Neural Machine Translation
Recurrent Neural Networks (RNNs) for Language Modeling with Keras

David Cecchini
Data Scientist
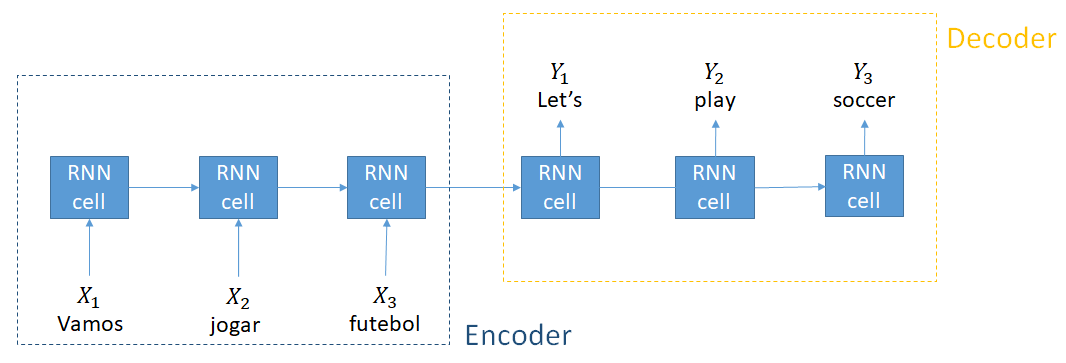
Encoder and decoders
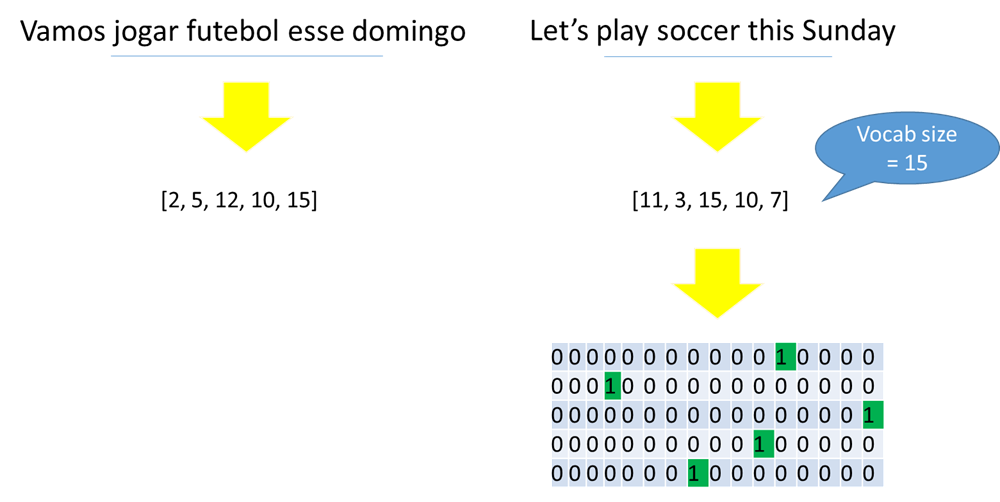
Data prep
Recurrent Neural Networks (RNNs) for Language Modeling with Keras
David Cecchini
Data Scientist

