Working with Databricks notebooks
Data Transformation with Spark SQL in Databricks

Disha Mukherjee
Lead Data Engineer
Your instructor

$$

$$
$$
- Will apply skills inside Databricks 🧱
$$

What to expect

What is Databricks?
- Provides tools for engineering and analytics 📊
- Handles provisioning and scaling for us 🔄
Clusters and Spark
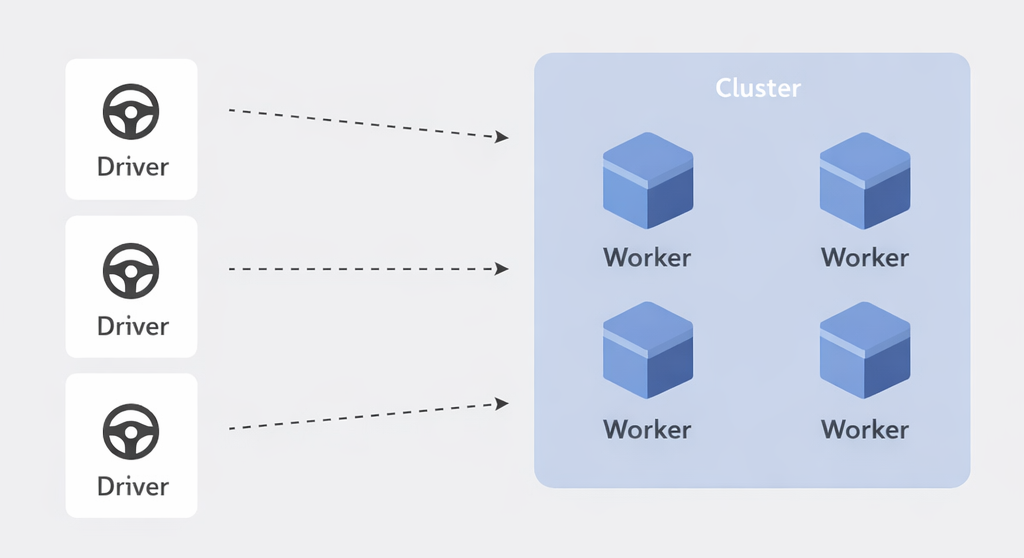
- Spark handles large datasets efficiently 🚀
- Exercises use serverless compute - same architecture, no setup
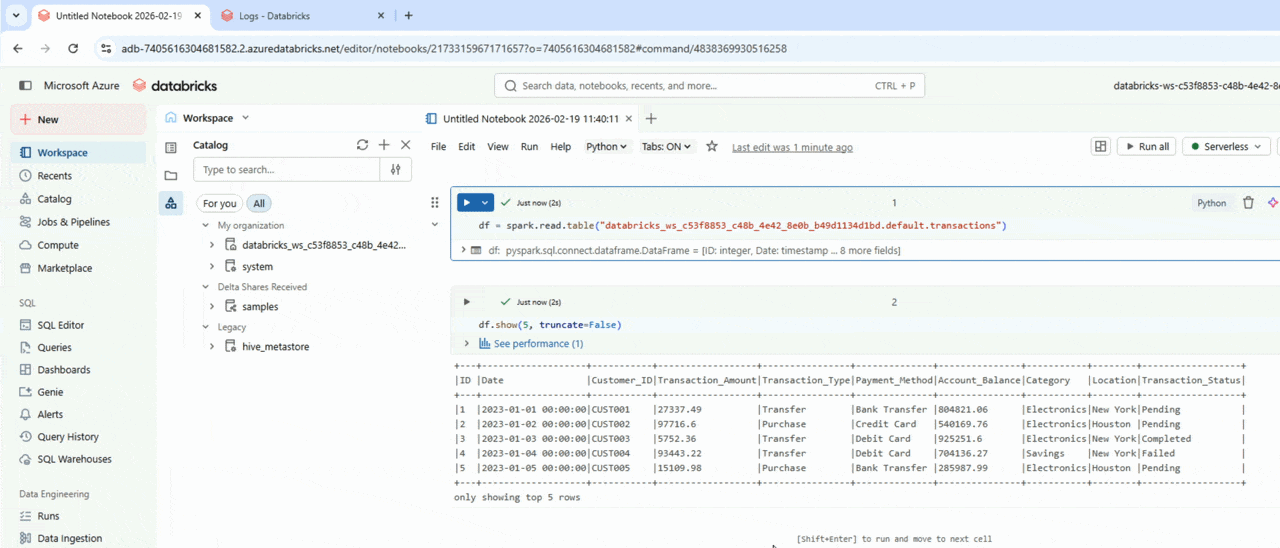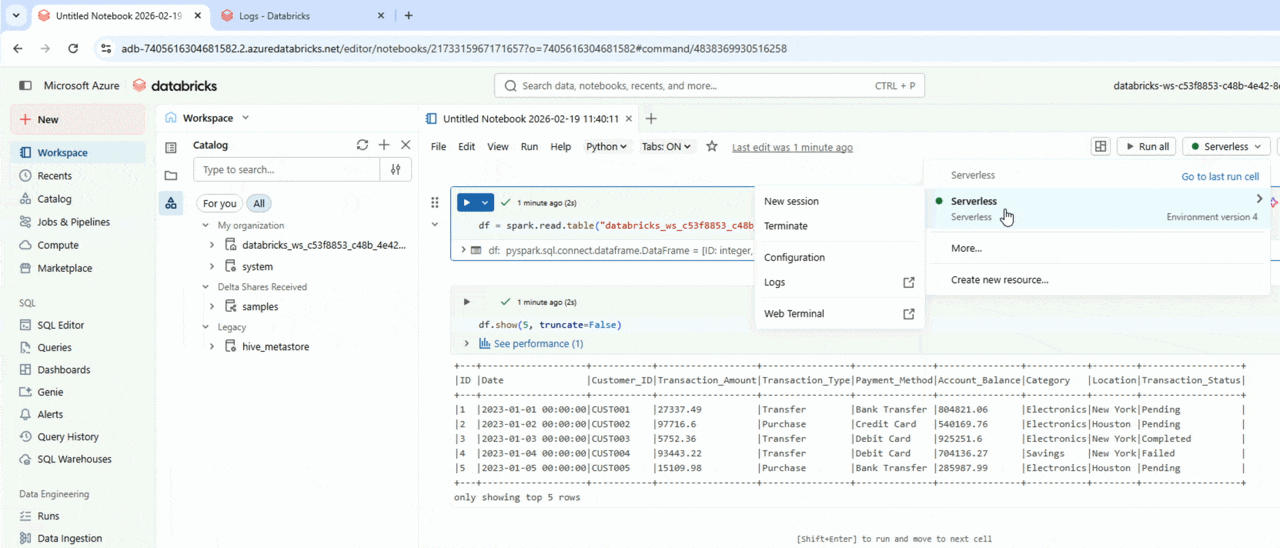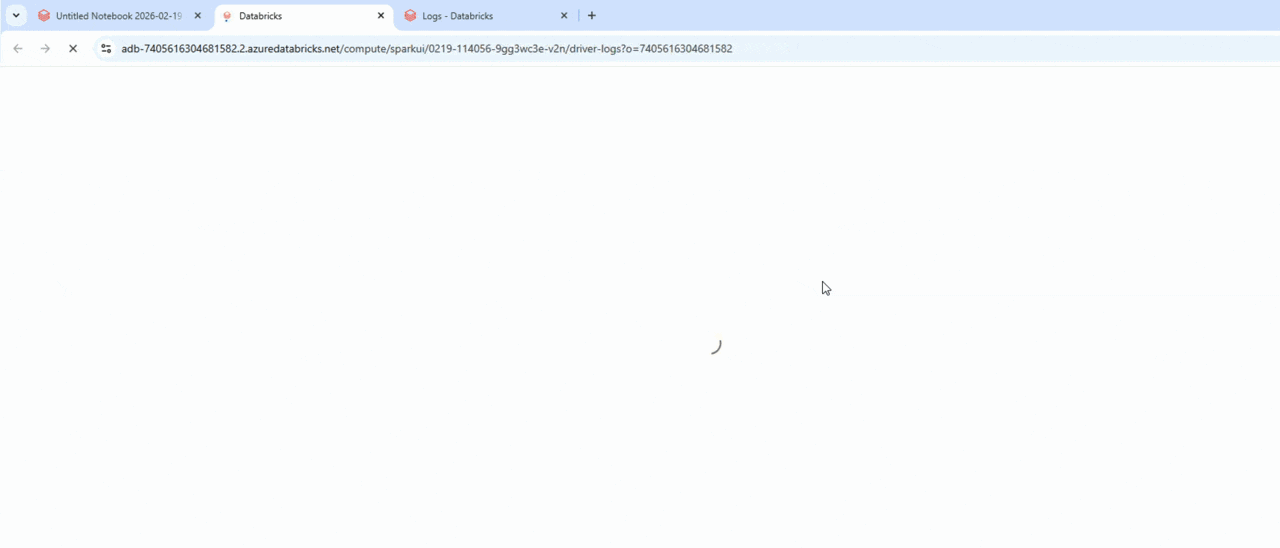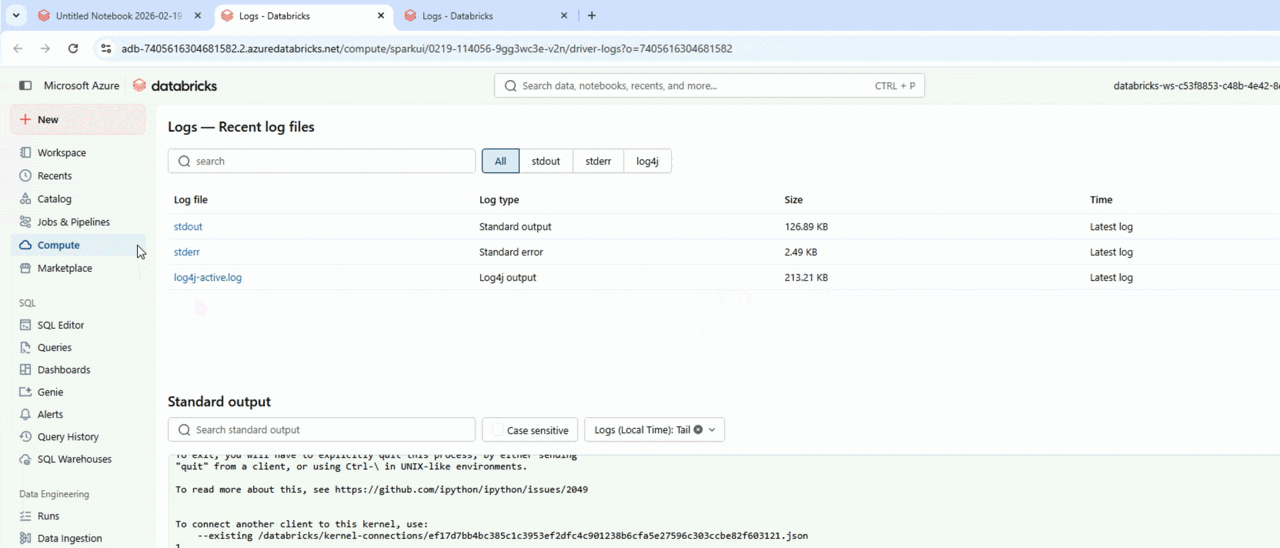
Databricks notebooks
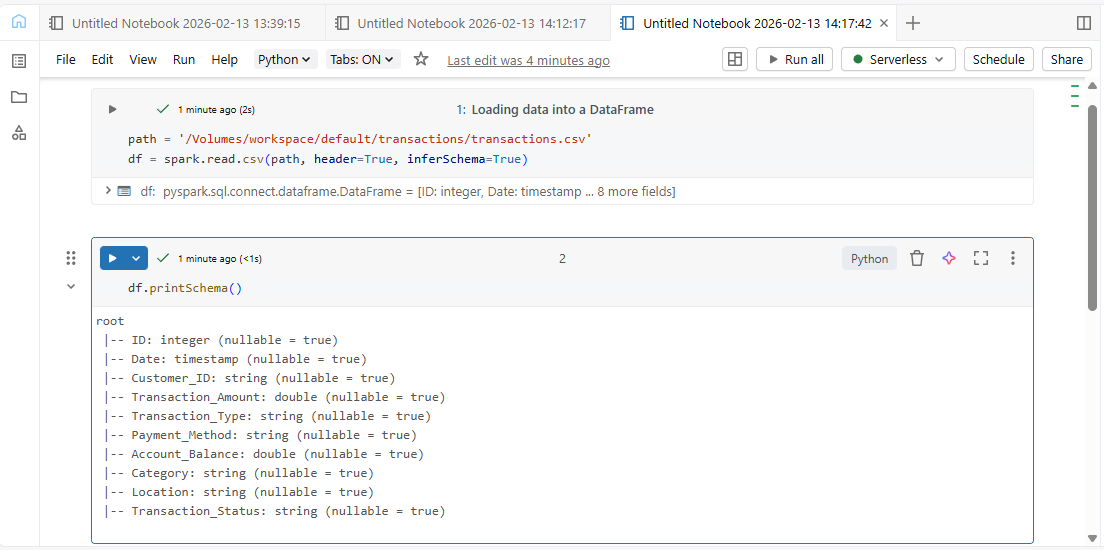
Dataset introduction
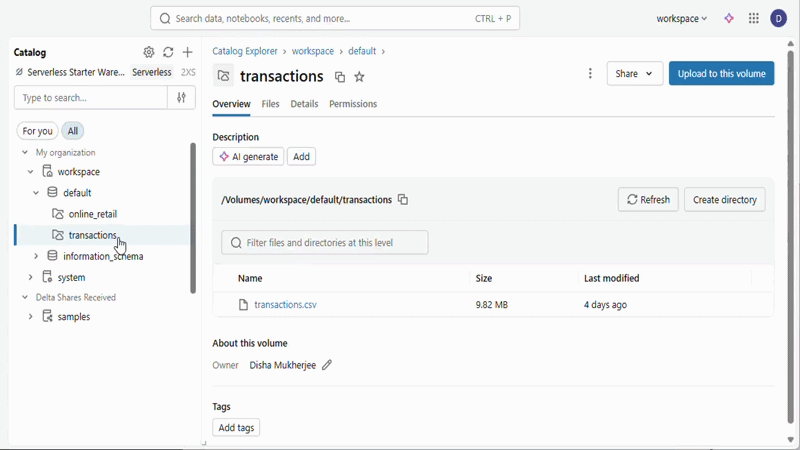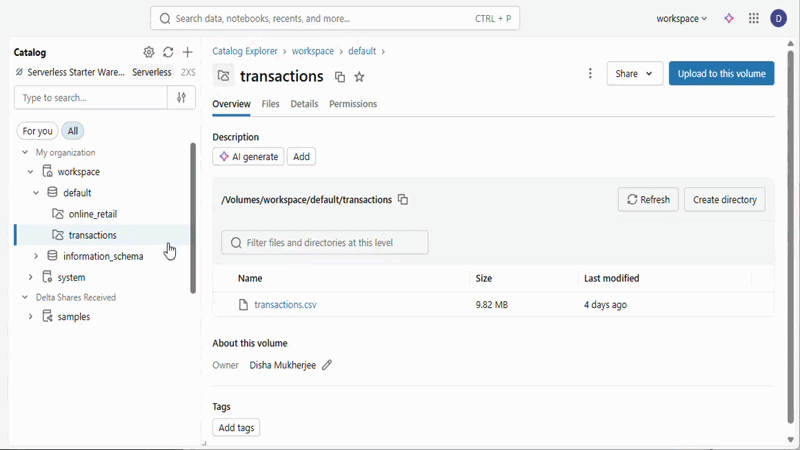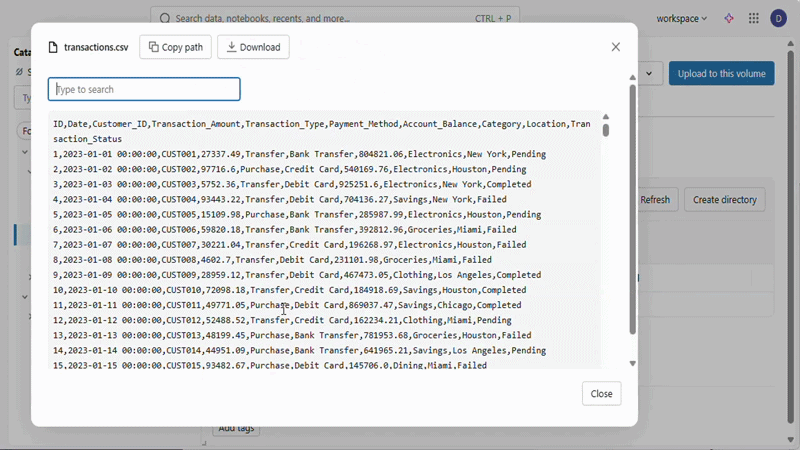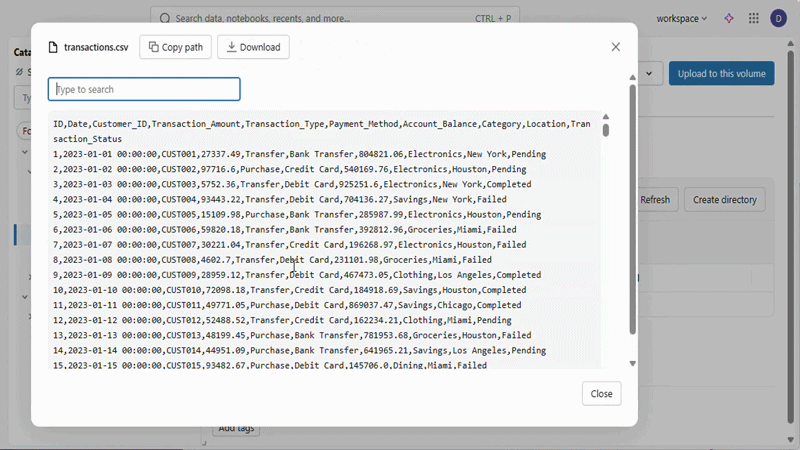
Unity Catalog Volumes
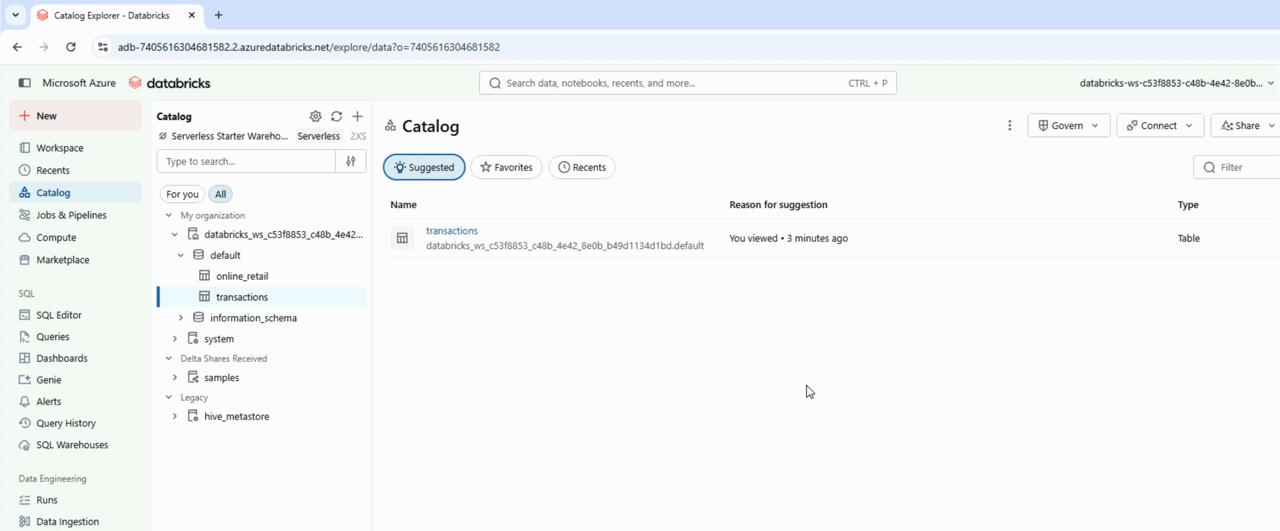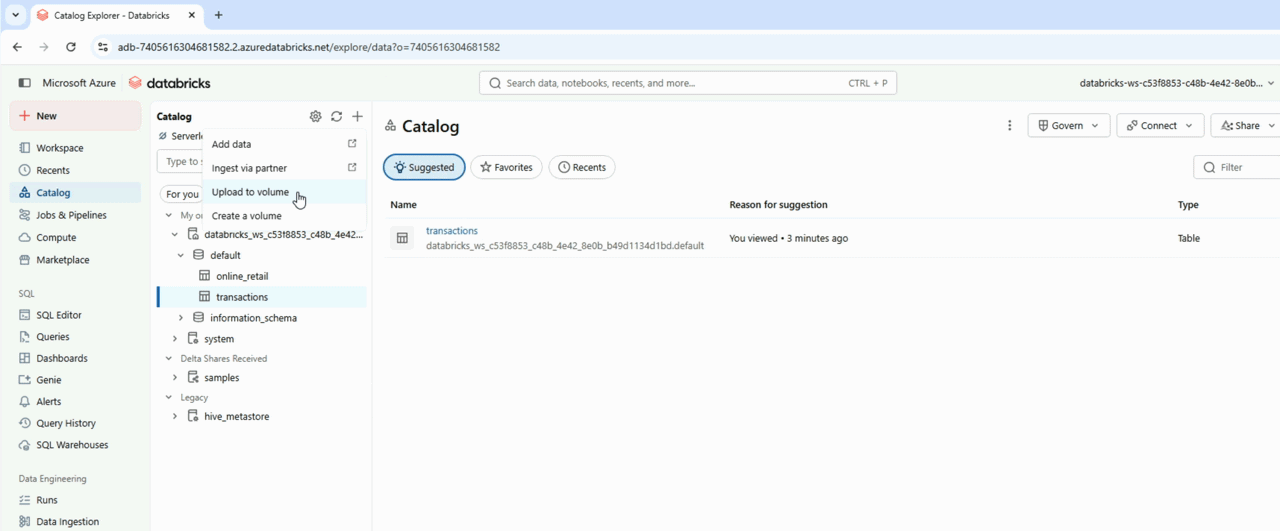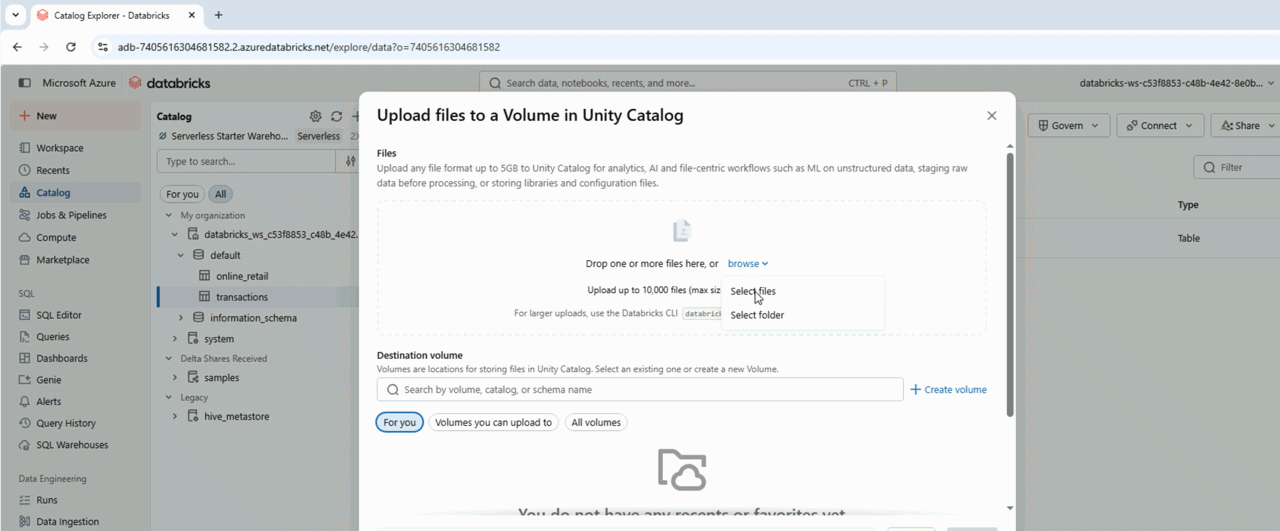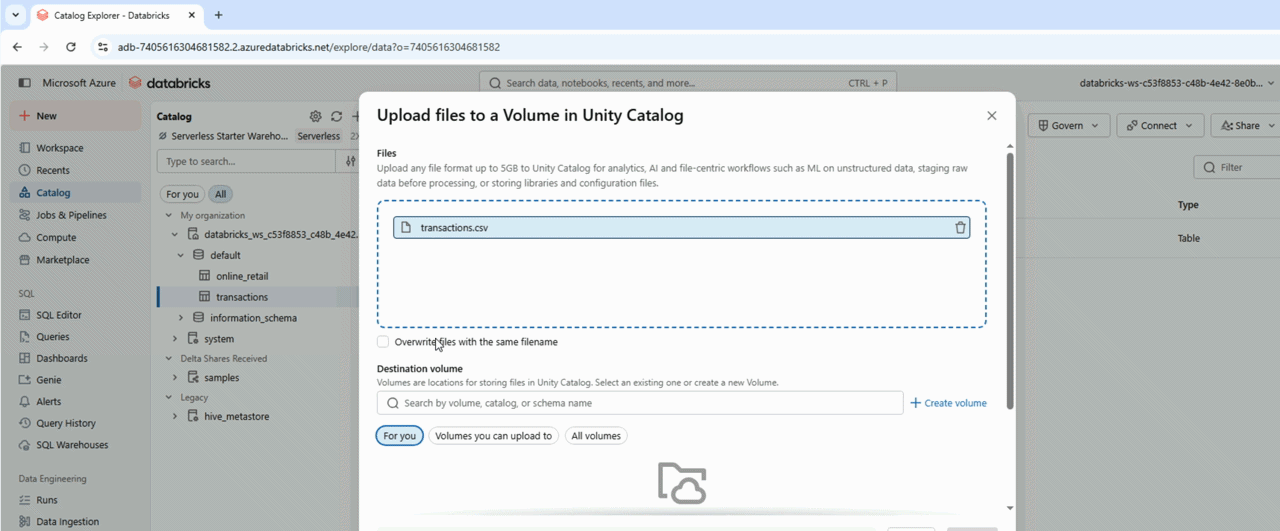
Previewing the data
df.show(5, truncate=False)

Driver logs