Recherche sémantique avec Pinecone
Bases de données vectorielles pour les intégrations avec Pinecone

James Chapman
Curriculum Manager, DataCamp
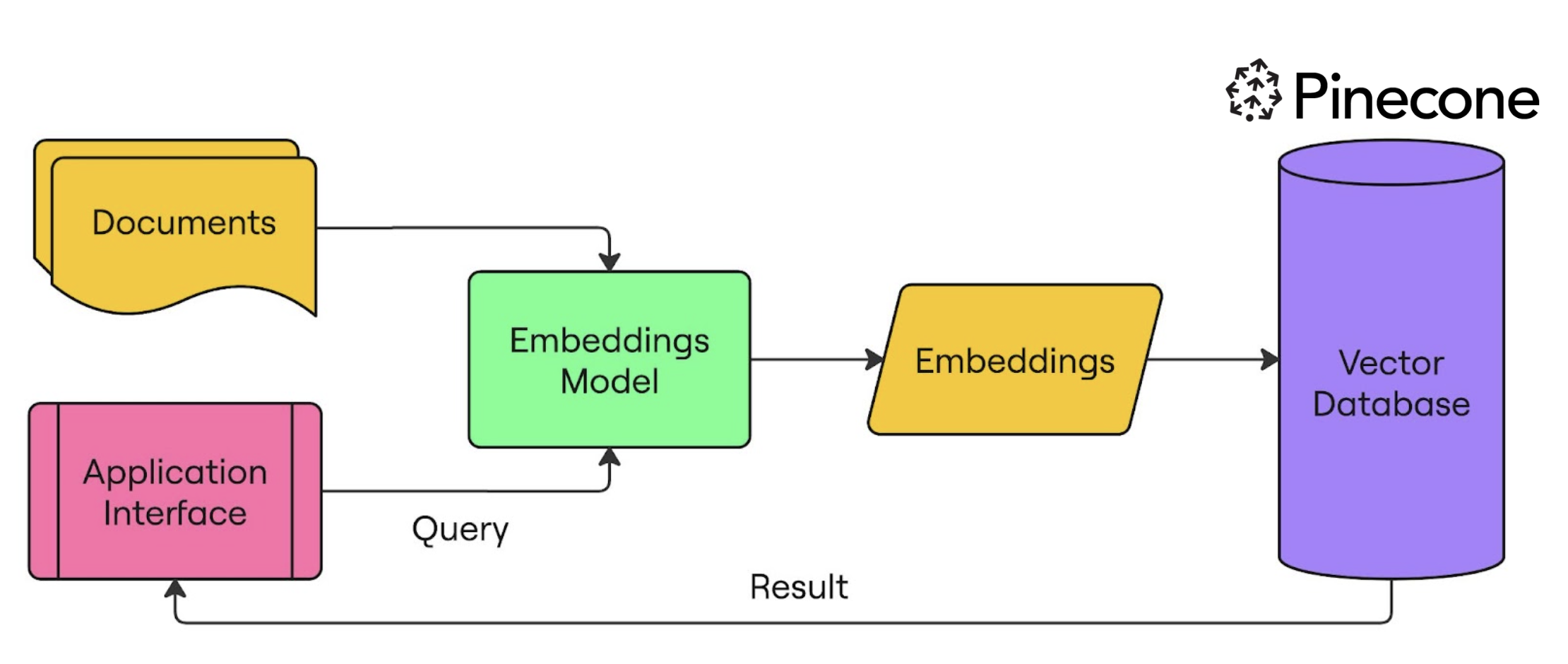
Moteurs de recherche sémantique
- Intégrer et ingérer des documents dans un index Pinecone
- Intégrer une requête utilisateur
- Interroger l’index avec la requête intégrée