Ingénierie et sélection de caractéristiques
Machine Learning de bout en bout

Joshua Stapleton
Machine Learning Engineer
Feature engineering
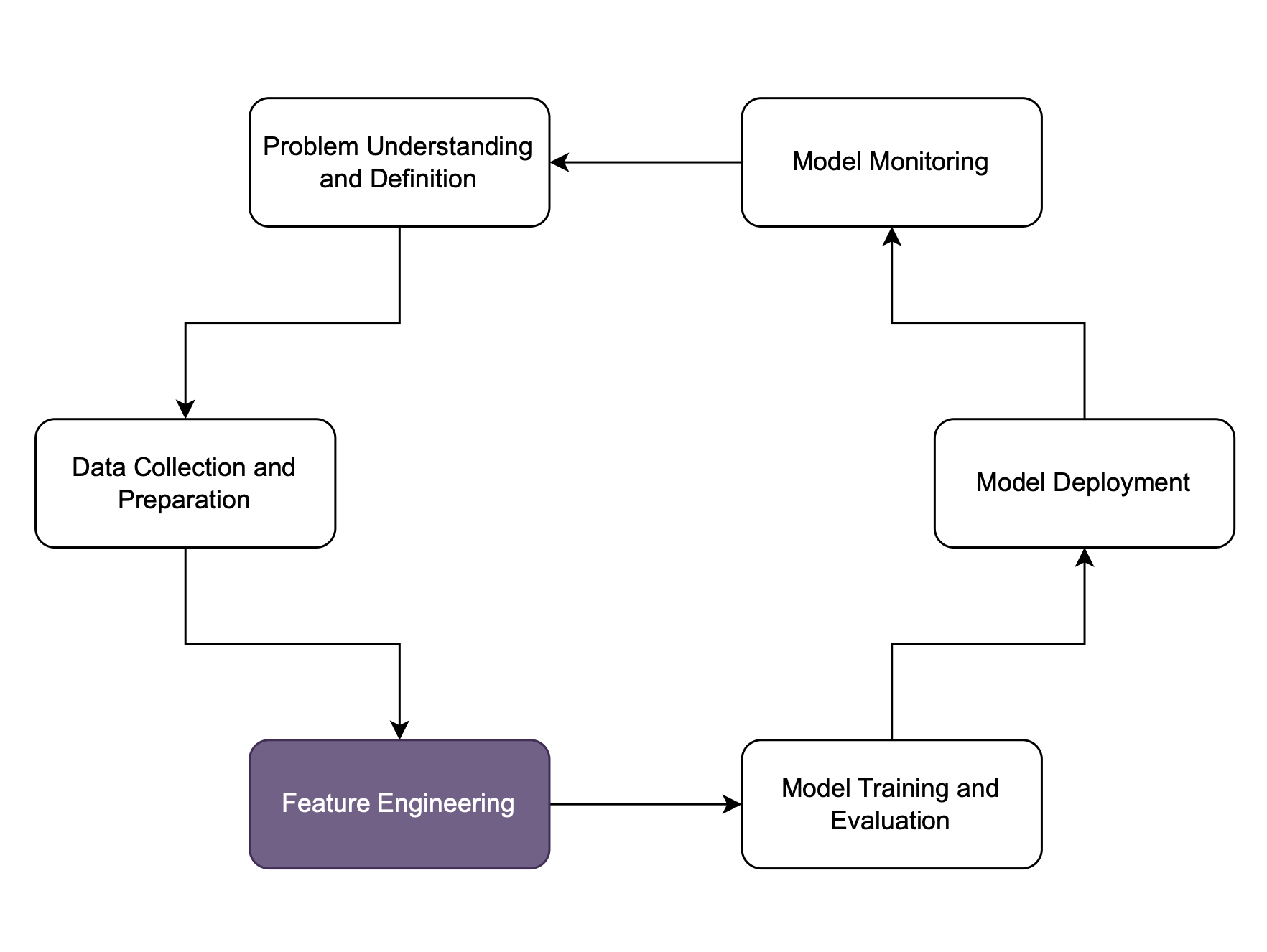
Qu’est-ce qu’une bonne caractéristique ?
- Utiliser des caractéristiques pertinentes
- La météo le jour du rendez-vous n’influe pas sur le diagnostic

- Utiliser des caractéristiques dissemblables (orthogonales)
- Âge en mois et âge en années sont redondants