Processus de décision de Markov
Reinforcement Learning avec Gymnasium en Python

Fouad Trad
Machine Learning Engineer
MDP
- Modélise mathématiquement les environnements RL

MDP
- Modélise mathématiquement les environnements RL

Propriété de Markov
- L’état futur dépend uniquement de l’état courant et de l’action

Frozen Lake comme MDP
- L’agent doit atteindre l’objectif sans tomber dans les trous

Frozen Lake comme MDP - états
- Positions que l’agent peut occuper

Frozen Lake comme MDP - états terminaux
- Mènent à la fin de l’épisode
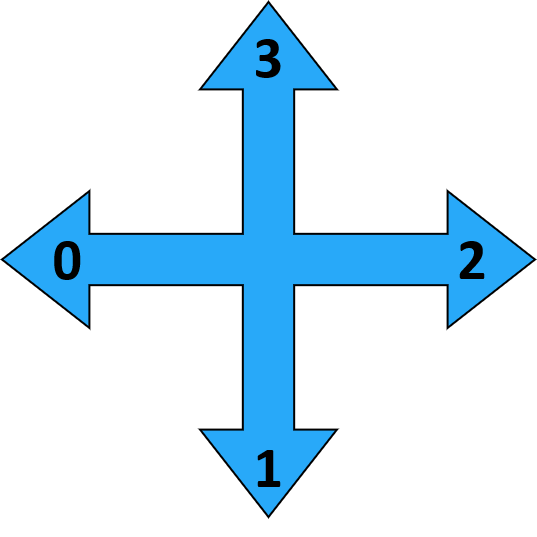
Frozen Lake comme MDP - actions
- Haut, bas, gauche, droite
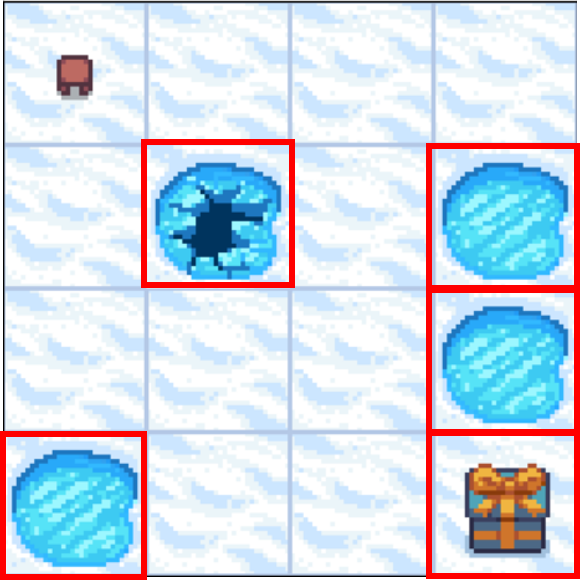
Frozen Lake comme MDP - transitions
- Les actions ne mènent pas toujours au résultat attendu
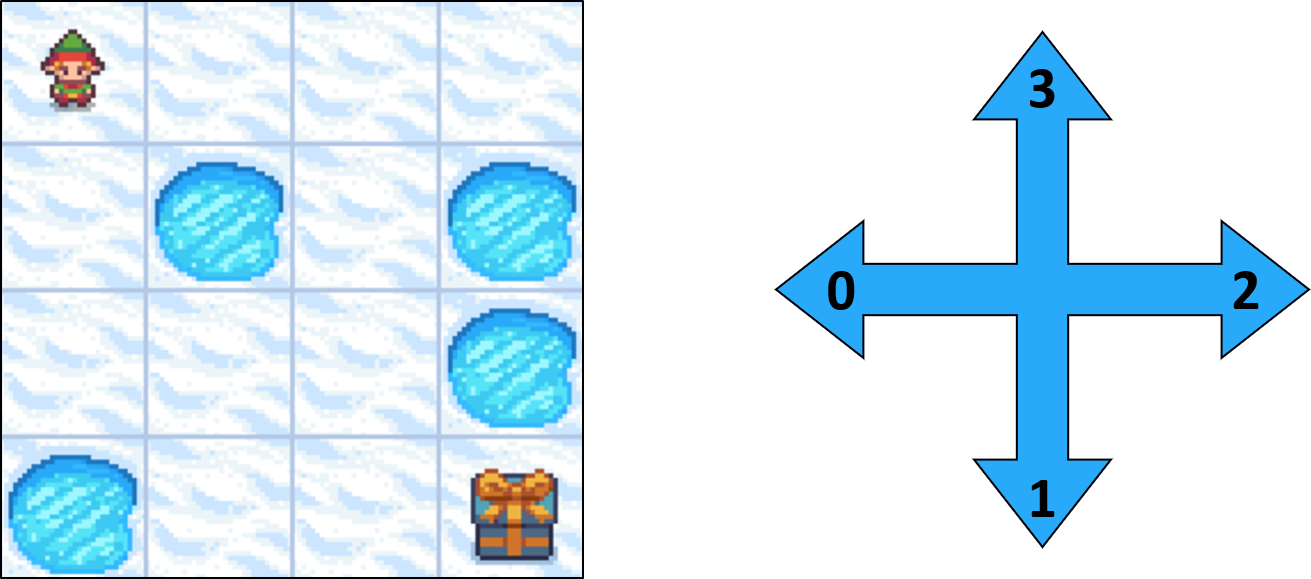
Frozen Lake comme MDP - transitions
- Les actions ne mènent pas toujours au résultat attendu
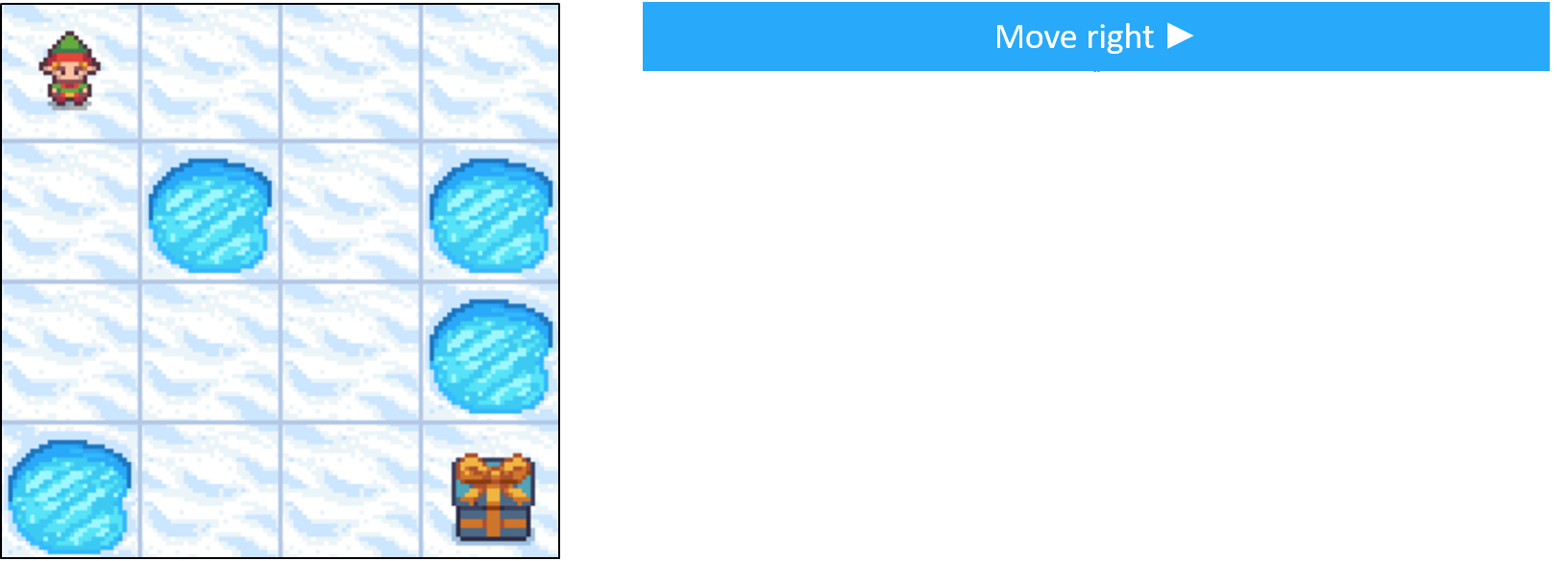
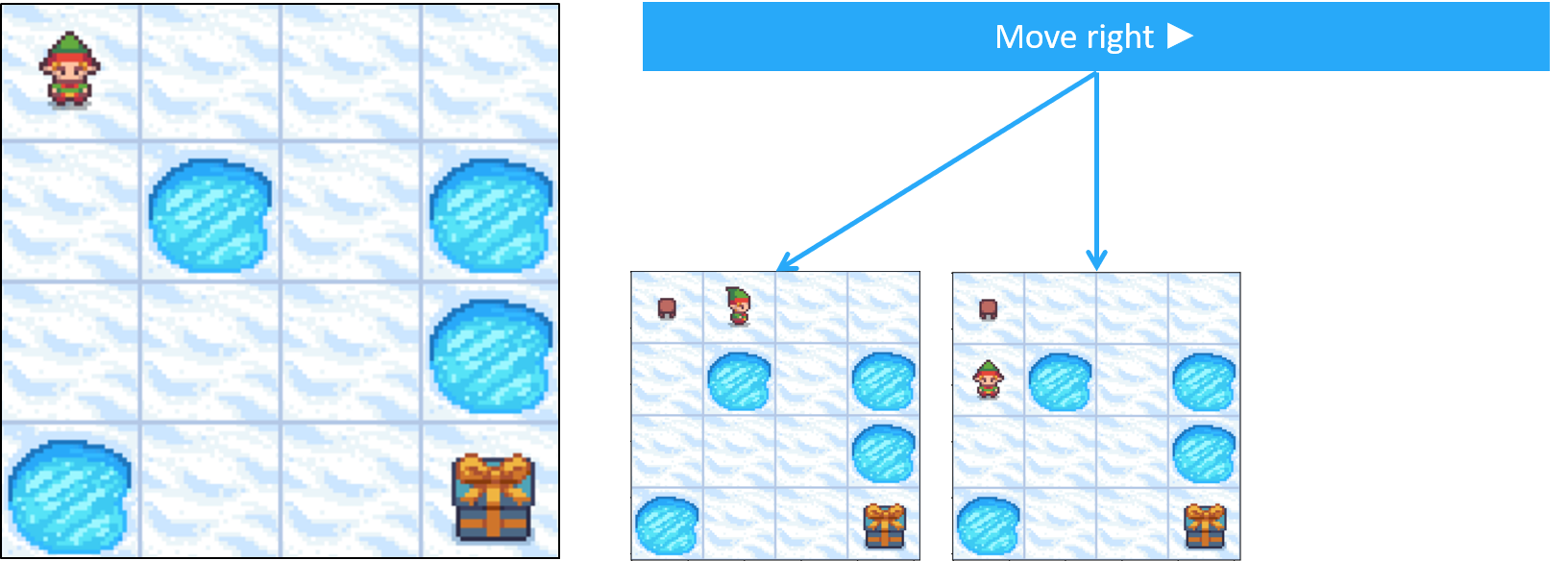
Frozen Lake comme MDP - transitions
- Les actions ne mènent pas toujours au résultat attendu
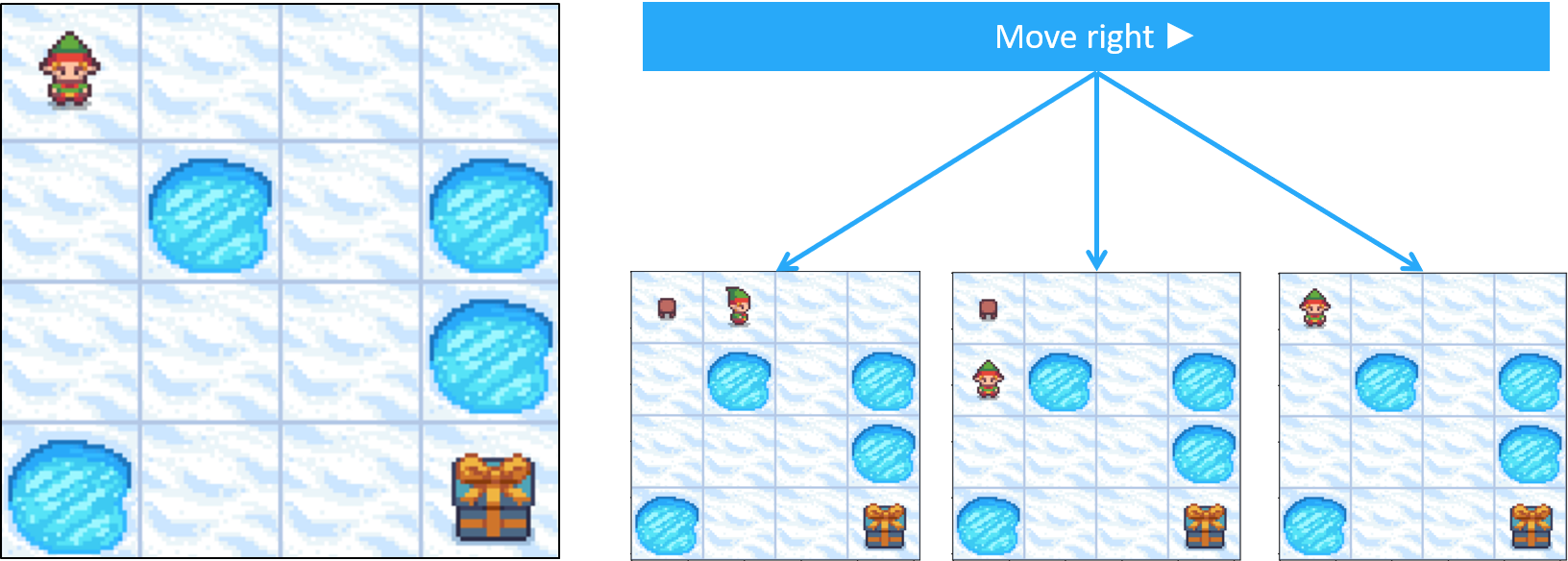
Frozen Lake comme MDP - transitions
- Les actions ne mènent pas toujours au résultat attendu
Frozen Lake comme MDP - transitions
- Les actions ne mènent pas toujours au résultat attendu
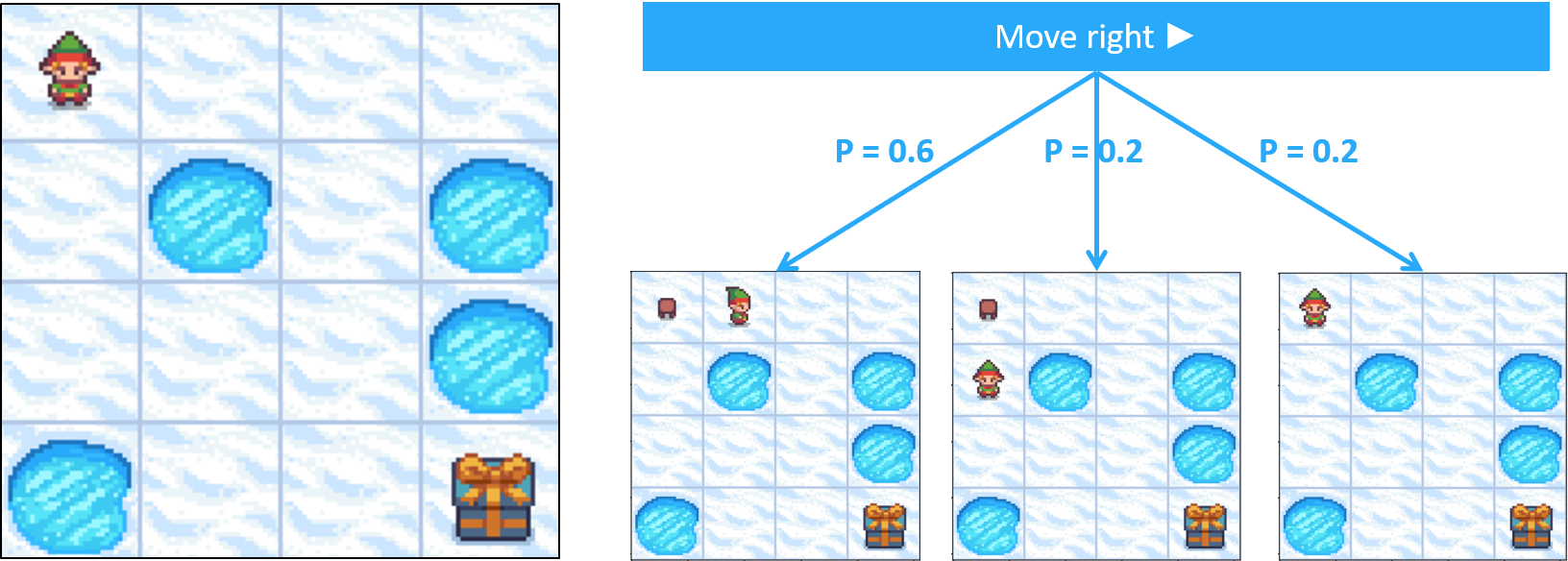
- Probabilités de transition : probabilité d’atteindre un état donné un état et une action
Frozen Lake comme MDP - récompenses
- Récompense uniquement dans l’état objectif
Récompenses et transitions dans Gymnasium - exemple
state = 6 action = 0print(env.unwrapped.P[state][action])
[(0.3333333333333333, 2, 0.0, False),
(0.3333333333333333, 5, 0.0, True),
(0.3333333333333333, 10, 0.0, False)]