Équilibrer exploration et exploitation
Reinforcement Learning avec Gymnasium en Python

Fouad Trad
Machine Learning Engineer
Entraînement avec actions aléatoires

Compromis exploration–exploitation

Choix au restaurant

Stratégie epsilon-greedy
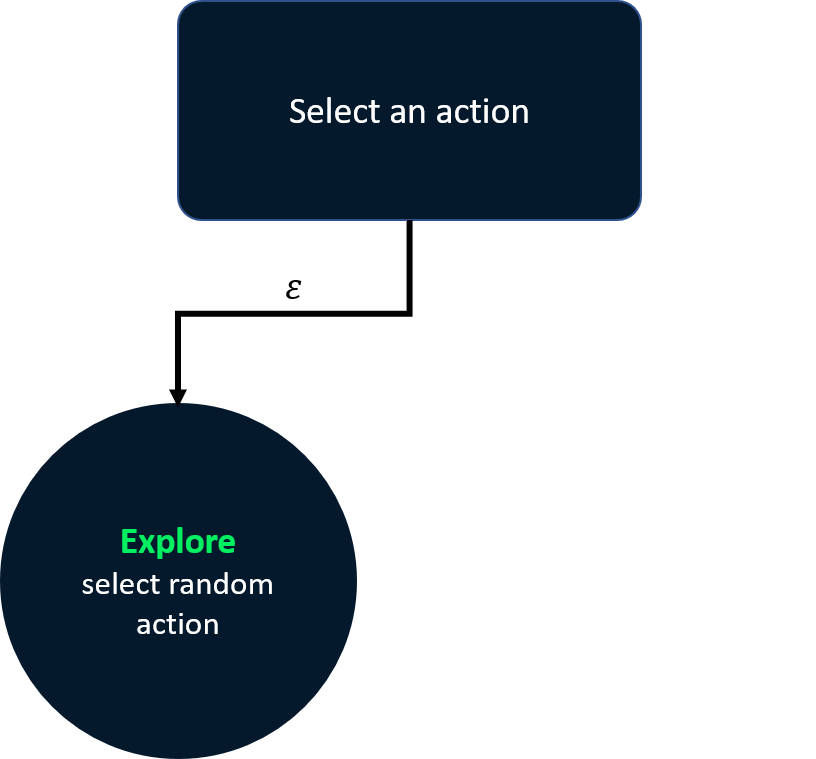
Stratégie epsilon-greedy
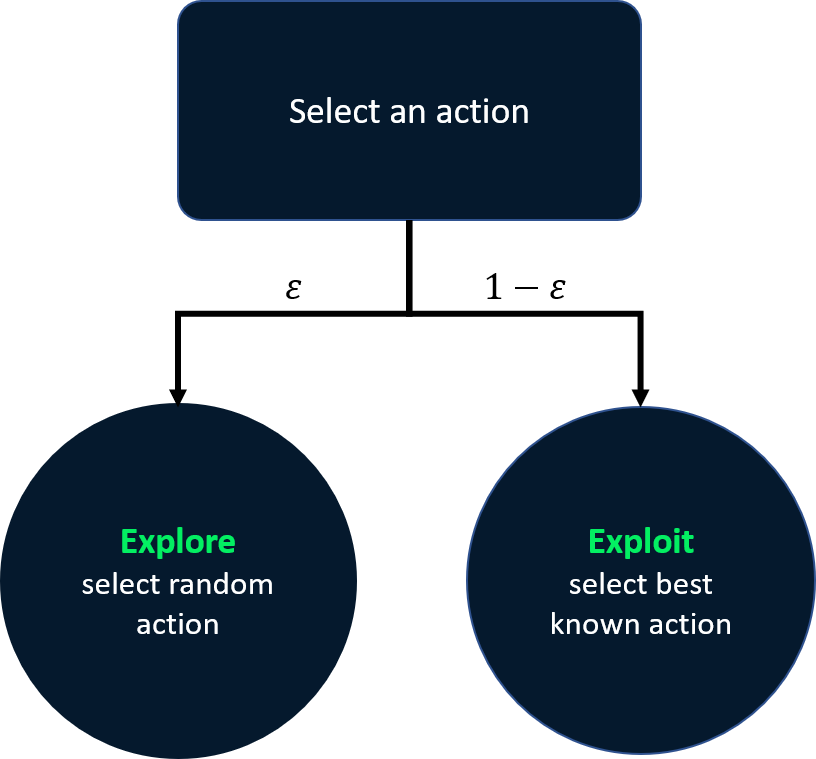
Stratégie epsilon-greedy décroissante

Implémentation avec Frozen Lake

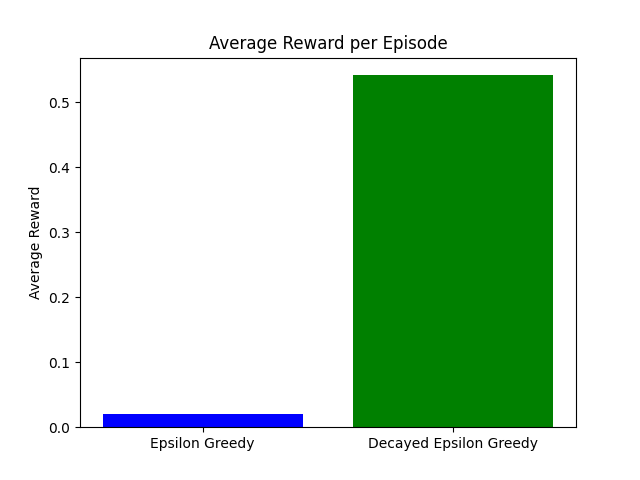
Comparer les stratégies