Regrouper les upserts
Bases de données vectorielles pour les intégrations avec Pinecone

James Chapman
Curriculum Manager, DataCamp
Limites d’upsert
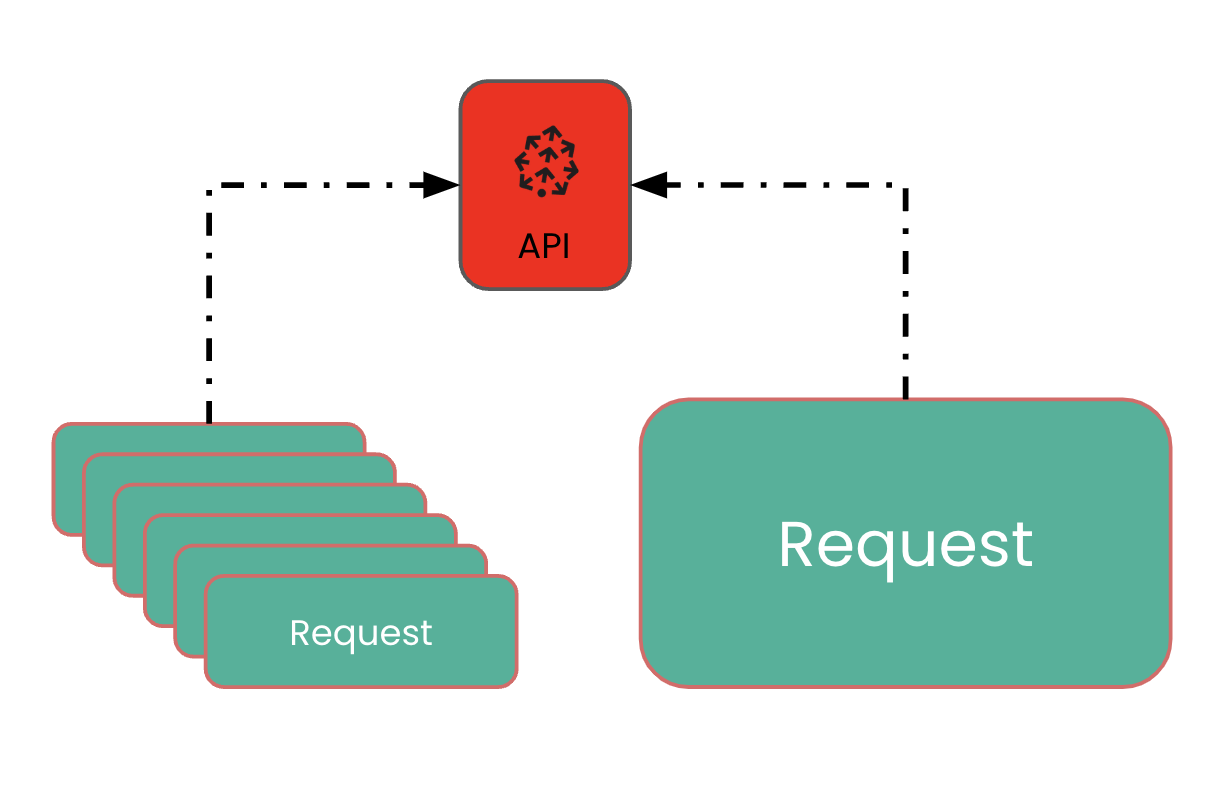
1 https://docs.pinecone.io/reference/quotas-and-limits#rate-limits
Bases de données vectorielles pour les intégrations avec Pinecone
James Chapman
Curriculum Manager, DataCamp

