Production pipelines with workflows
Data Transformation with Spark SQL in Databricks

Disha Mukherjee
Lead Data Engineer
Why Delta Lake?

Notebook tasks
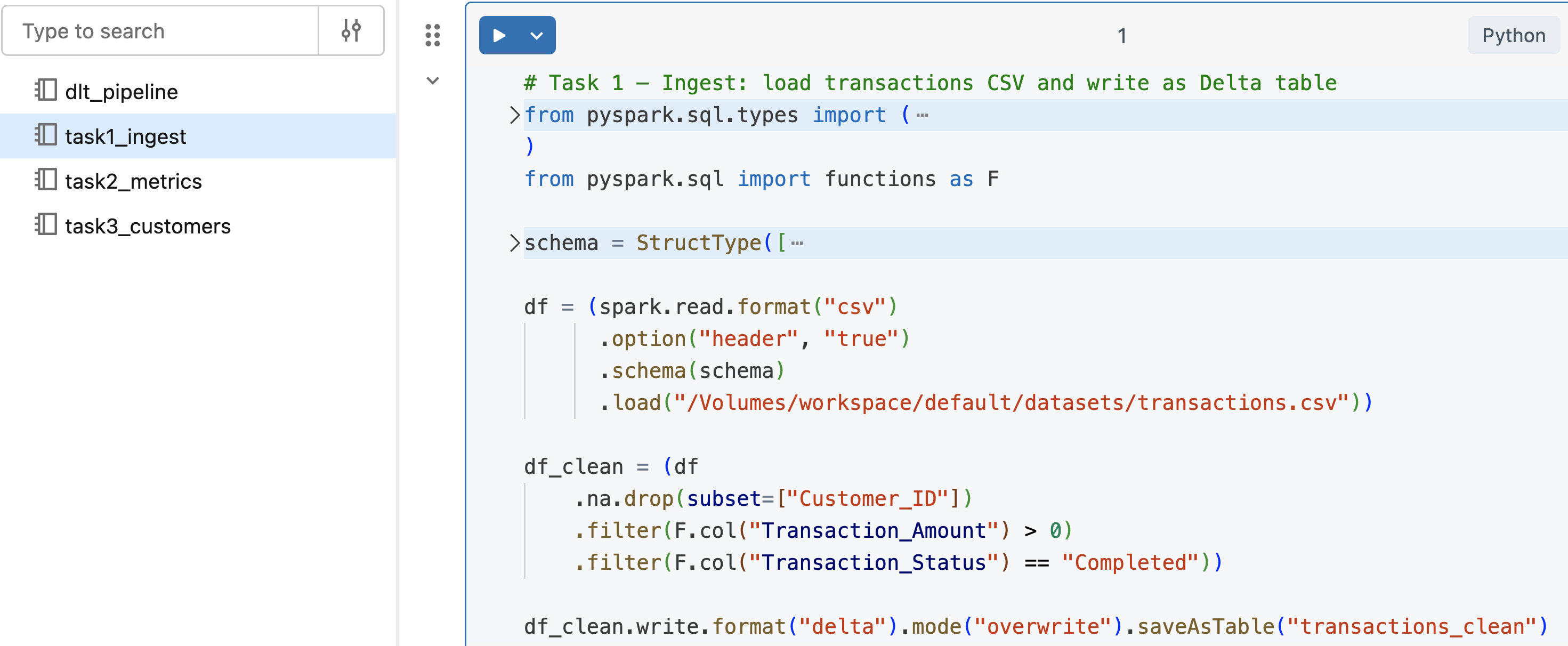
- Loads CSV → applies cleaning → writes a Delta table
Notebook tasks
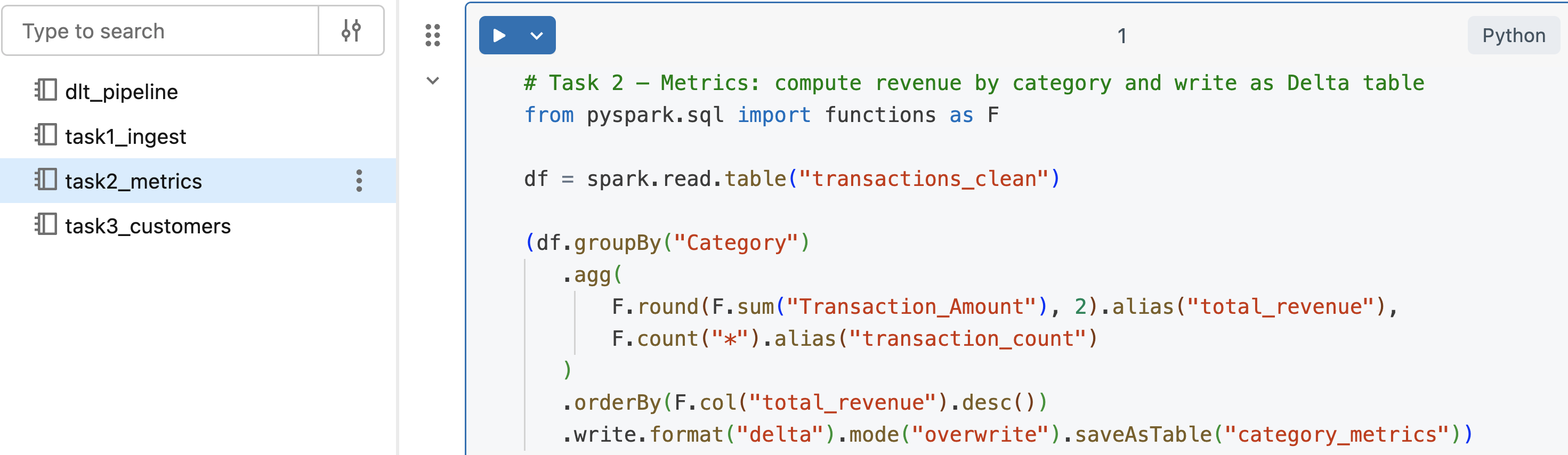
- Reads cleaned table → computes metrics → writes to a new table
Notebook tasks

- Reads cleaned table → ranks customers → saves to a new table
Creating the job
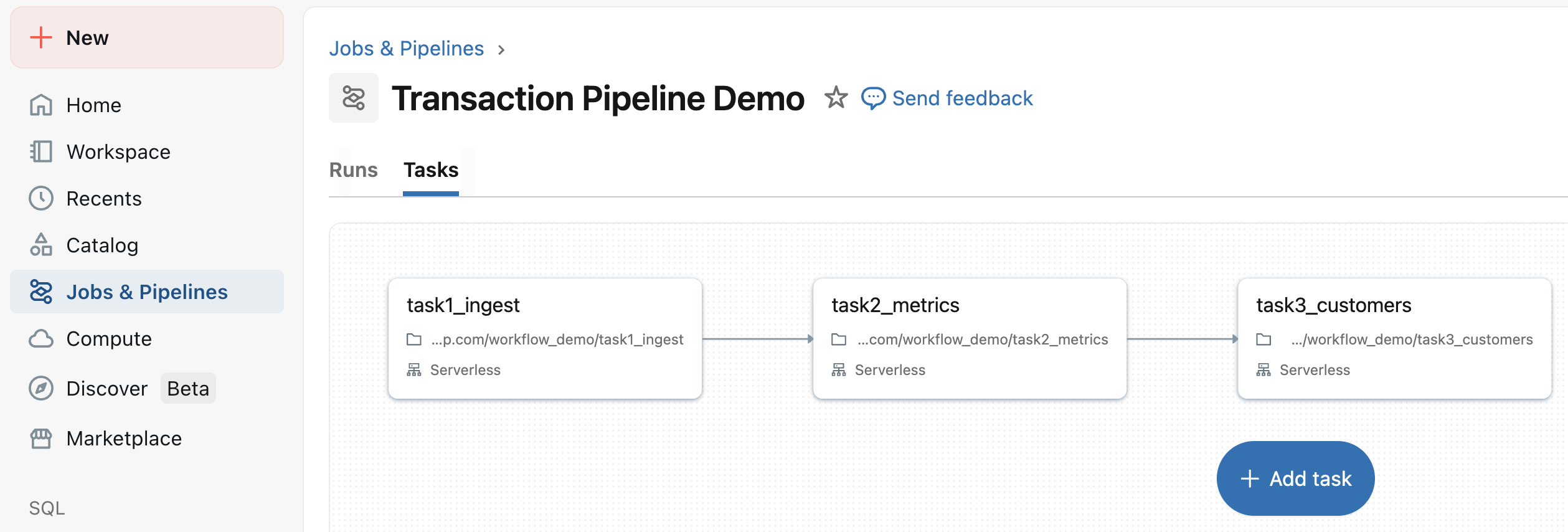
- Can run manually, schedule jobs, and set triggers
Running the job
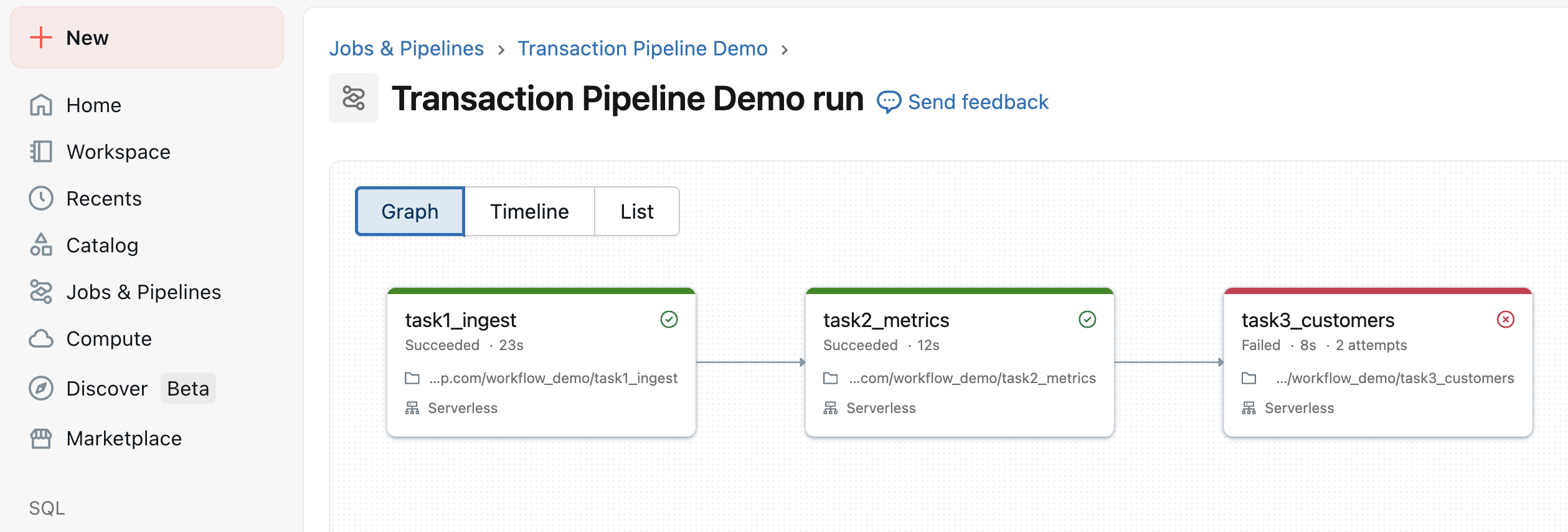
Running the job
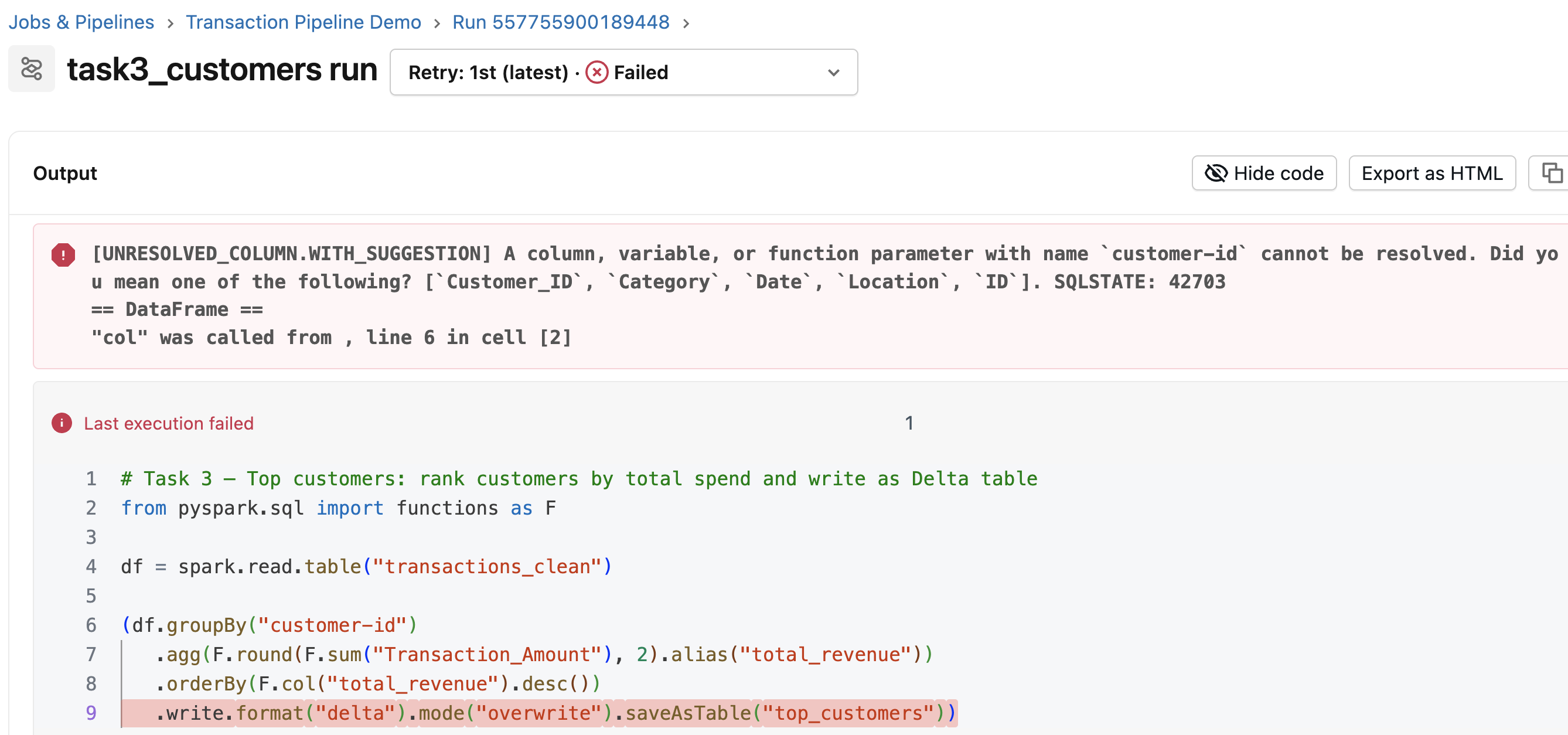
- Error:
customer-idshould beCustomer_ID
Running the job
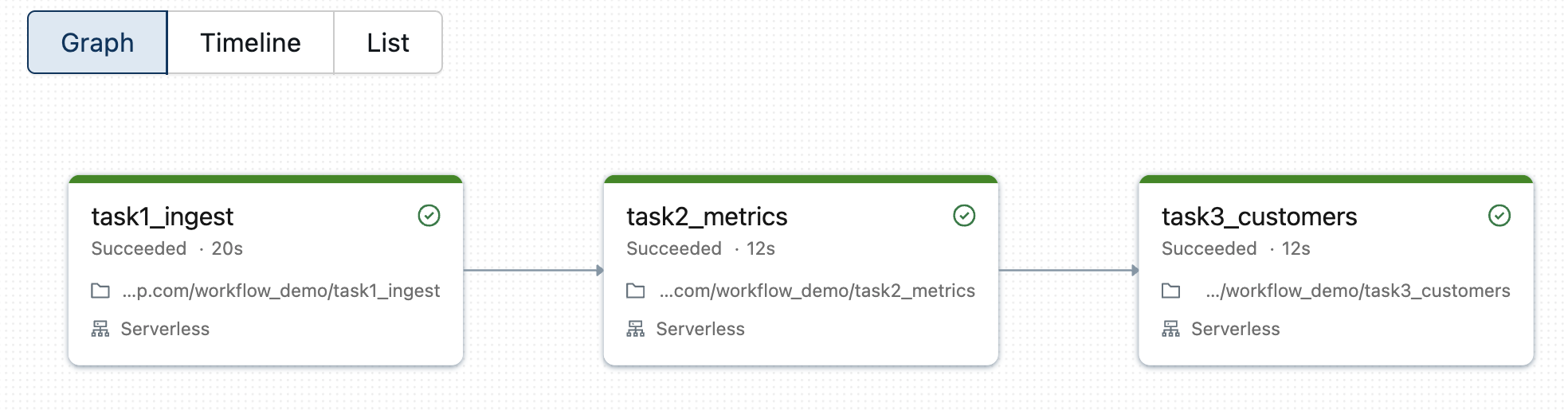
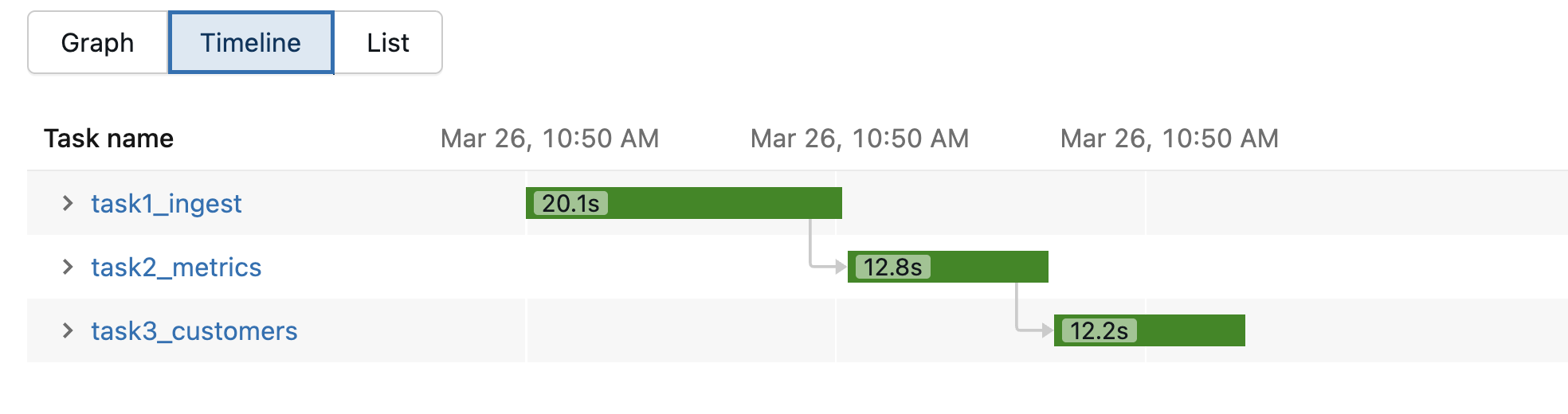
What is Lakeflow?
$$
$$

Pipeline run
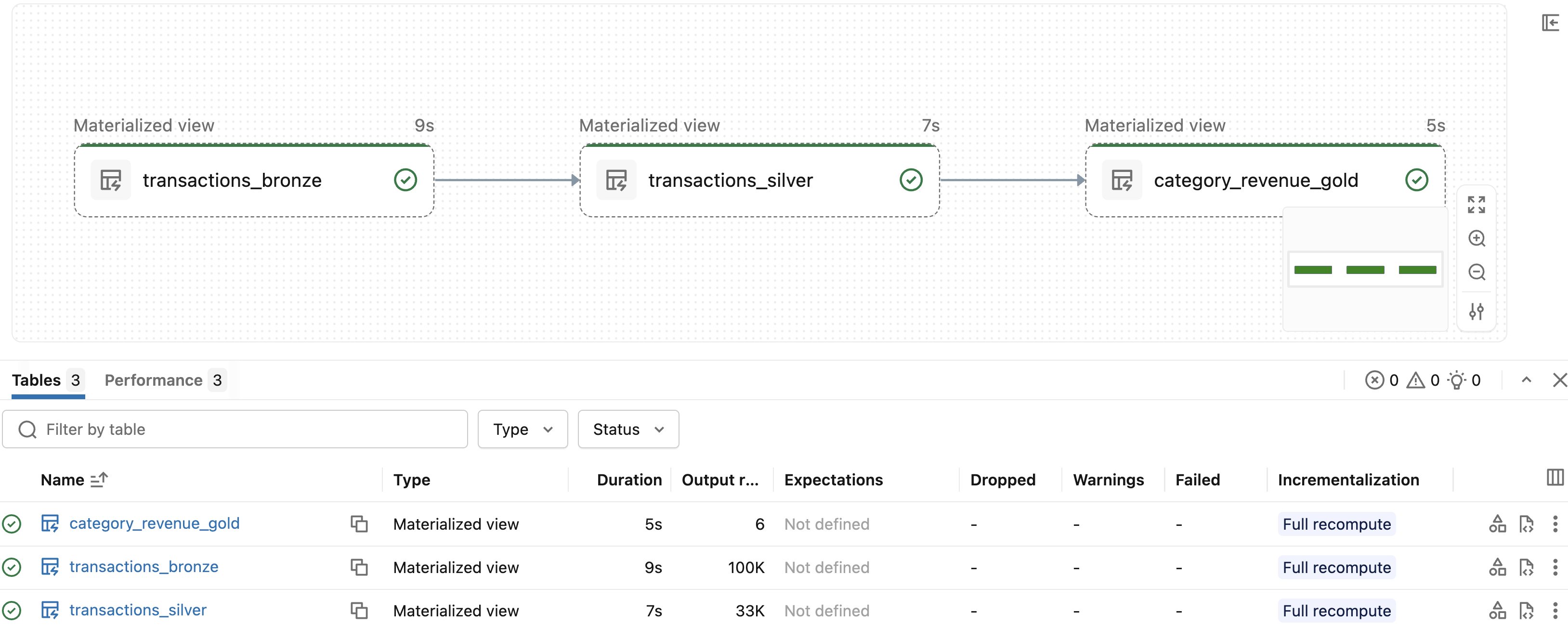
- Bronze (100K rows) → Silver (33K rows) → Gold (6 rows)
Notebooks, Jobs, or Lakeflow?
$$


