Méthodes Monte Carlo
Reinforcement Learning avec Gymnasium en Python

Fouad Trad
Machine Learning Engineer
Rappel : apprentissage basé sur modèle
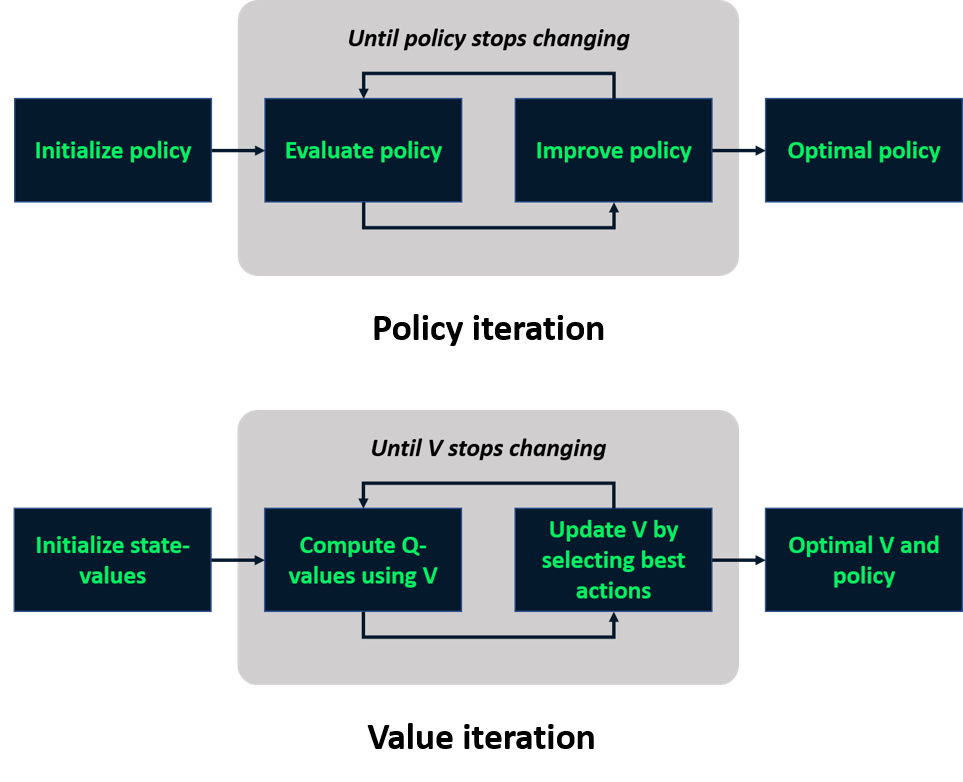
Apprentissage sans modèle

Méthodes Monte Carlo
- Techniques sans modèle
- Estiment les Q-valeurs à partir des épisodes
Méthodes Monte Carlo
- Techniques sans modèle
- Estiment les Q-valeurs à partir des épisodes

Méthodes Monte Carlo
- Techniques sans modèle
- Estiment les Q-valeurs à partir des épisodes

- Deux variantes : première visite, toutes visites
Grid world personnalisé
Collecte de deux épisodes
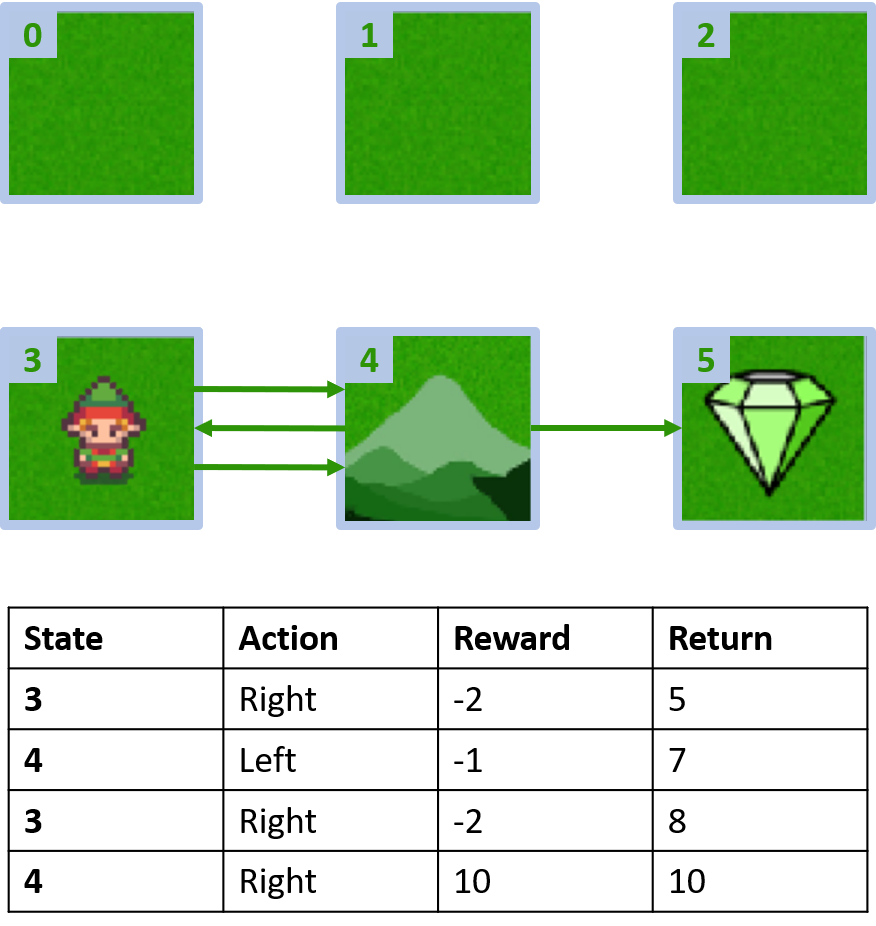
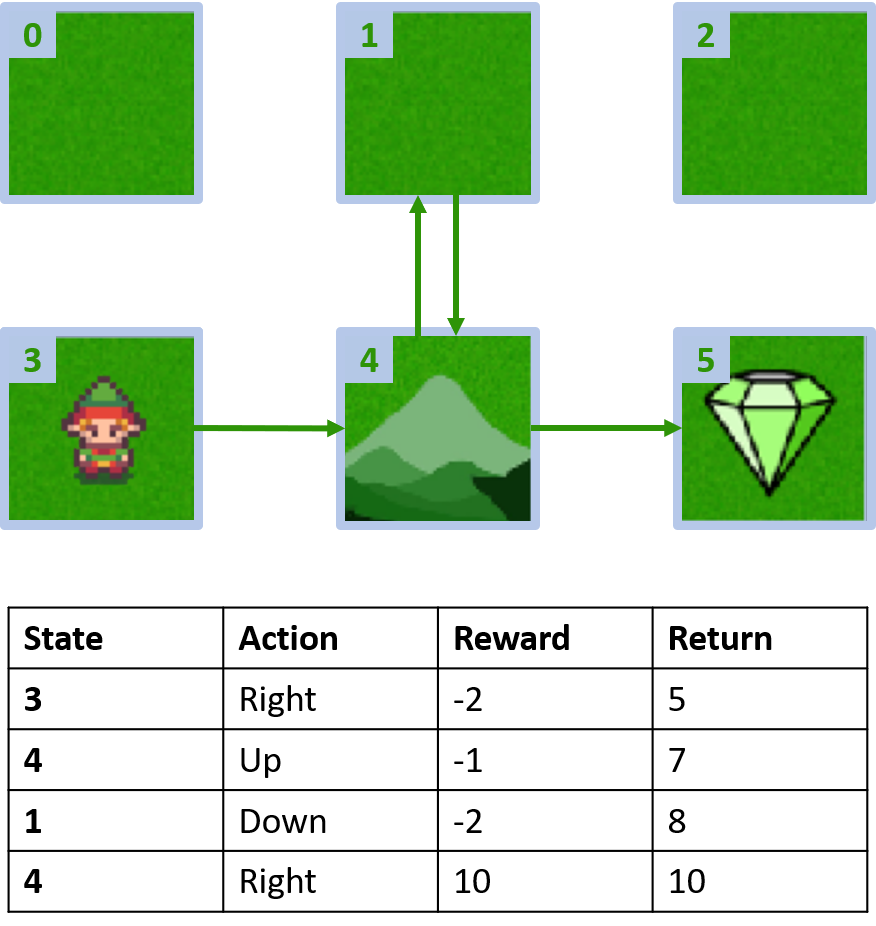
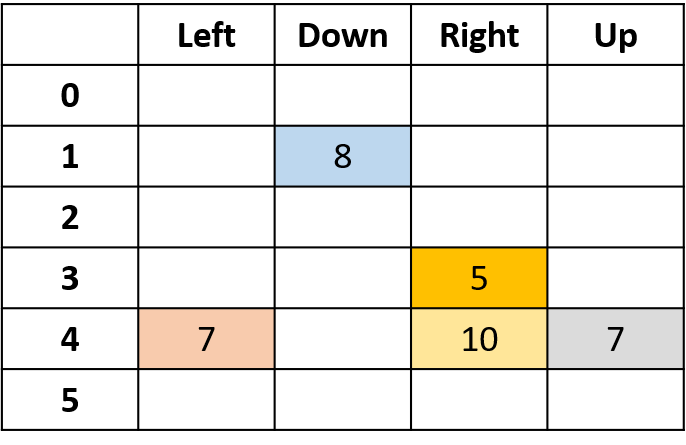
Estimation des Q-valeurs
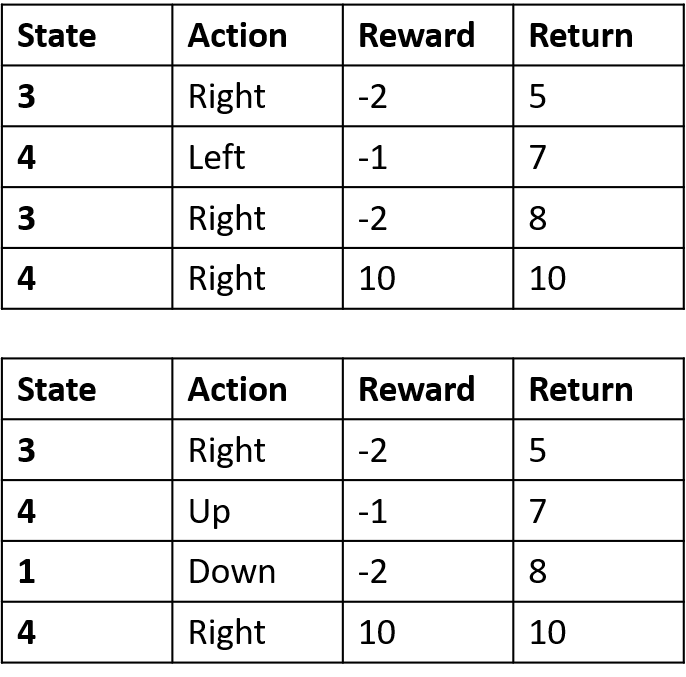
- Q-table : table des Q-valeurs
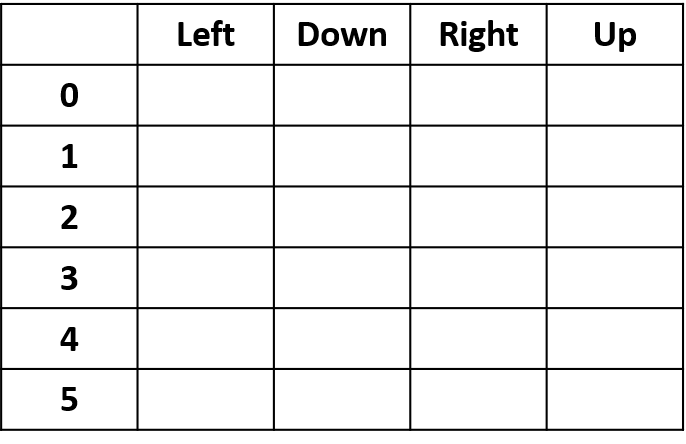
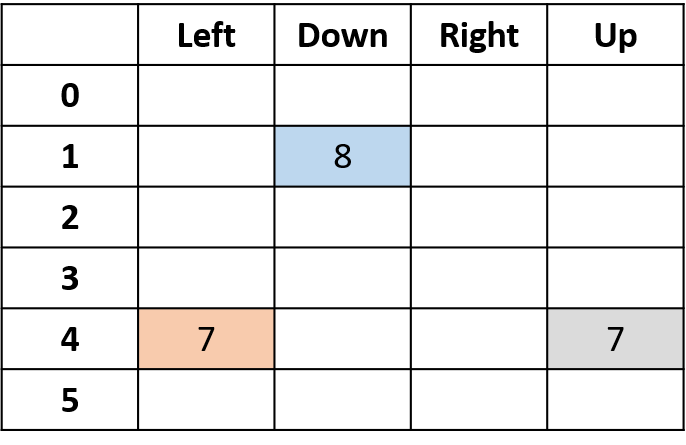
Q(4, gauche), Q(4, haut) et Q(1, bas)
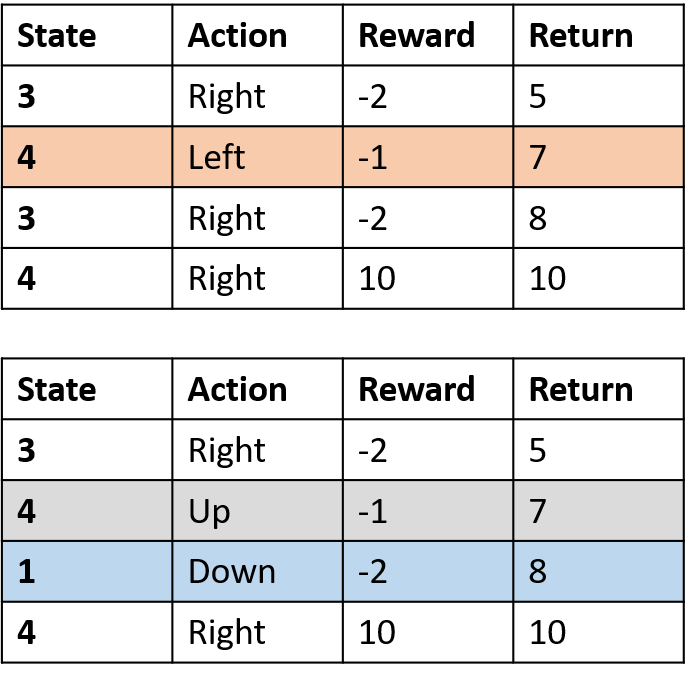
- (s,a) apparaît une fois -> remplir avec le retour
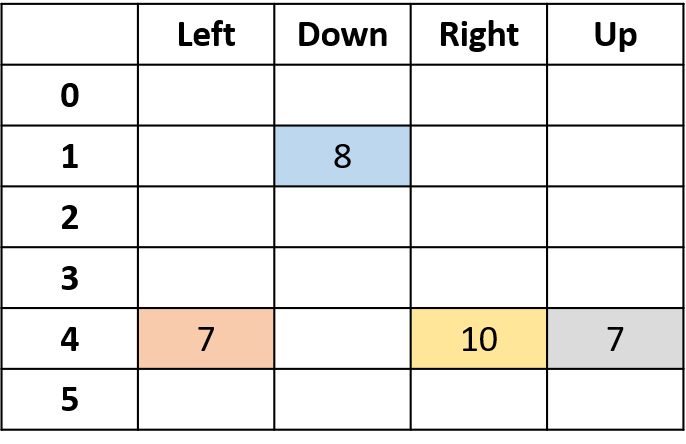
Q(4, droite)
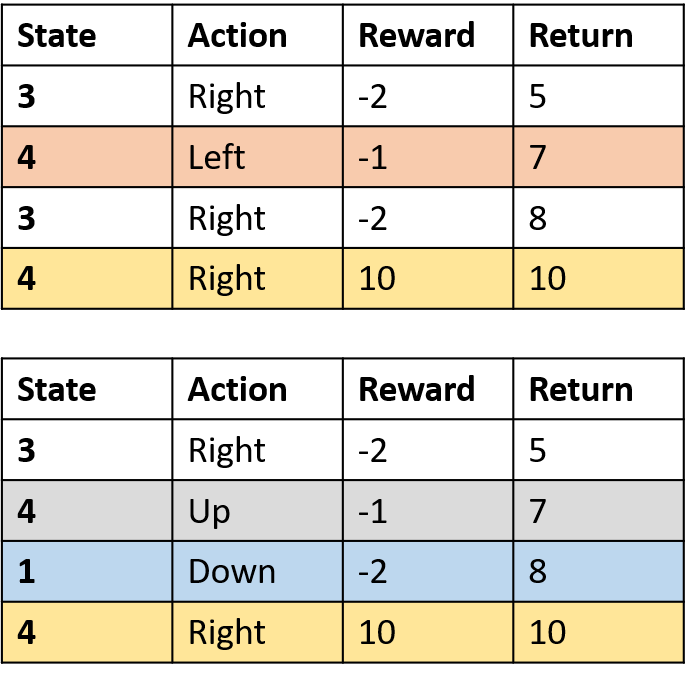
- (s,a) survient une fois par épisode -> moyenne
Q(3, droite) - Monte Carlo première visite
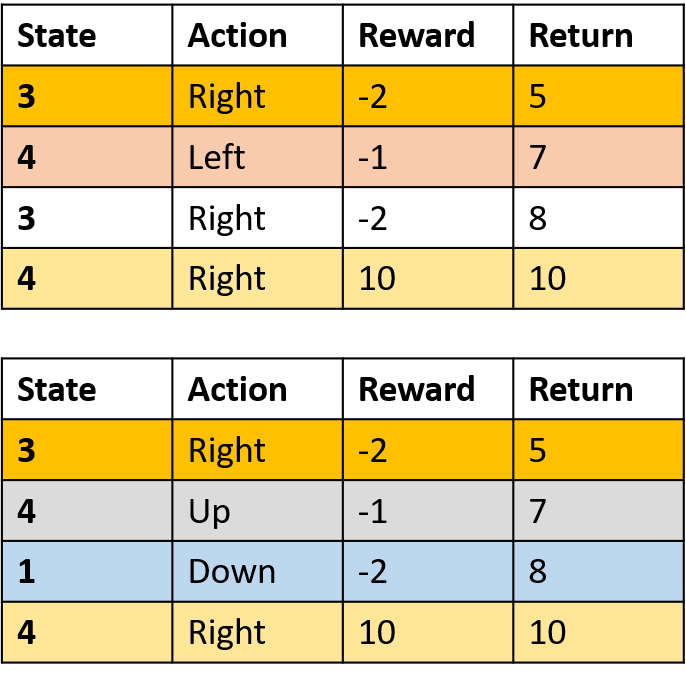
- Moyenne de la première visite de (s,a) dans les épisodes
Q(3, droite) - Monte Carlo toutes visites
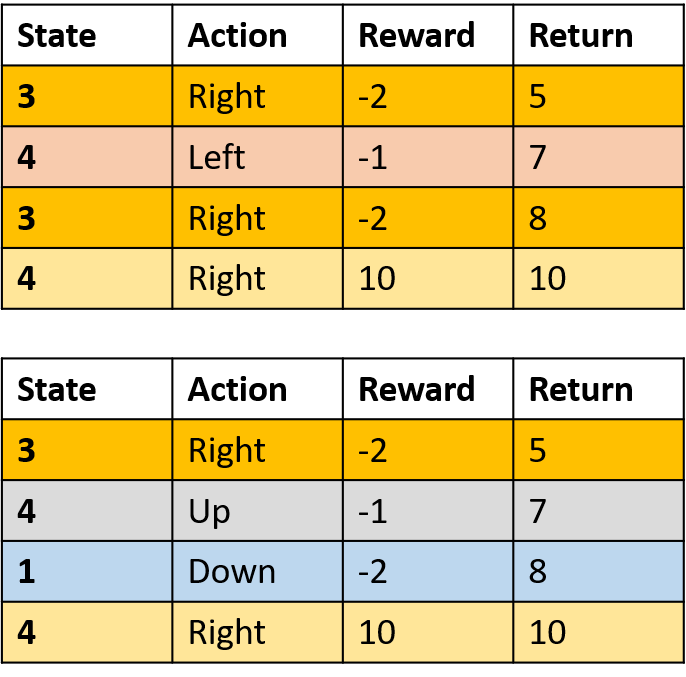
- Moyenne de chaque visite de (s,a) dans les épisodes
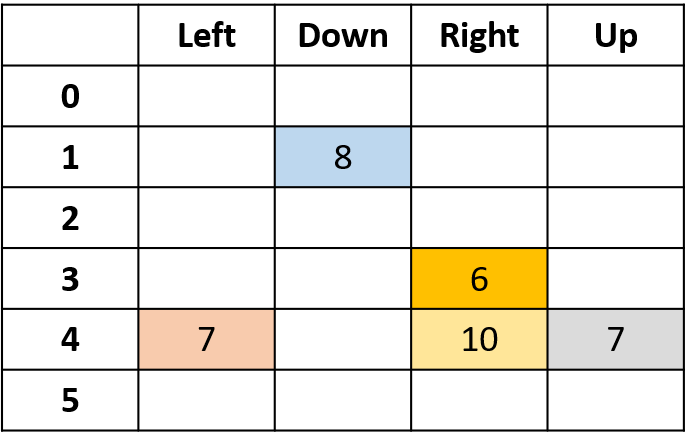
Récapitulatif