Fonctions d’action-valeur
Reinforcement Learning avec Gymnasium en Python

Fouad Trad
Machine Learning Engineer
Fonctions d’action-valeur (Q-valeurs)
- Retour attendu de :
- En partant d’un état $s$
- En effectuant l’action $a$
- En suivant la politique
- Estime l’attrait des actions dans chaque état
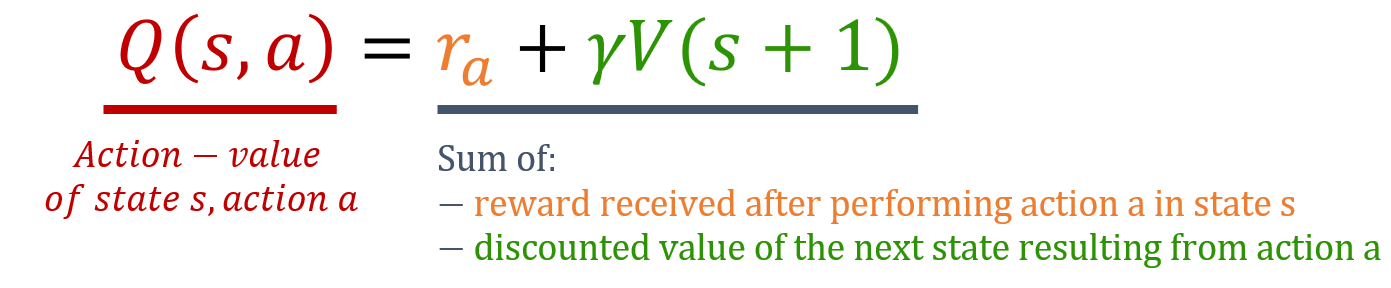
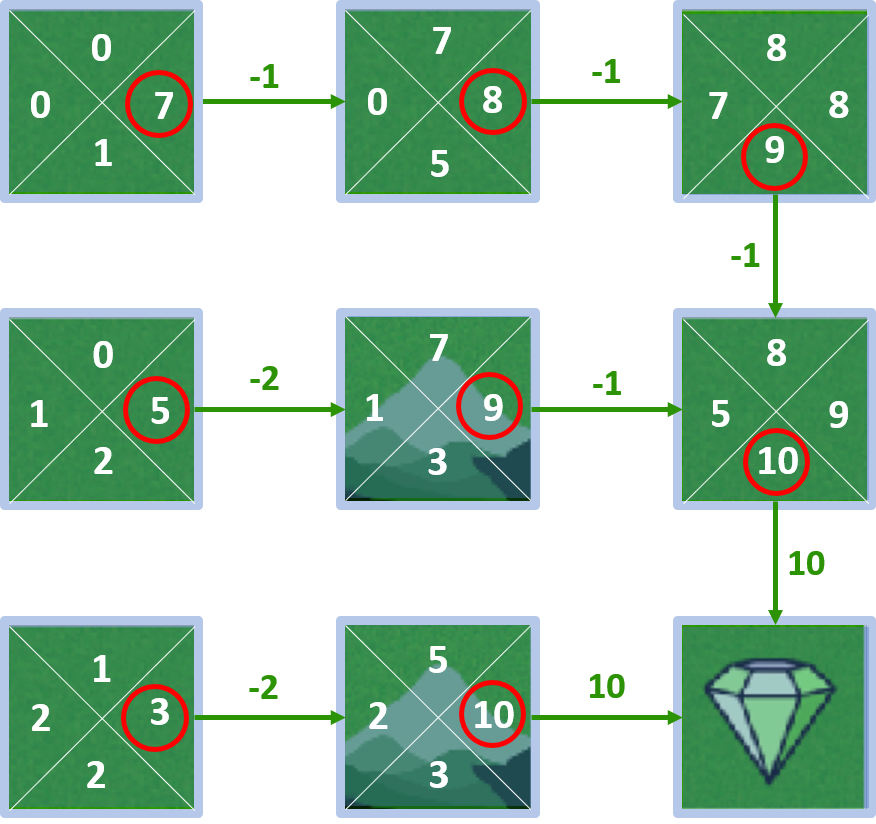
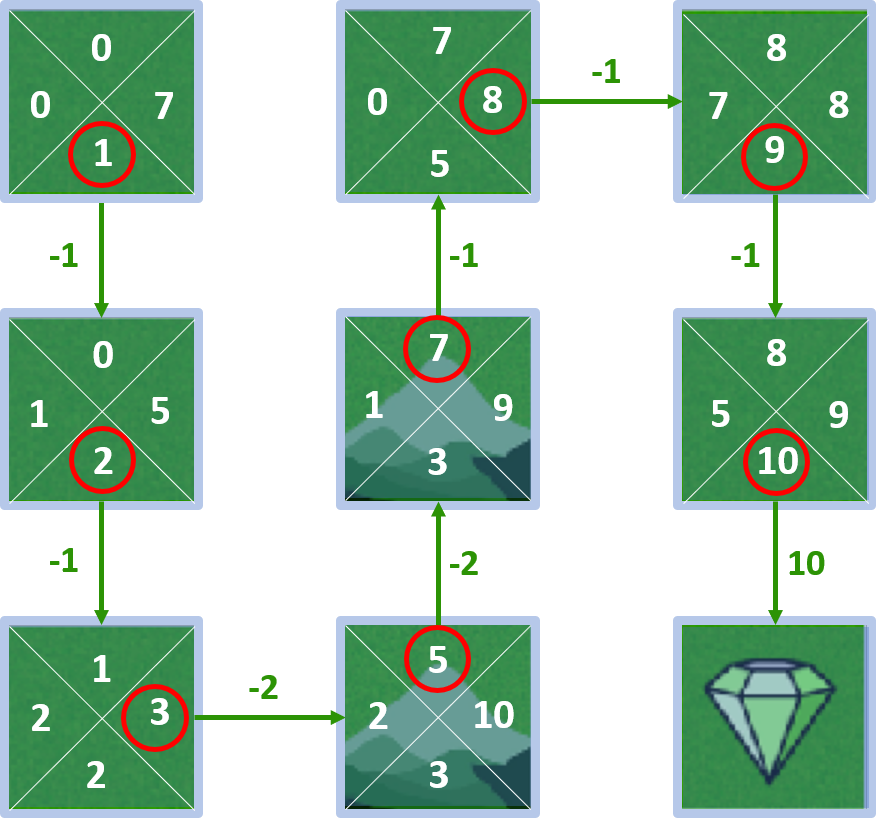
Monde en grille

- Valeurs d’état
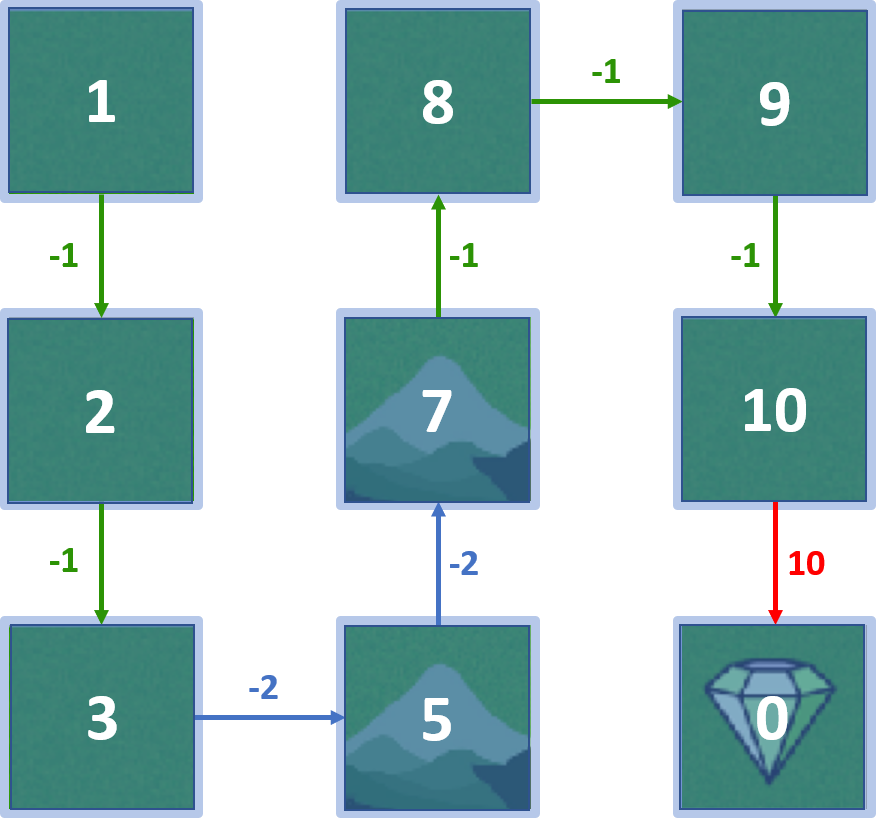
Q-valeurs - état 4
- Agent né à l’état 4
Q-valeurs - état 4
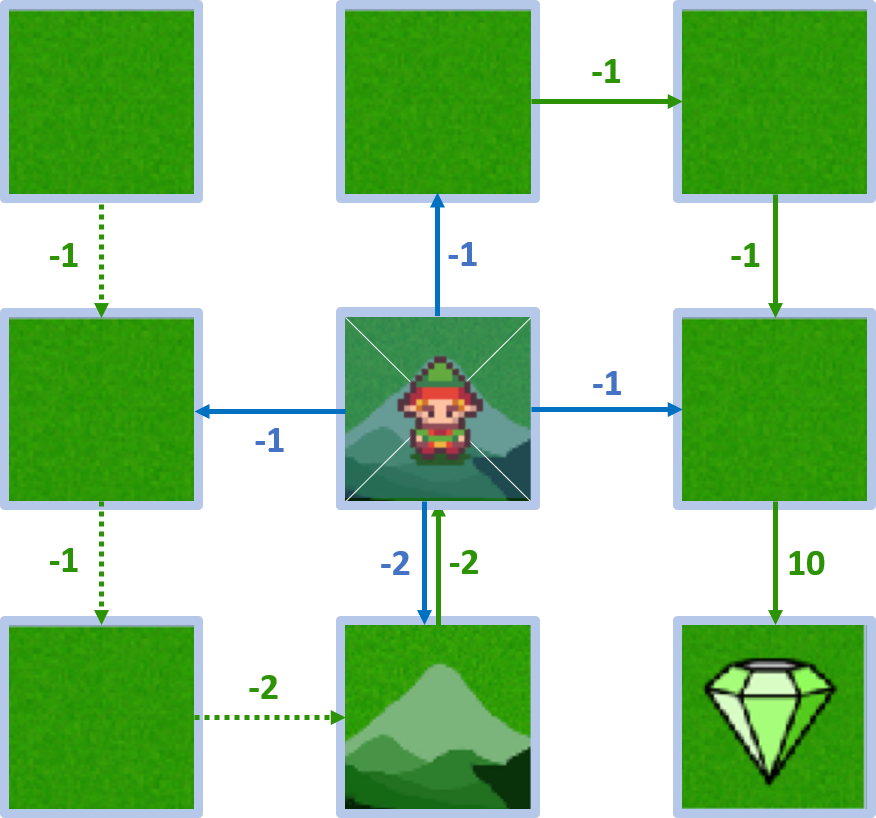
- L’agent peut aller haut, bas, gauche, droite
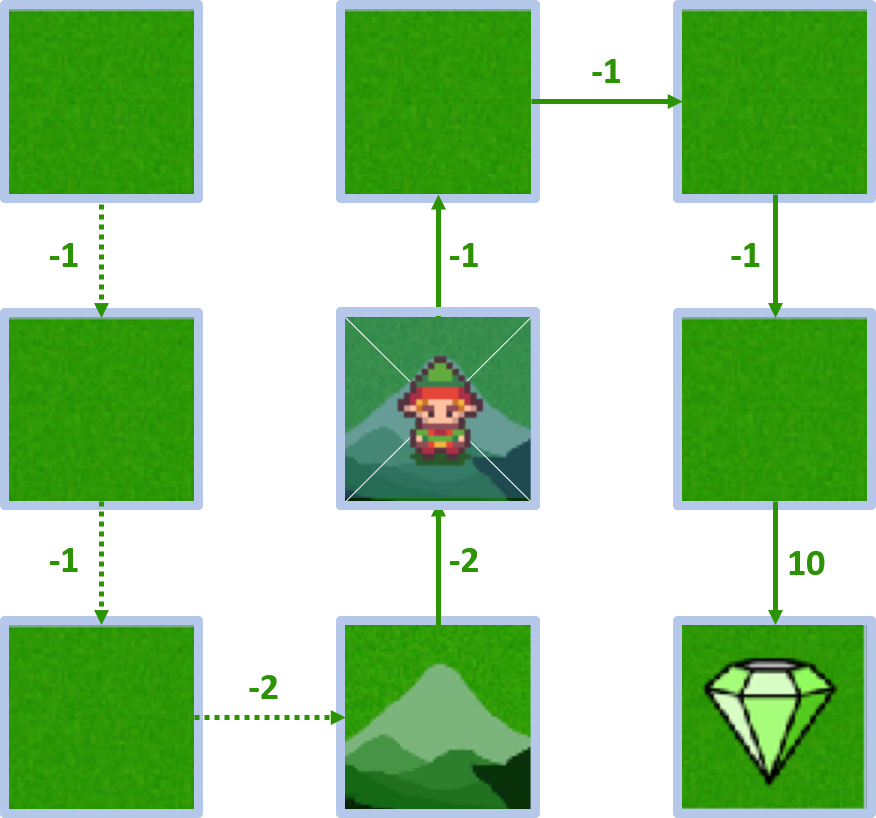
État 4 - action bas
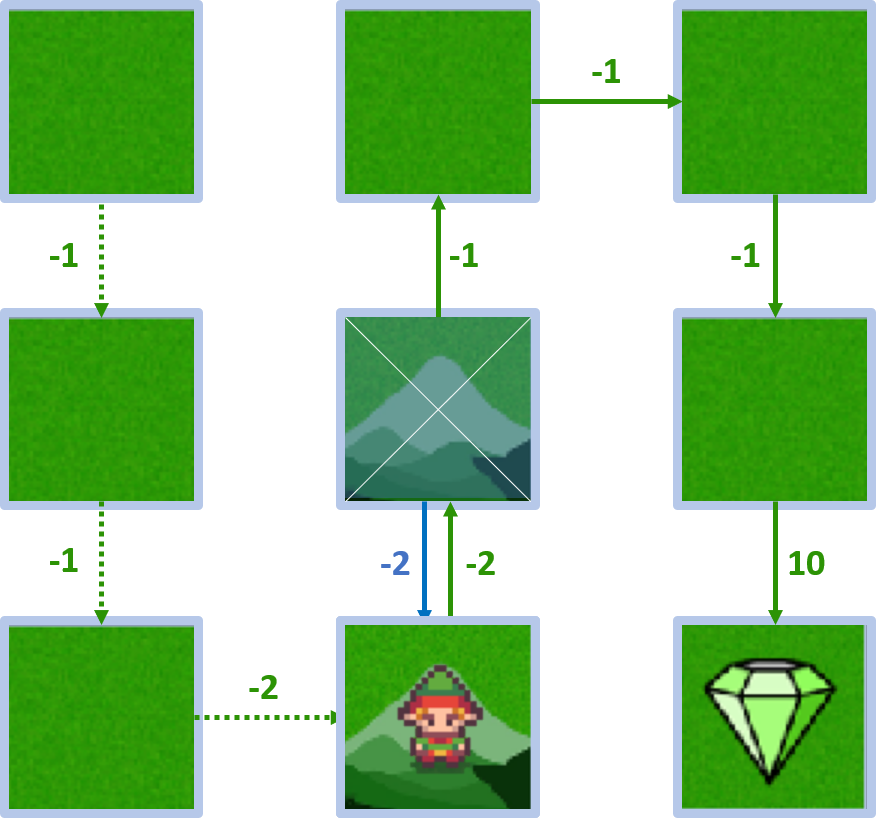
- Récompense : -2, valeur d’état : 5
État 4 - action bas
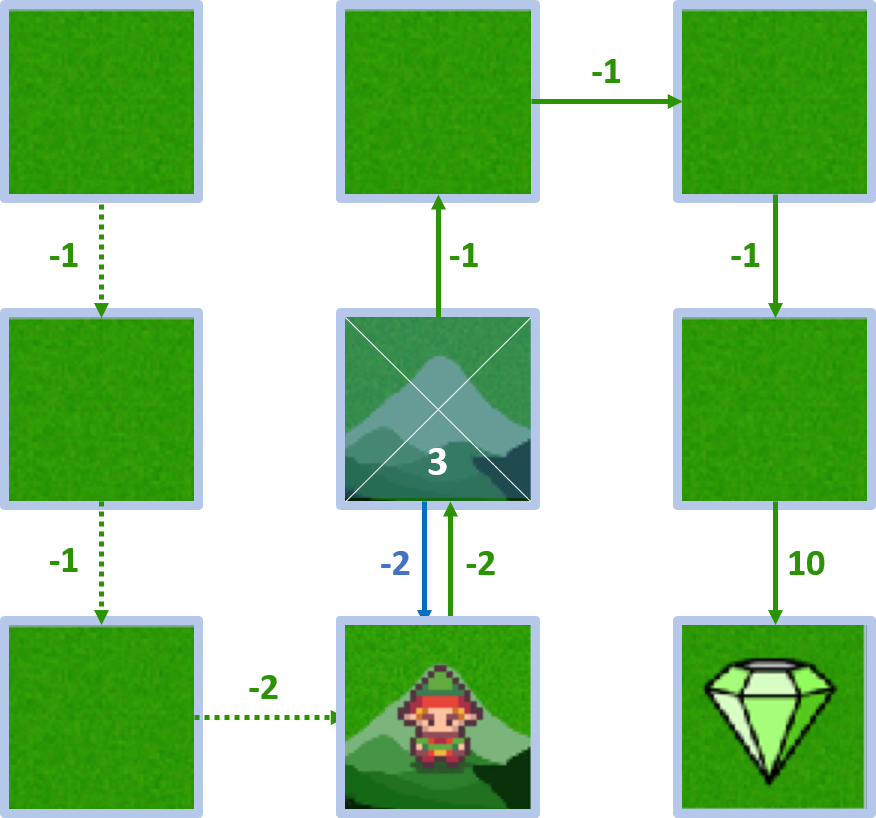
- $Q(4, \text{bas}) = -2 + 1 \times 5 = 3$
État 4 - action gauche
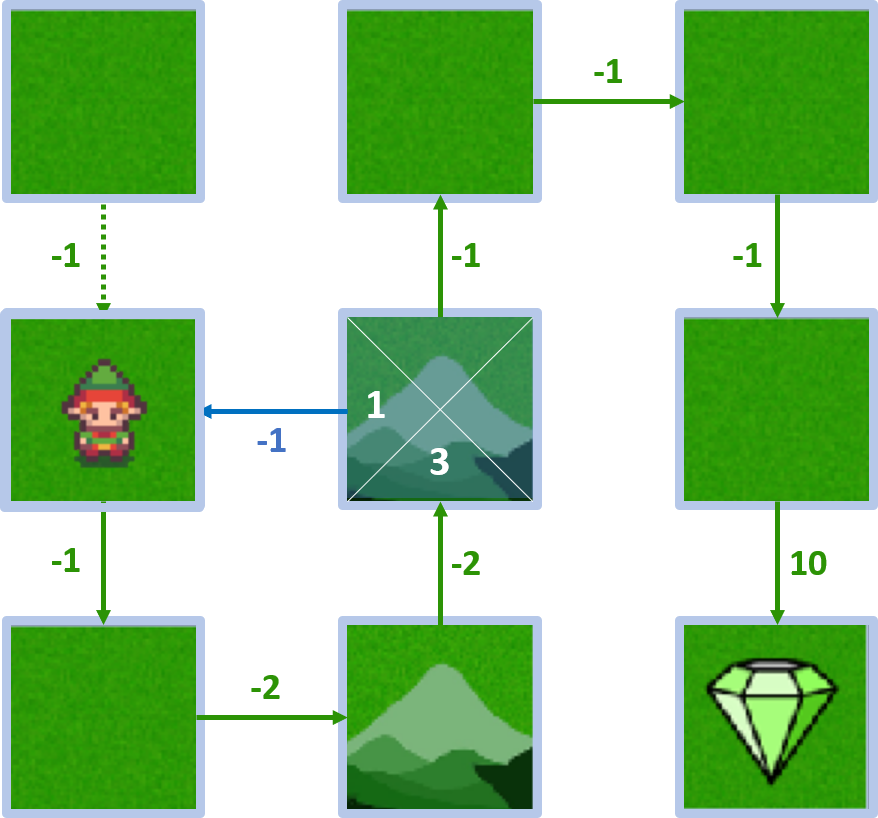
- $Q(4, \text{gauche}) = -1 + 1 \times 2 = 1$
État 4 - action haut
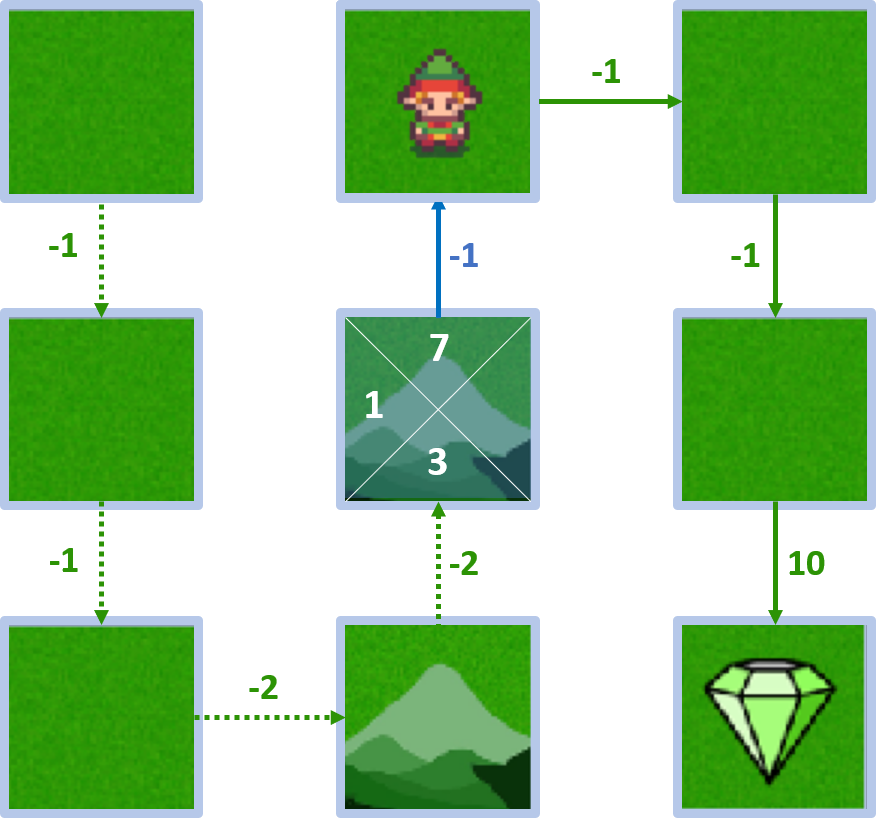
- $Q(4, \text{haut}) = -1 + 1 \times 8 = 7$
État 4 - action droite
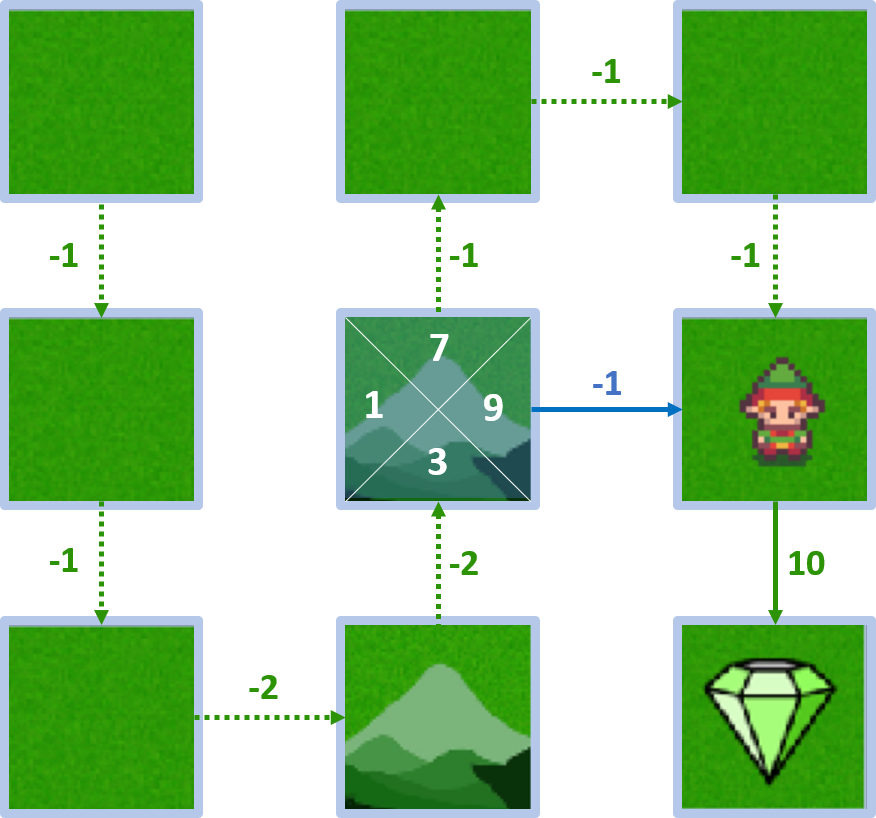
- $Q(4, \text{droite}) = -1 + 1 \times 10 = 9$
Toutes les Q-valeurs
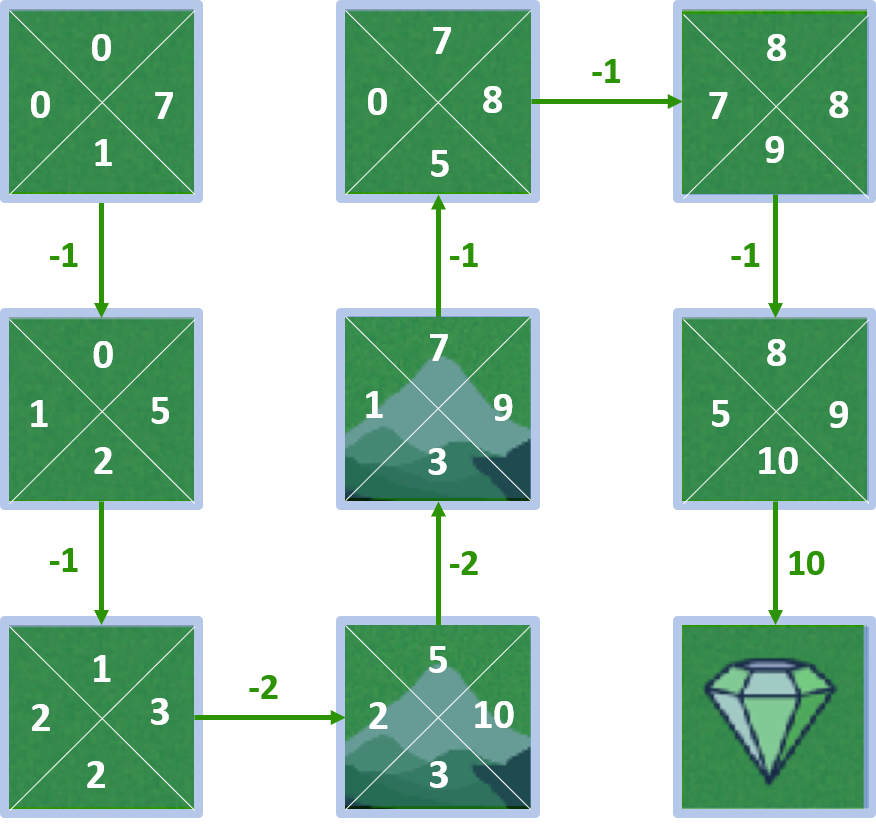
Calcul des Q-valeurs
def compute_q_value(state, action):if state == terminal_state: return None_, next_state, reward, _ = env.unwrapped.P[state][action][0] return reward + gamma * compute_state_value(next_state)
Calcul des Q-valeurs
Améliorer la politique
Améliorer la politique
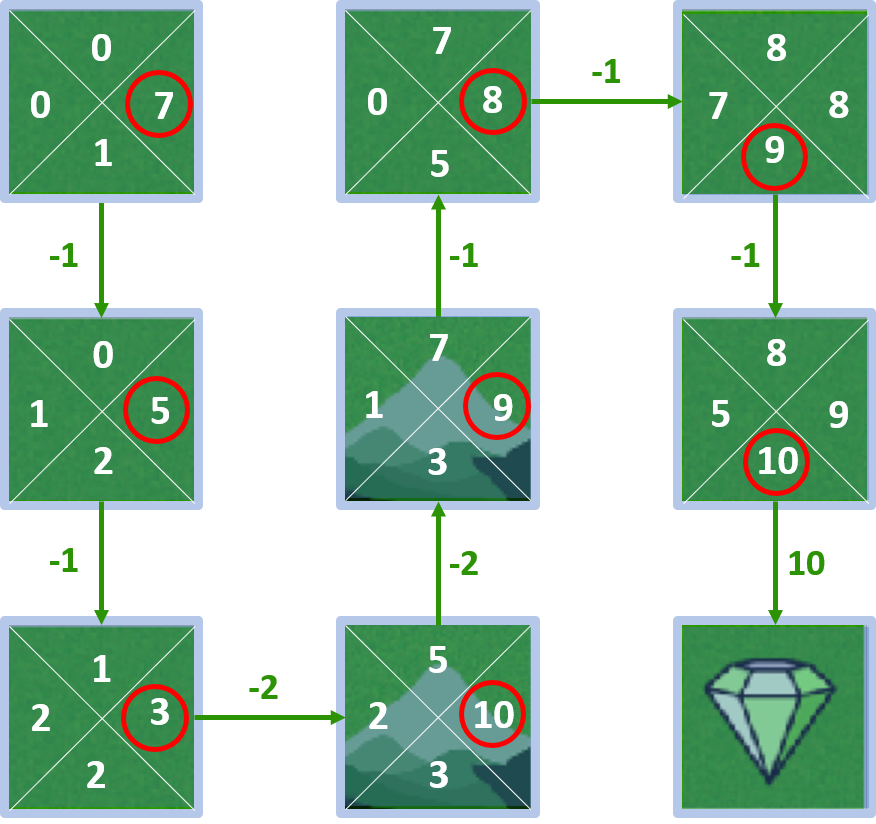
Améliorer la politique
 Ancienne politique
Ancienne politique