Créer une chaîne de récupération LCEL
Retrieval Augmented Generation (RAG) avec LangChain

Meri Nova
Machine Learning Engineer
Préparer les données pour la récupération

Introduction à LCEL pour le RAG

Introduction à LCEL pour le RAG
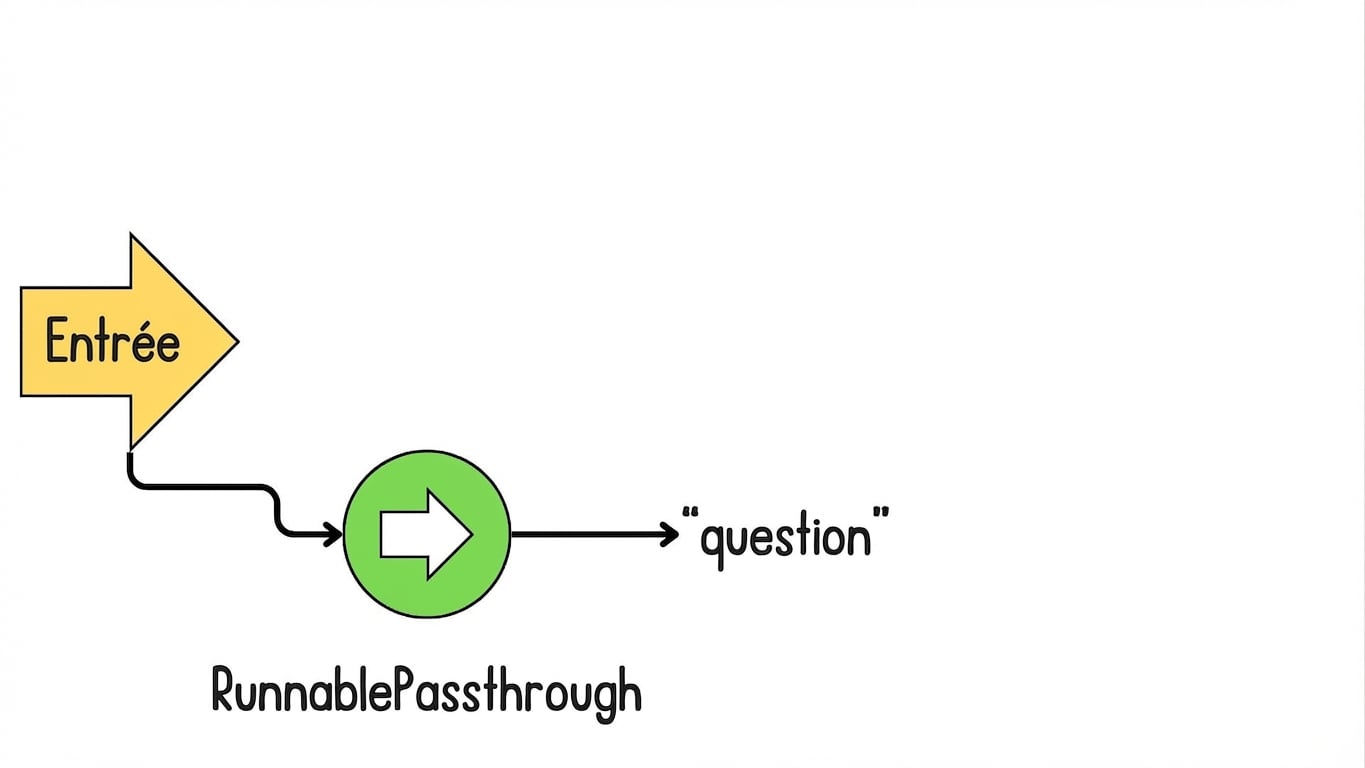
Introduction à LCEL pour le RAG
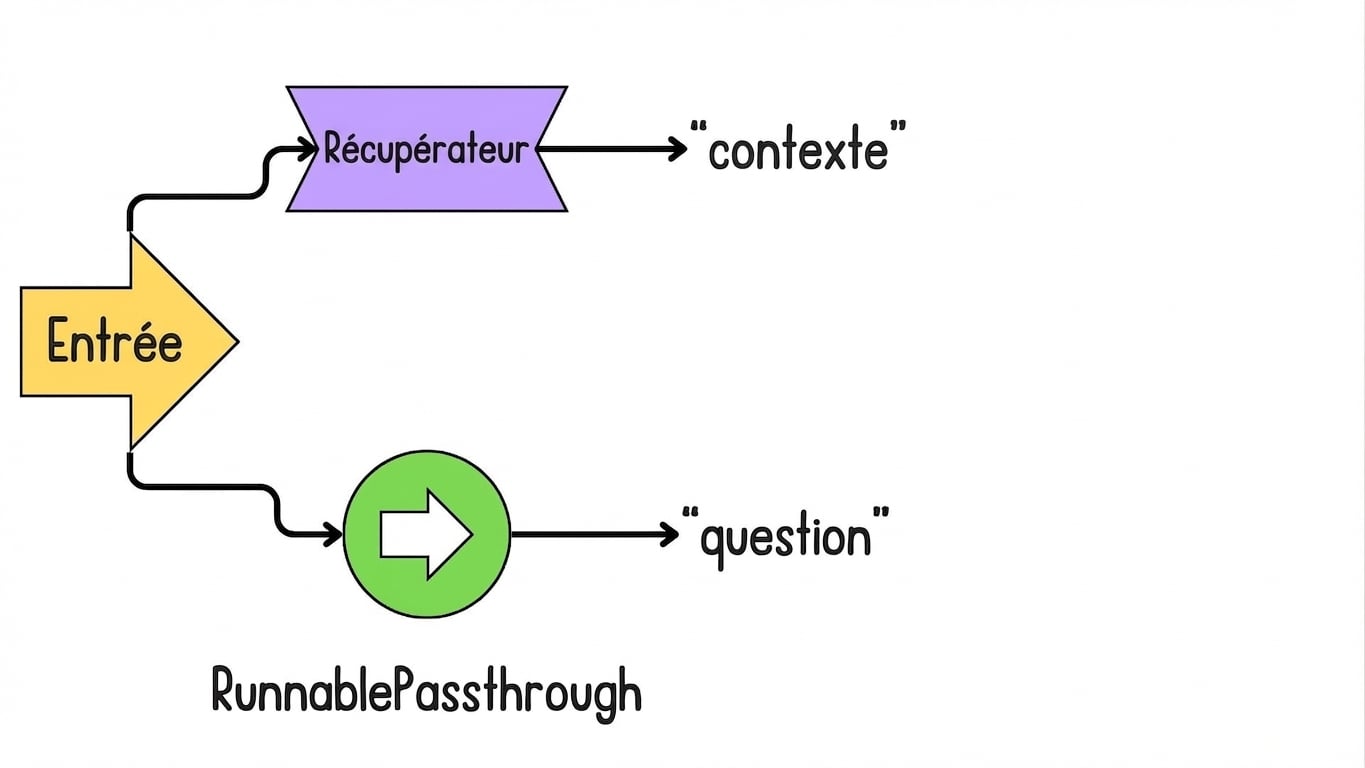
Introduction à LCEL pour le RAG
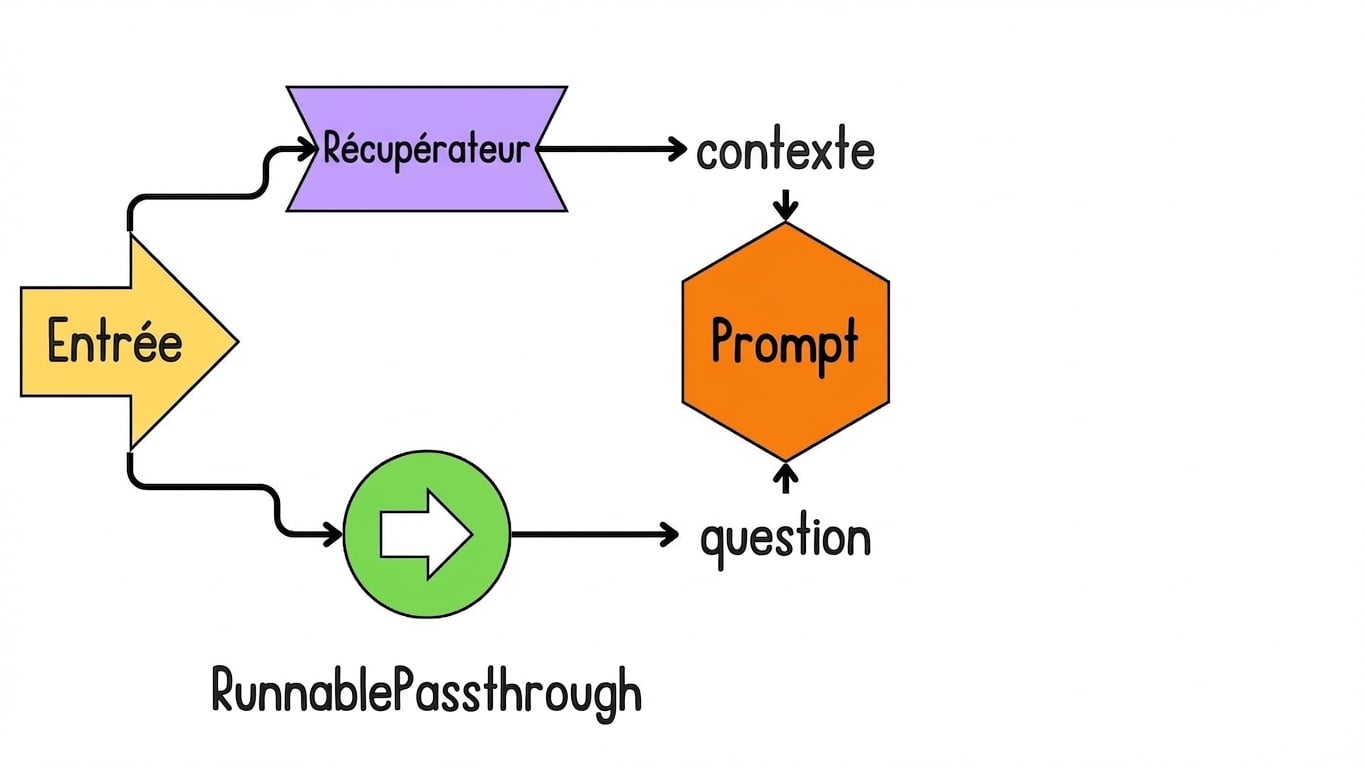
Introduction à LCEL pour le RAG
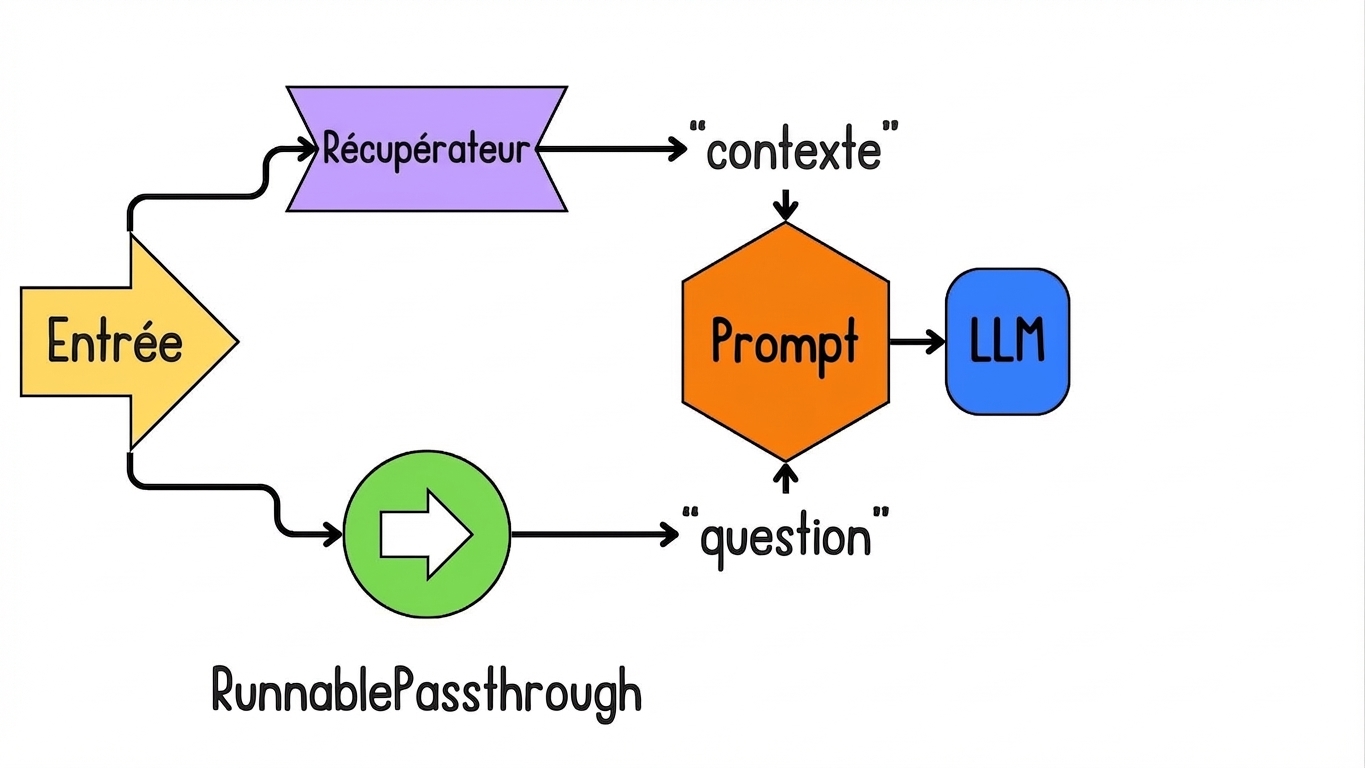
Introduction à LCEL pour le RAG


