Multi-modal sentiment analysis
Multi-Modal Models with Hugging Face

James Chapman
Curriculum Manager, DataCamp
Vision Language Models (VLMs)
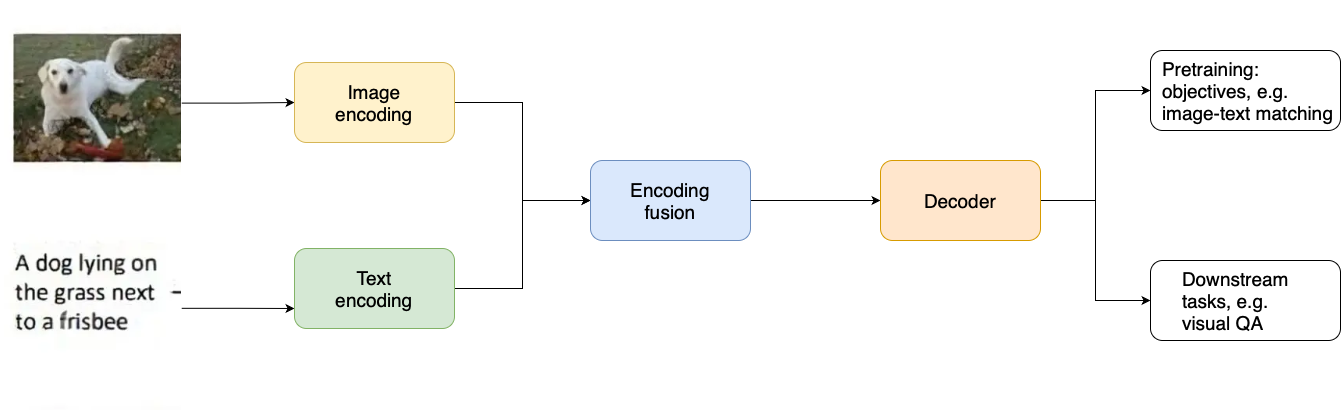
- Image and text separately encoded
- Feature fusion
- Create shared representations
- Multiple tasks from one model
Visual reasoning tasks
- VQA: Image + question → Direct answers about image content
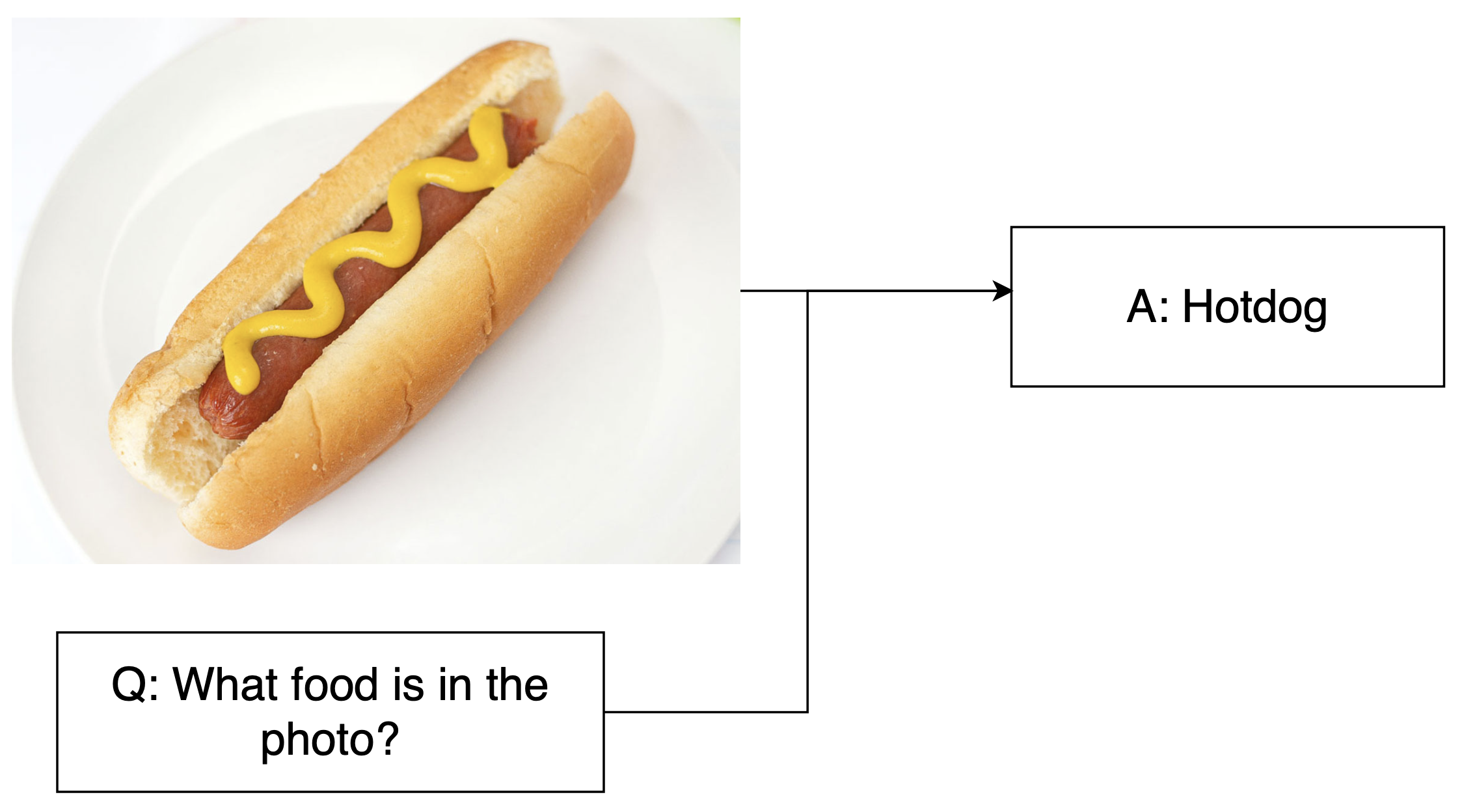
1 https://arxiv.org/pdf/1505.00468
Visual reasoning tasks
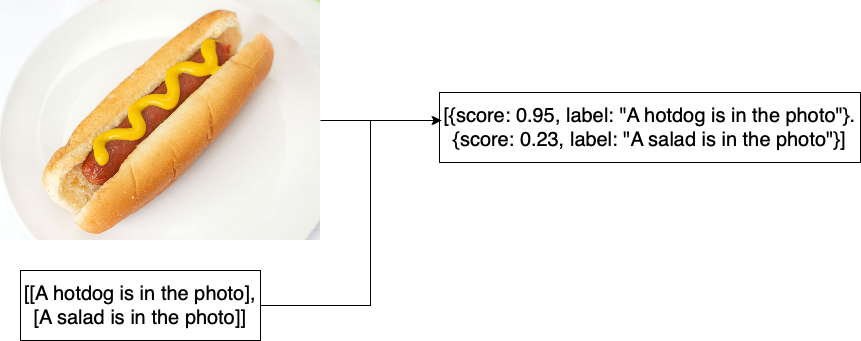
Visual reasoning tasks

Use case: share price impact


