Double Q-learning
Reinforcement Learning avec Gymnasium en Python

Fouad Trad
Machine Learning Engineer
Q-learning
- Estime la fonction optimale valeur‑action
- Surestime les Q-valeurs en se basant sur le max Q
- Peut mener à une politique sous-optimale

Double Q-learning
- Conserve deux tables Q
- Chaque table est mise à jour à partir de l’autre
- Réduit le risque de surestimer les Q-valeurs
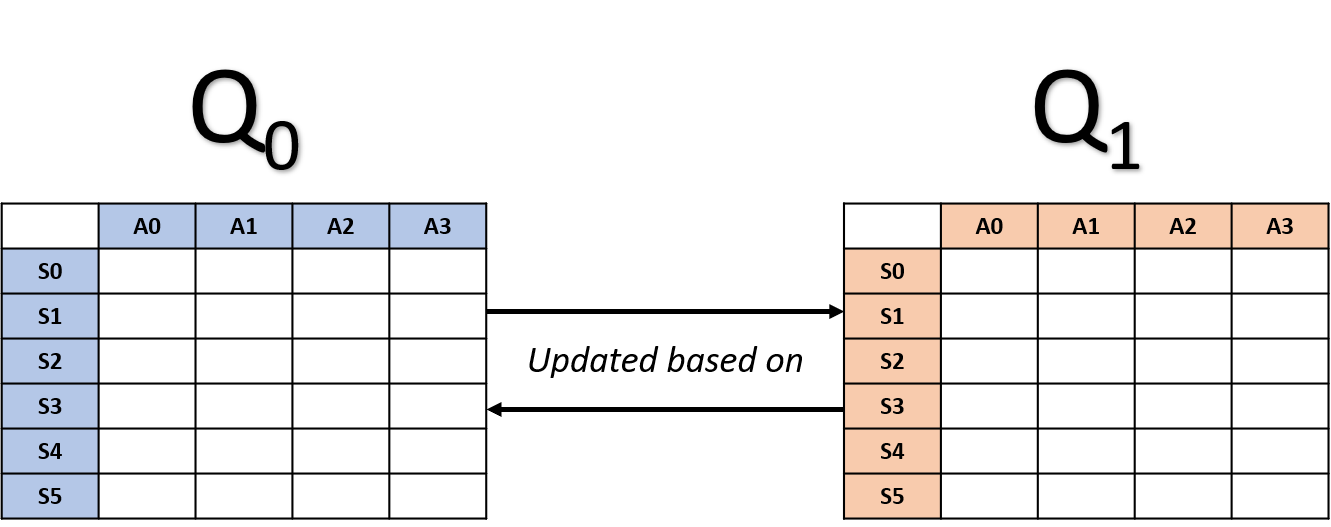
Mises à jour du Double Q-learning
- Sélectionner une table au hasard
Mise à jour de Q0
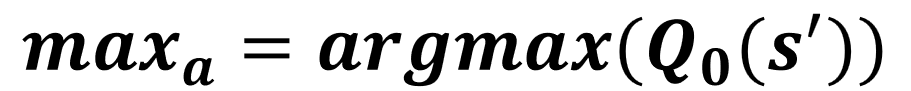
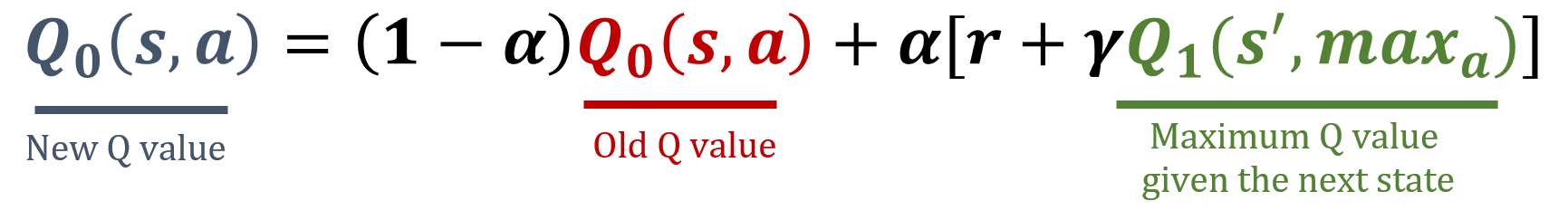
Mise à jour de Q1
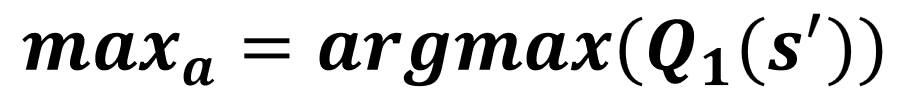
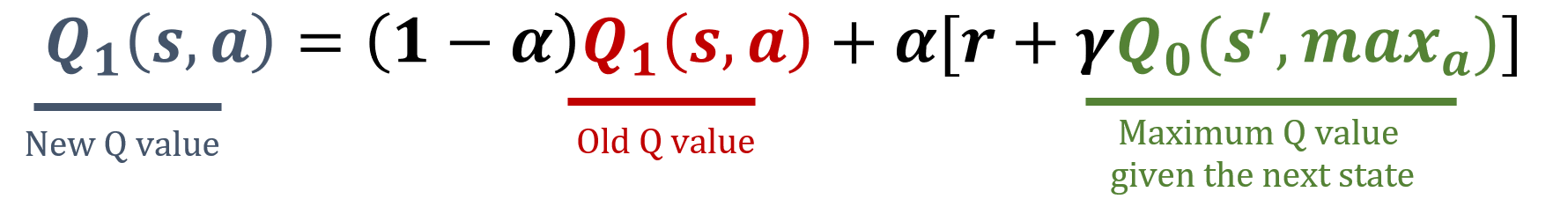
Double Q-learning
- Réduit le biais de surestimation
- Alterne les mises à jour entre Q0 et Q1
- Les deux tables contribuent à l’apprentissage
Implémentation avec Frozen Lake

Implémenter update_q_tables()
def update_q_tables(state, action, reward, next_state): # Select a random Q-table index (0 or 1) i = np.random.randint(2)# Update the corresponding Q-table best_next_action = np.argmax(Q[i][next_state])Q[i][state, action] = (1 - alpha) * Q[i][state, action] + alpha * (reward + gamma * Q[1-i][next_state, best_next_action])
Politique de l’agent