Méthodes avancées de découpage
Retrieval Augmented Generation (RAG) avec LangChain

Meri Nova
Machine Learning Engineer
Découper par jetons

Découper par jetons
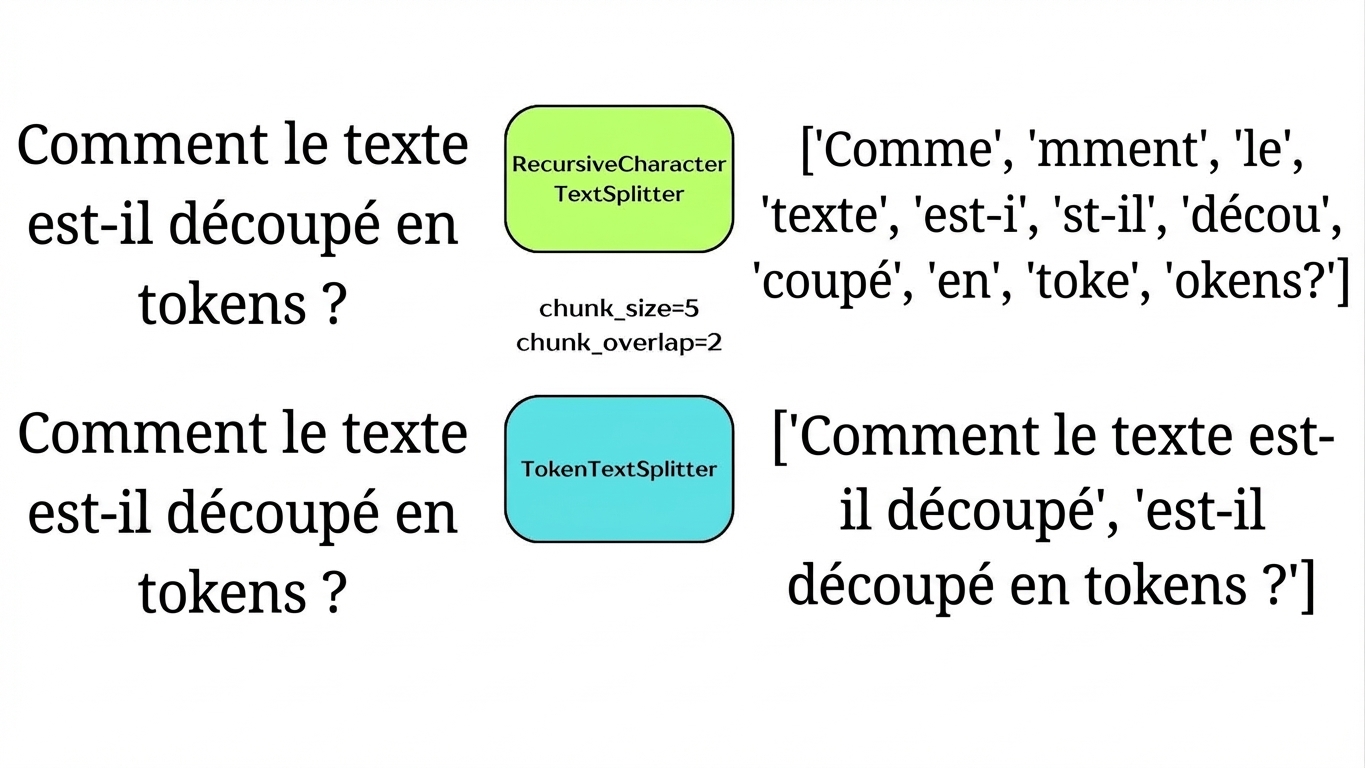
Découper par jetons
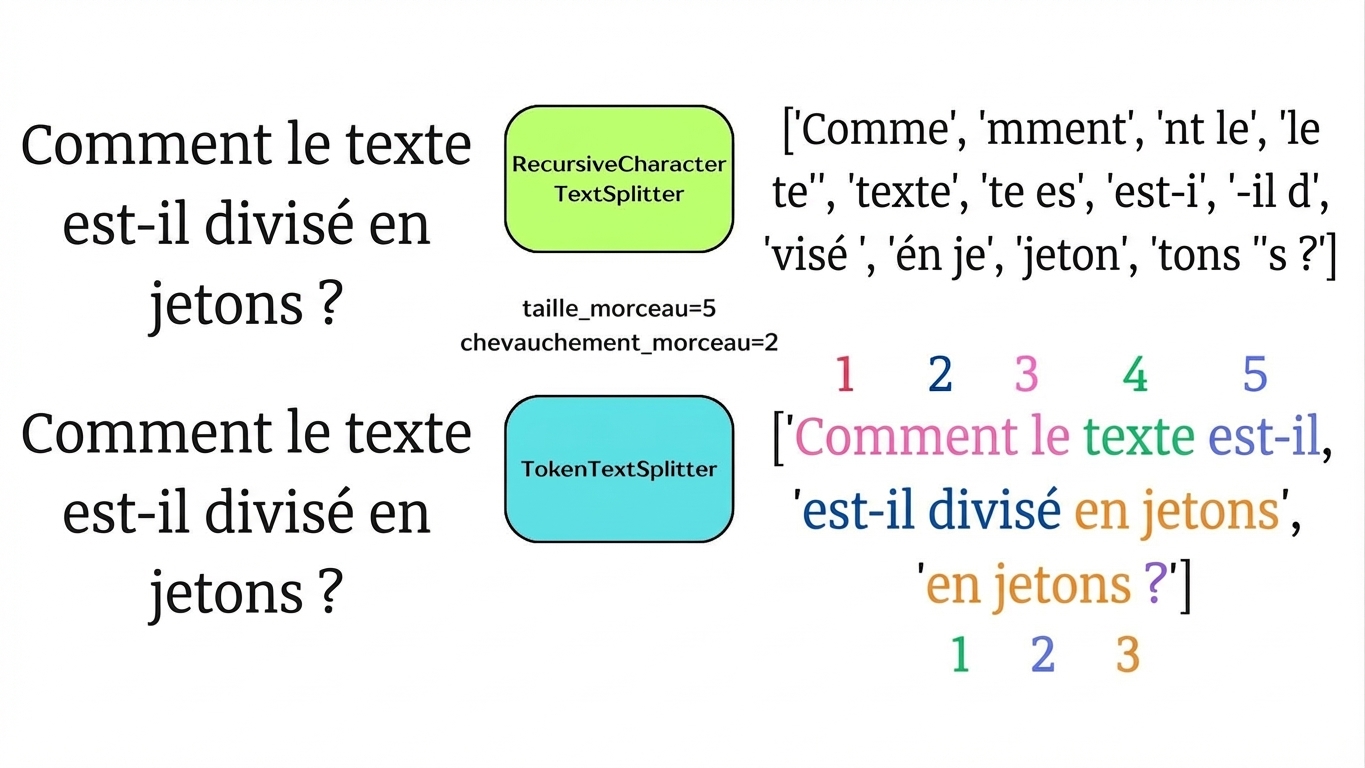
Découpage sémantique

Découpage sémantique

Découpage sémantique

Retrieval Augmented Generation (RAG) avec LangChain
Meri Nova
Machine Learning Engineer

