Shaping data with PySpark and SQL
Data Transformation with Spark SQL in Databricks

Disha Mukherjee
Lead Data Engineer
Shaping your data
path = "/Volumes/.../default/transactions.csv"
df = spark.read.csv(path, header=True, inferSchema=True)
df.show(5, truncate=False)

select()→ choose columnsfilter()→ choose rows
Python methods or SQL

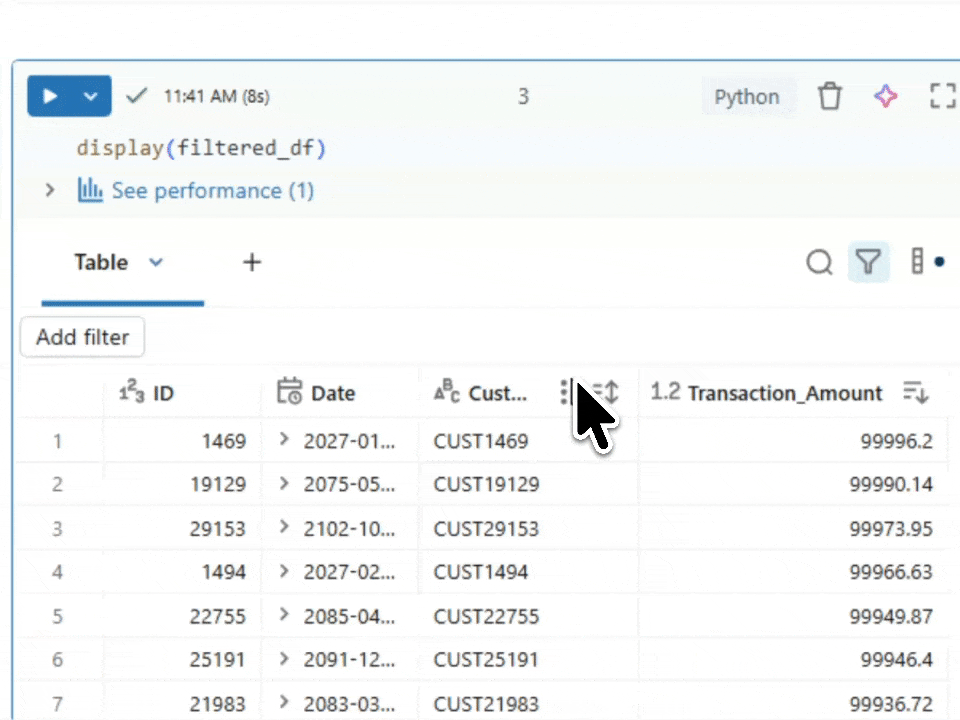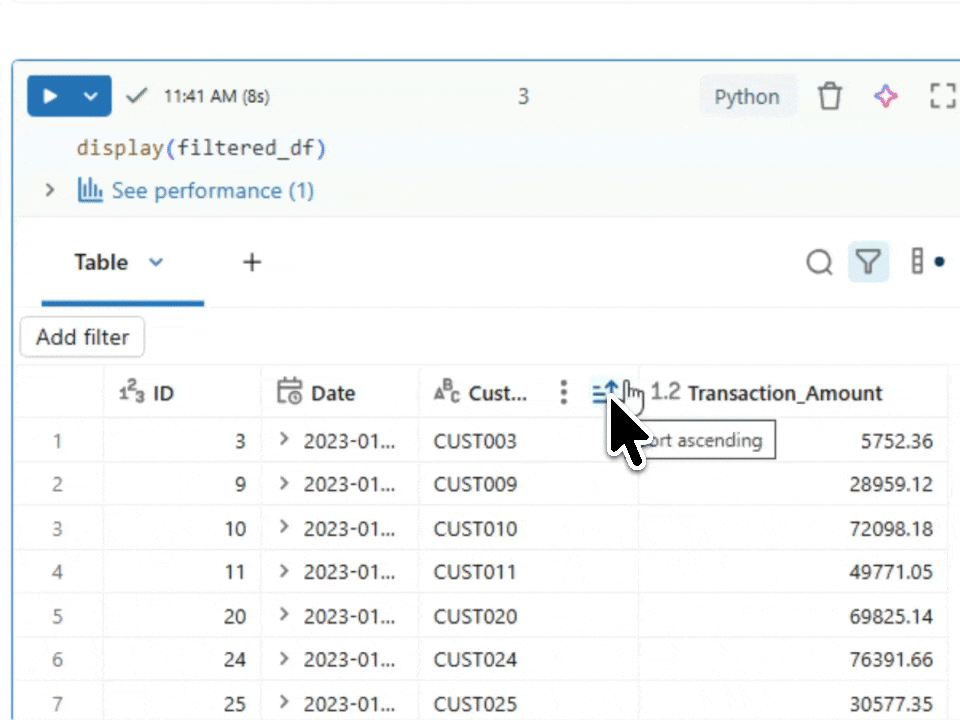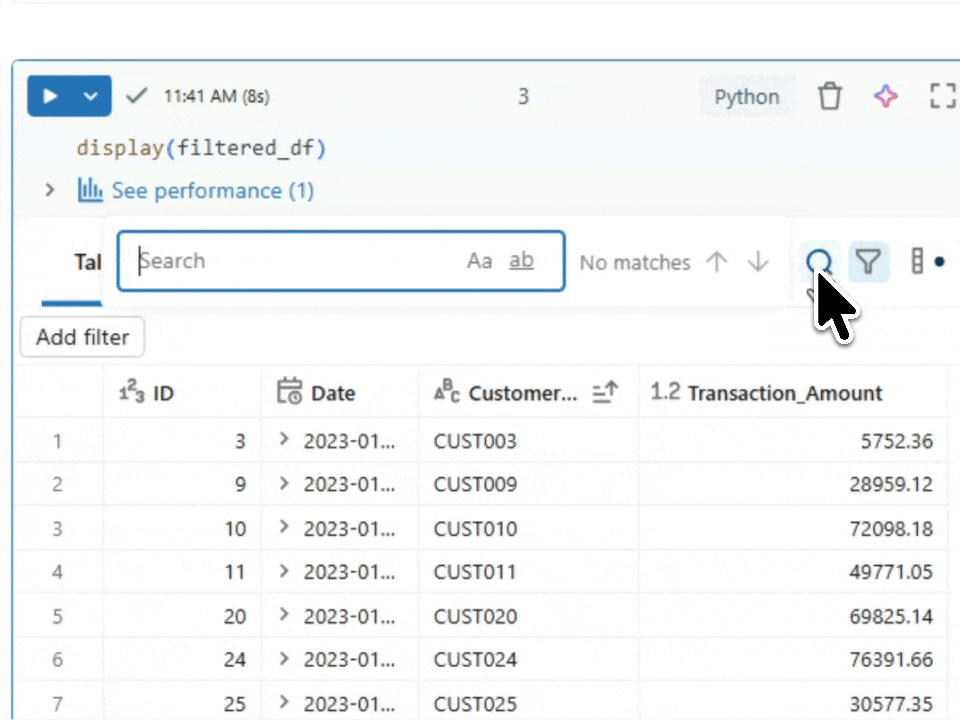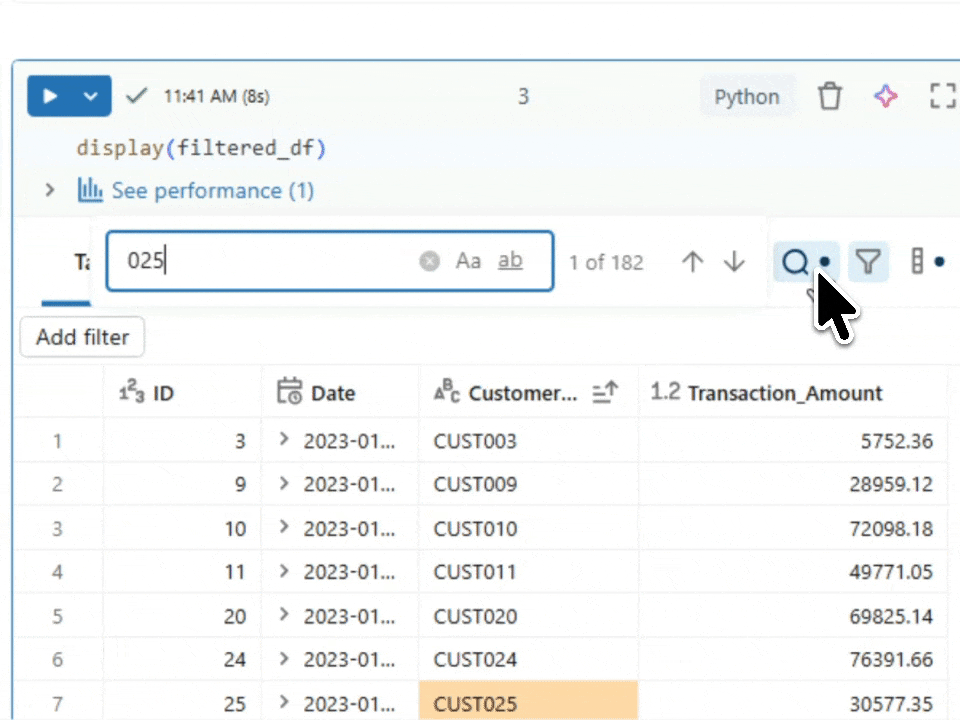
Validating with display()
display(filtered_df)