Chatbot RAG avec Pinecone et OpenAI
Bases de données vectorielles pour les intégrations avec Pinecone

James Chapman
Curriculum Manager, DataCamp
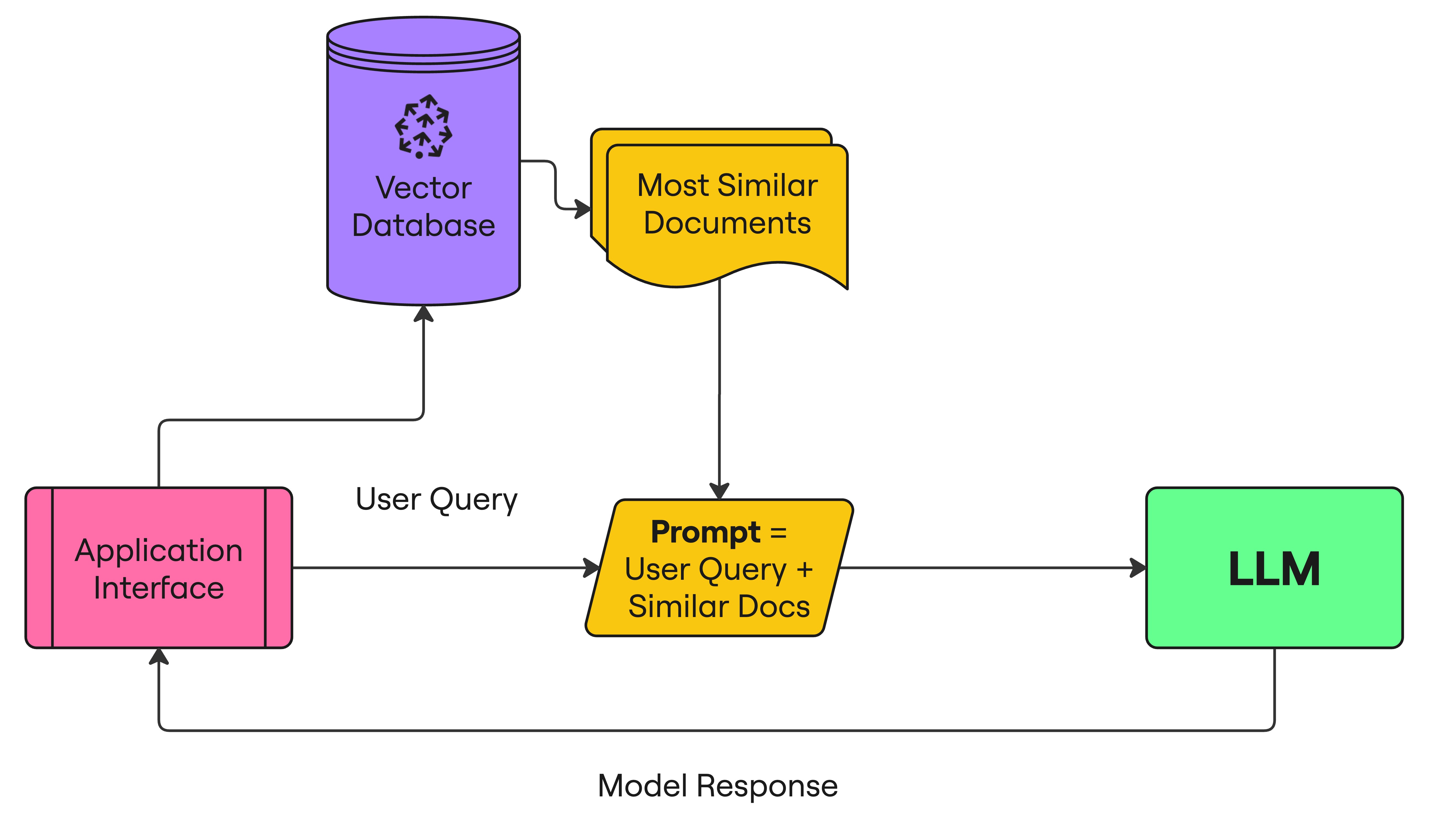
Retrieval Augmented Generation (RAG)
- Intégrer la requête utilisateur
- Récupérer des documents similaires
- Ajouter les documents à l’invite
Sortie de la construction d’invite avec contexte
query = "How to build next-level Q&A with OpenAI"
context_prompt = prompt_with_context_builder(query, documents)

Sortie des questions-réponses
query = "How to build next-level Q&A with OpenAI"
answer = question_answering(prompt_with_context, sources,
chat_model='gpt-4o-mini')