Modelloptimierung verstehen
Einführung in Deep Learning mit Python

Dan Becker
Data Scientist and contributor to Keras and TensorFlow libraries
Das Problem sterbender Neuronen
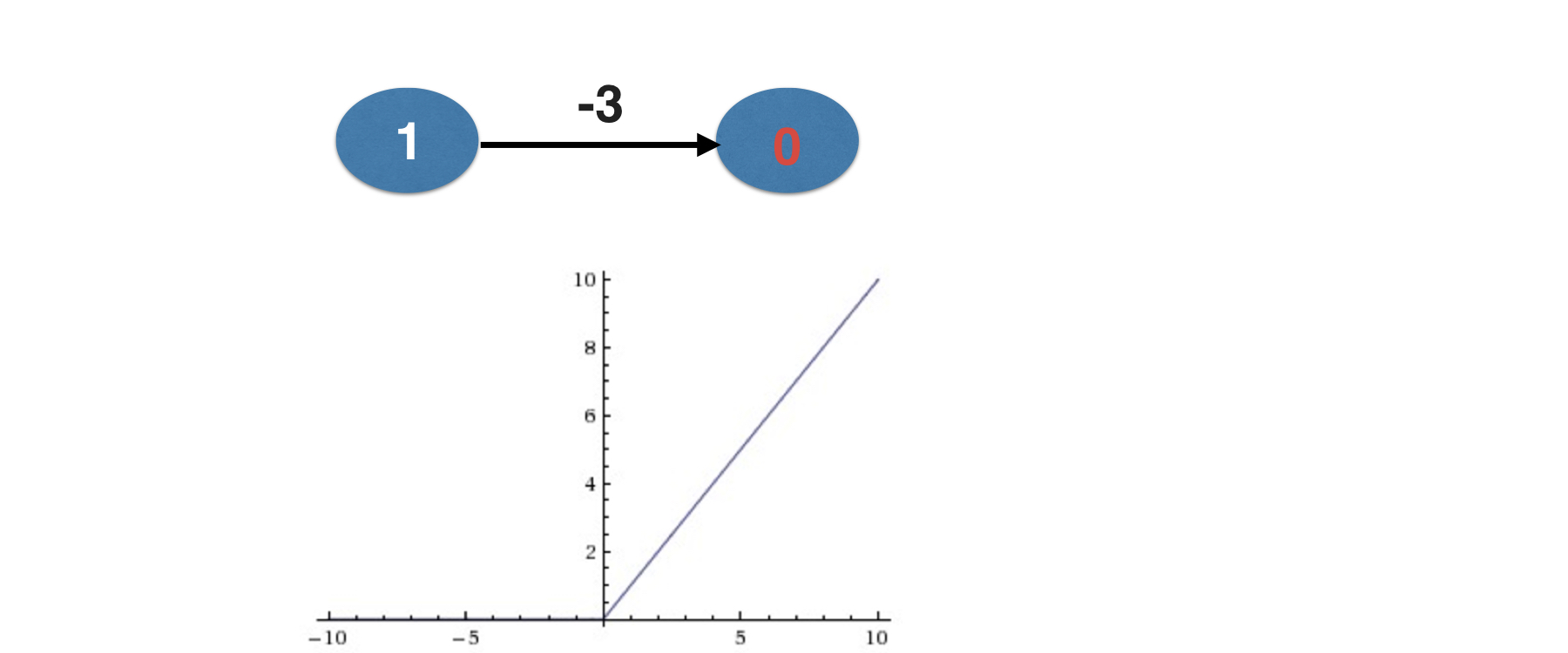
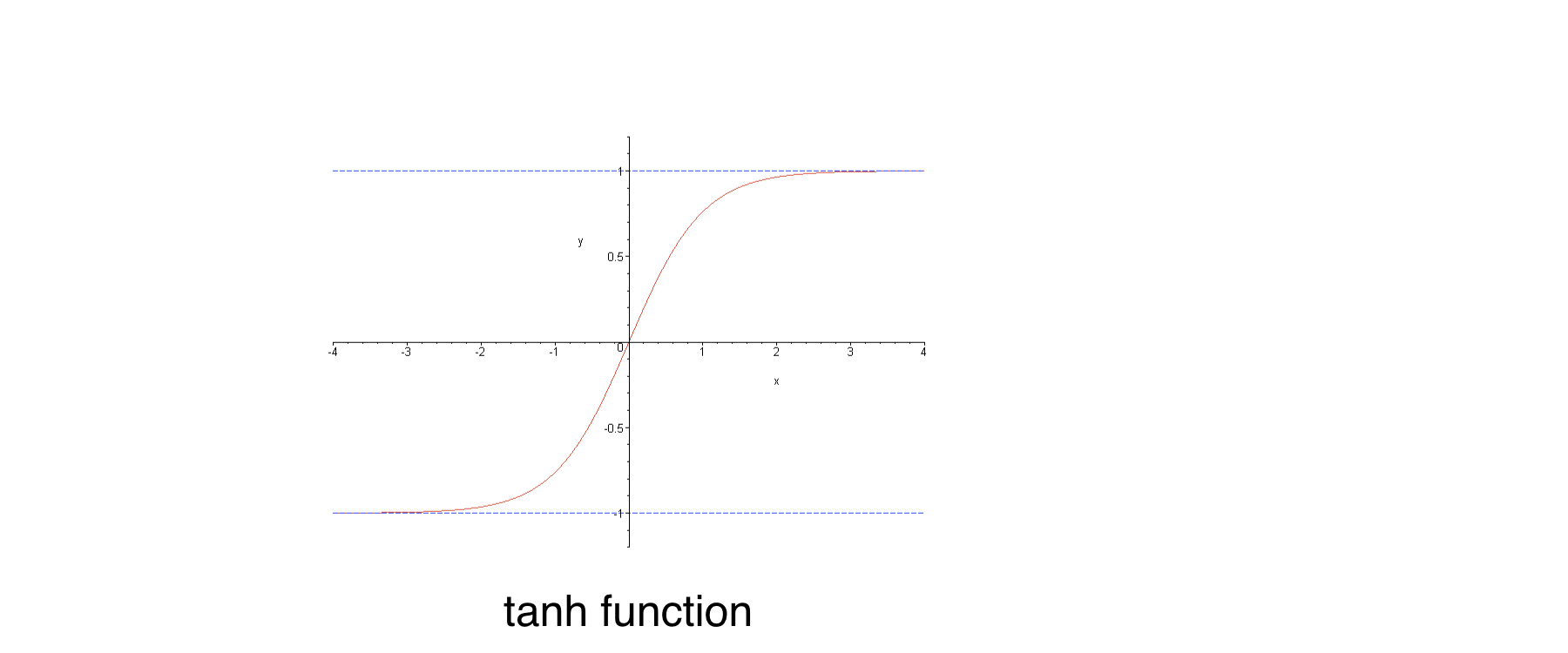
Verschwindende Gradienten
Einführung in Deep Learning mit Python
Dan Becker
Data Scientist and contributor to Keras and TensorFlow libraries

