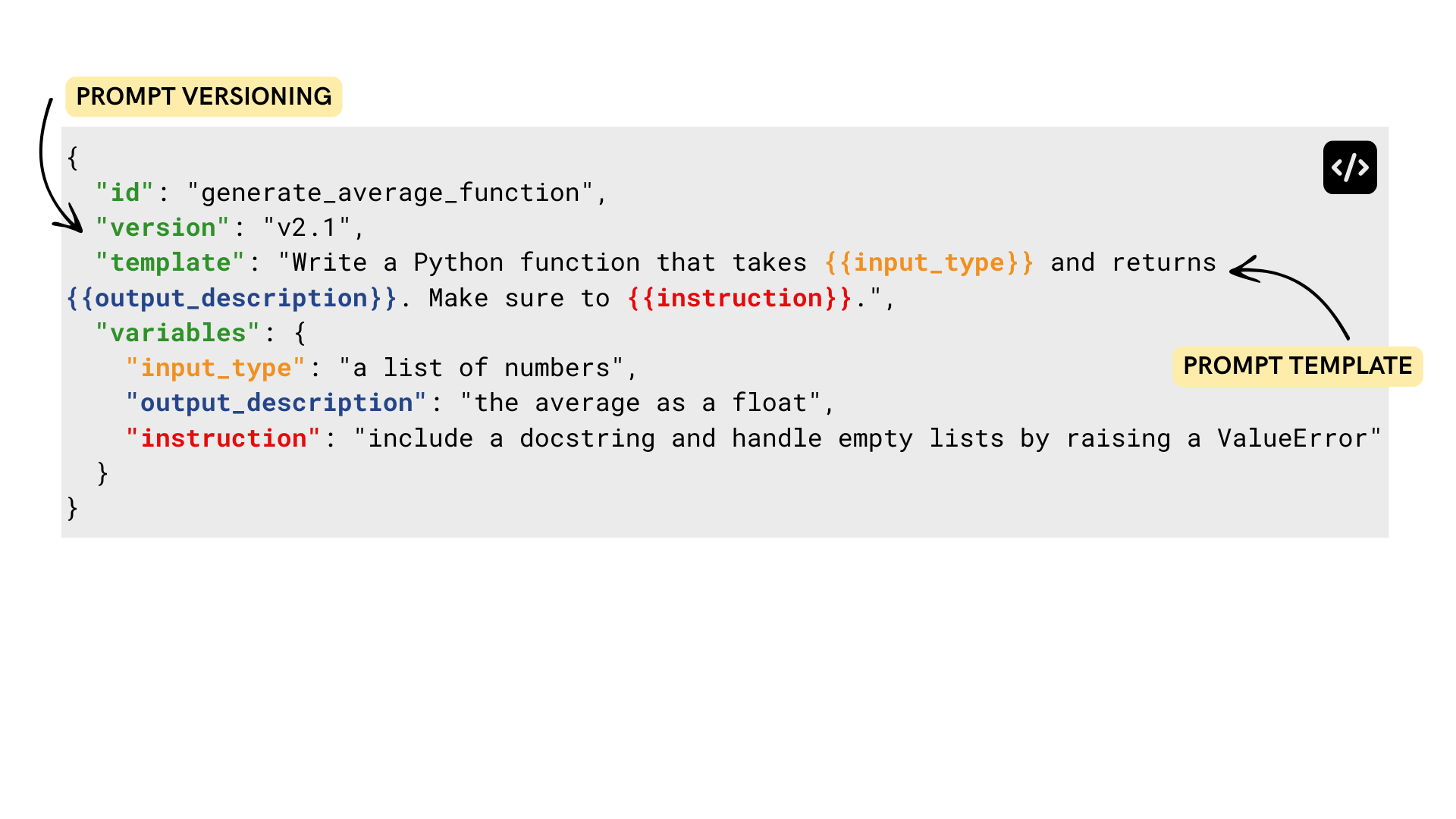
Prompt versioning

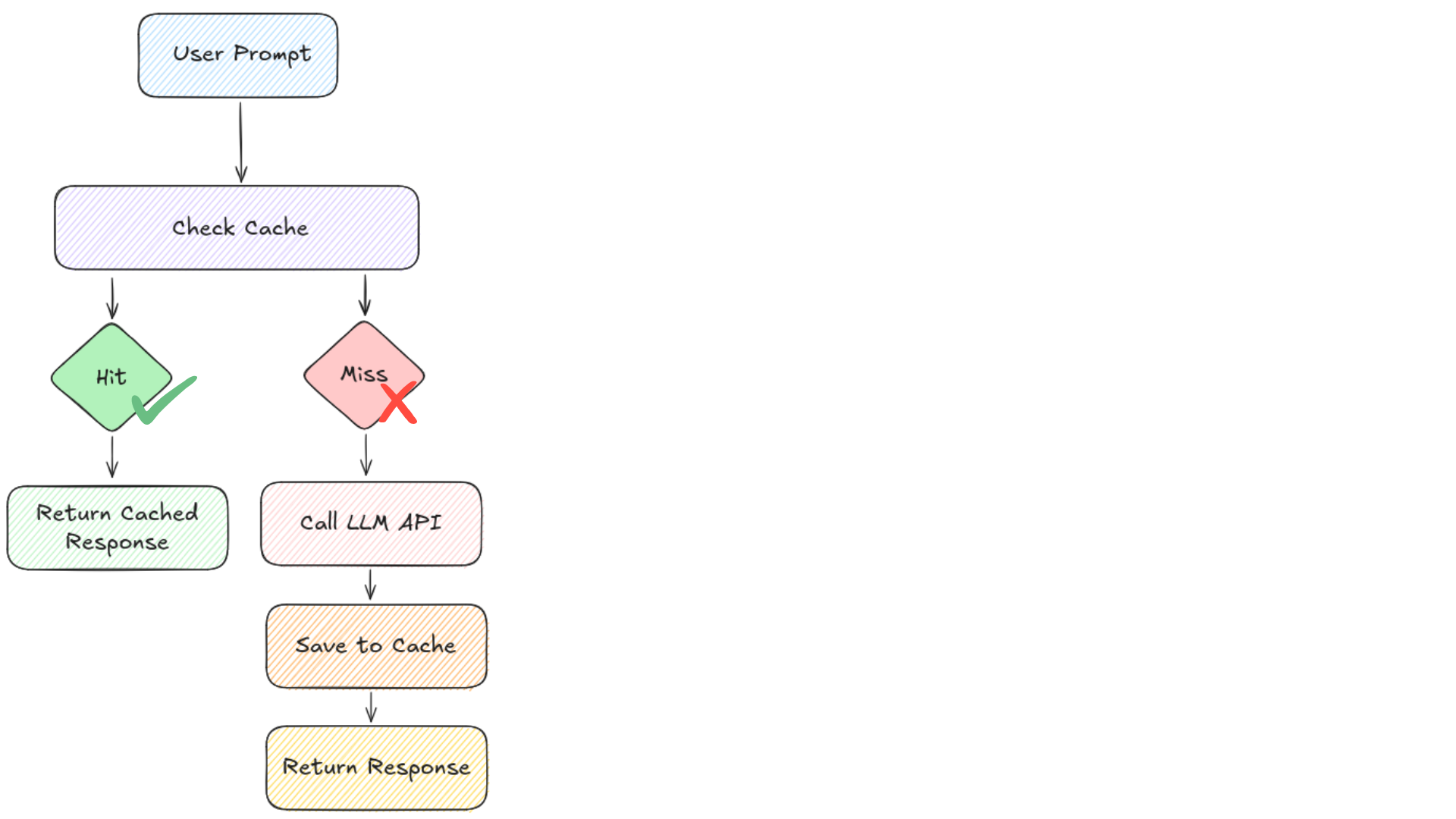
Prompt caching