SARSA attendu
Reinforcement Learning avec Gymnasium en Python

Fouad Trad
Machine Learning Engineer
SARSA attendu
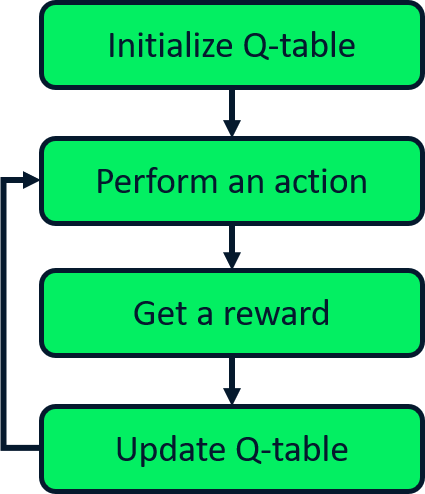
Mise à jour SARSA attendu
SARSA

Q-learning

SARSA attendu
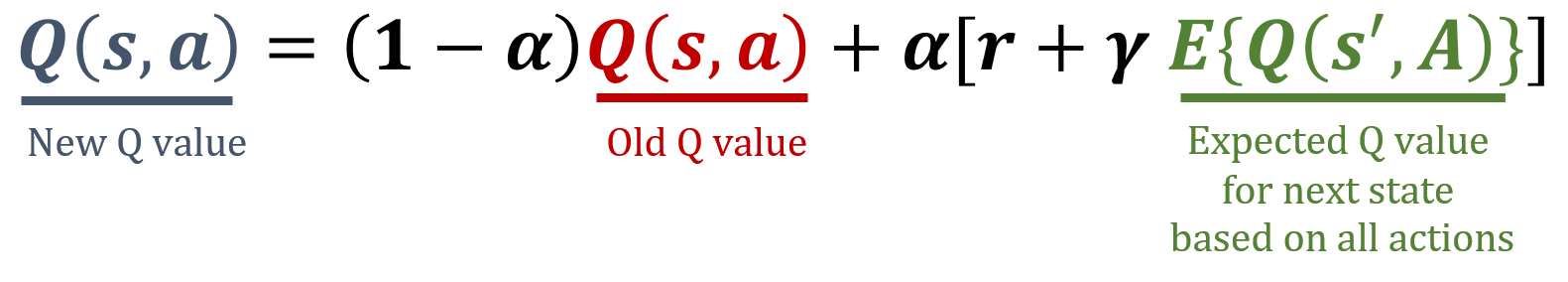
Valeur attendue de l’état suivant
- Prend en compte toutes les actions

- Actions aléatoires → probabilités égales

Implémentation avec Frozen Lake

Règle de mise à jour SARSA attendu
def update_q_table(state, action, next_state, reward):expected_q = np.mean(Q[next_state])Q[state, action] = (1-alpha) * Q[state, action] + alpha * (reward + gamma * expected_q)
Politique de l’agent