Itération de politique et itération de valeur
Reinforcement Learning avec Gymnasium en Python

Fouad Trad
Machine Learning Engineer
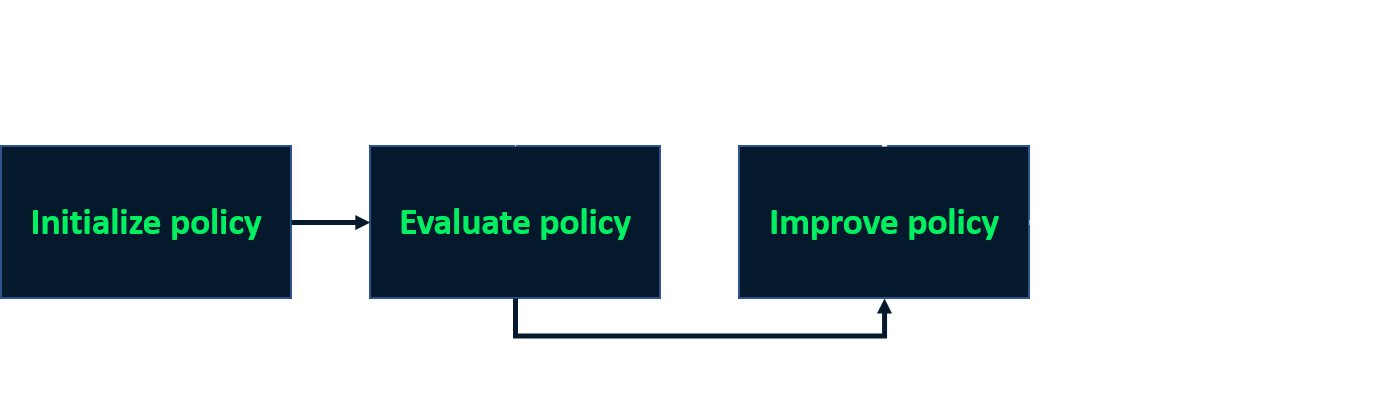
Itération de politique
- Processus itératif pour trouver la politique optimale

Itération de politique
- Processus itératif pour trouver la politique optimale

Itération de politique
- Processus itératif pour trouver la politique optimale
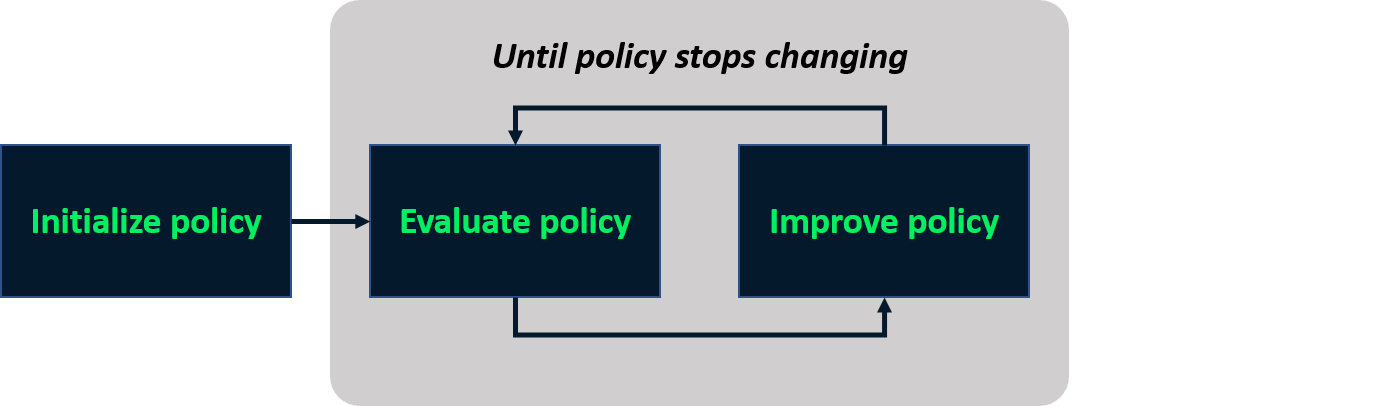
Itération de politique
- Processus itératif pour trouver la politique optimale
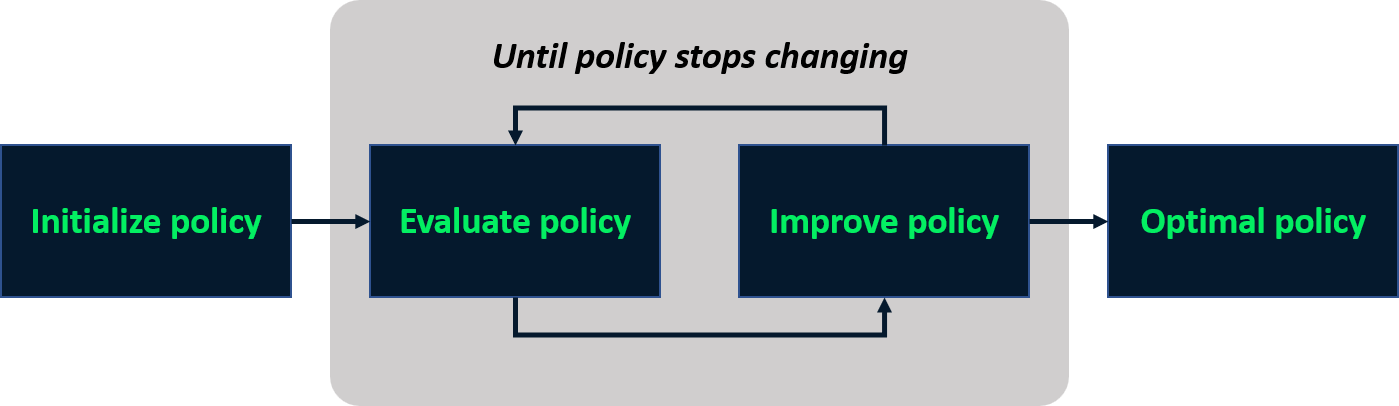
Itération de politique
- Processus itératif pour trouver la politique optimale
Monde en grille
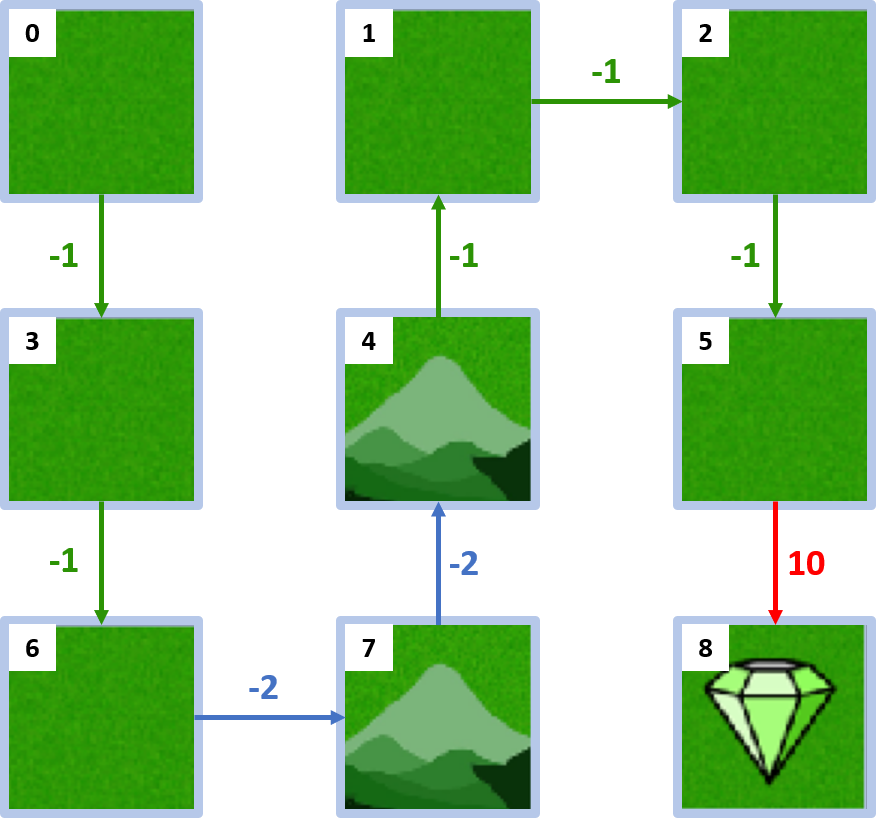
Politique optimale
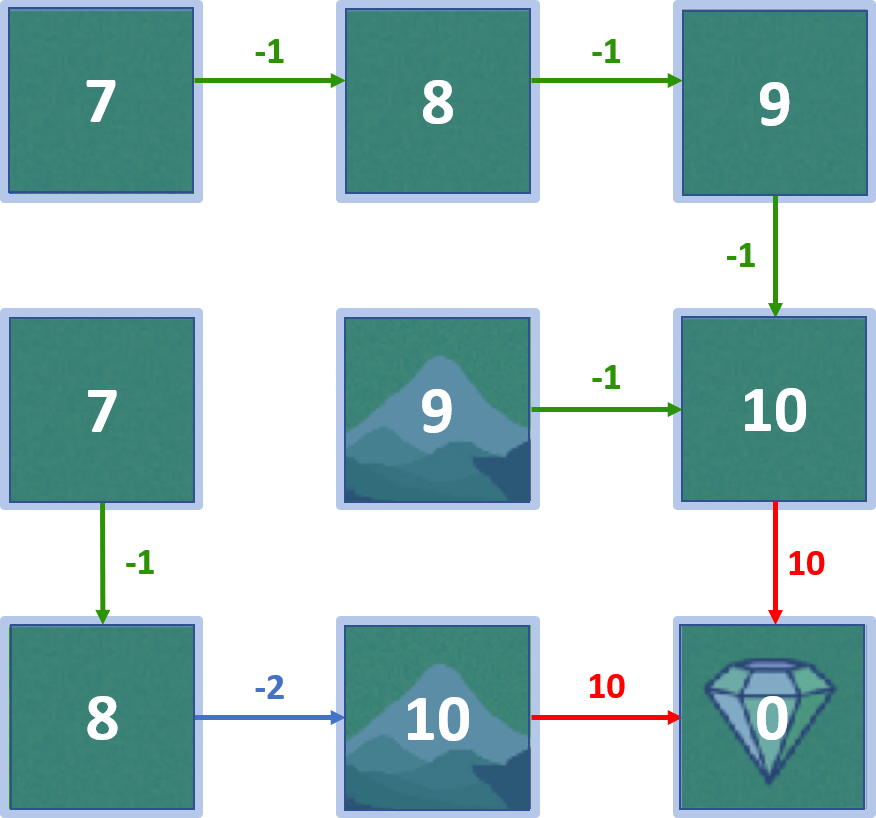
Itération de valeur
- Combine évaluation et amélioration en une étape
- Calcule la fonction de valeur d’état optimale
- En déduit la politique

Itération de valeur
- Combine évaluation et amélioration en une étape.
- Calcule la fonction de valeur d’état optimale
- En déduit la politique

Itération de valeur
- Combine évaluation et amélioration en une étape.
- Calcule la fonction de valeur d’état optimale
- En déduit la politique
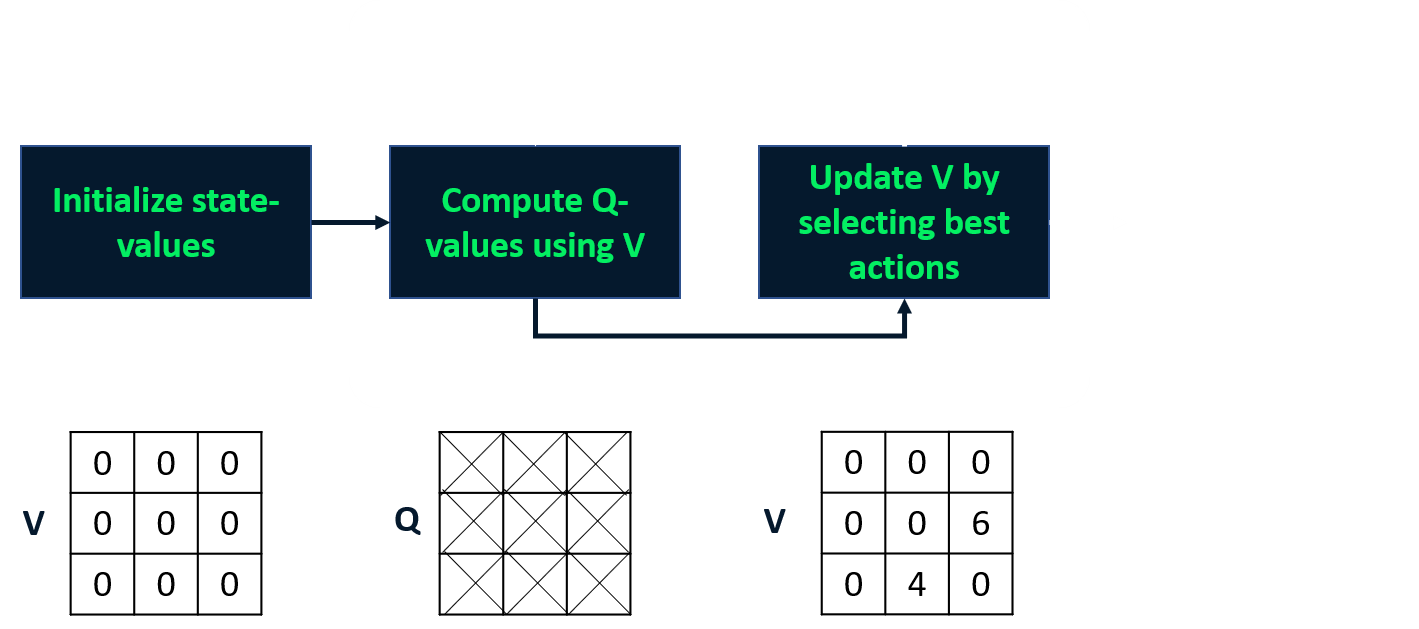
Itération de valeur
- Combine évaluation et amélioration en une étape.
- Calcule la fonction de valeur d’état optimale
- En déduit la politique
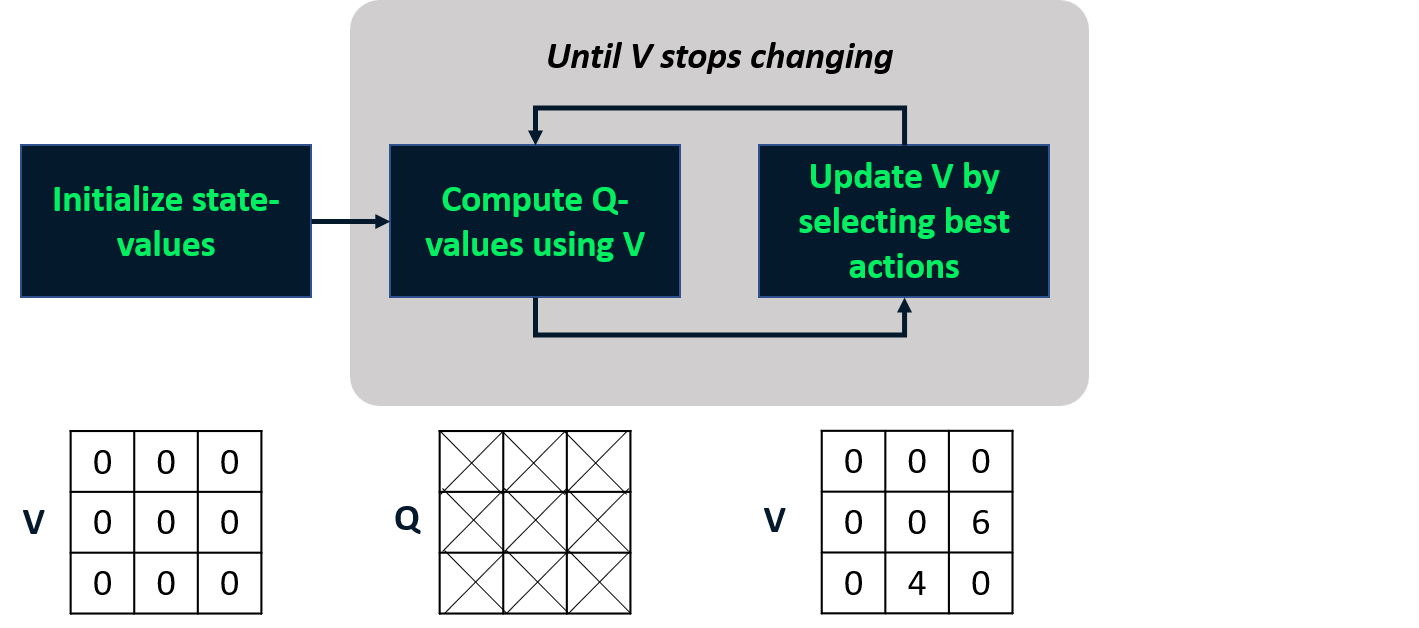
Itération de valeur
- Combine évaluation et amélioration en une étape.
- Calcule la fonction de valeur d’état optimale
- En déduit la politique
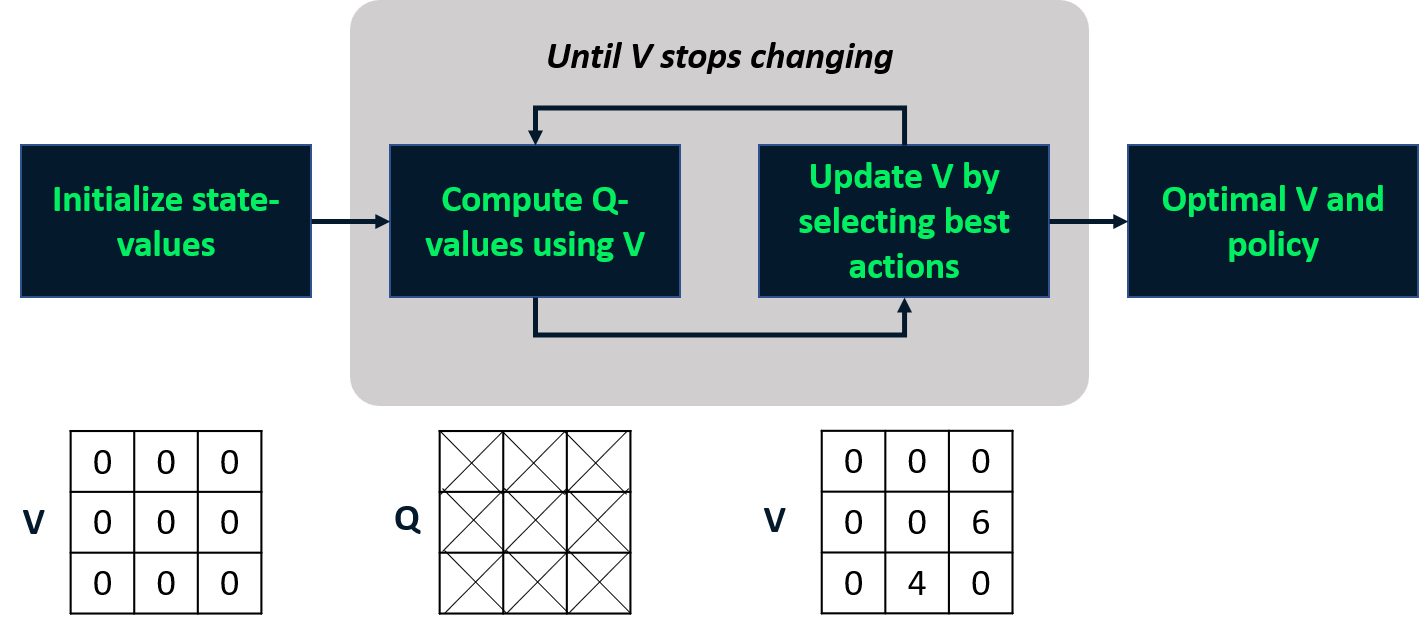
Politique optimale

