Aperçu de la classification de texte
Deep Learning pour le texte avec PyTorch

Shubham Jain
Instructor
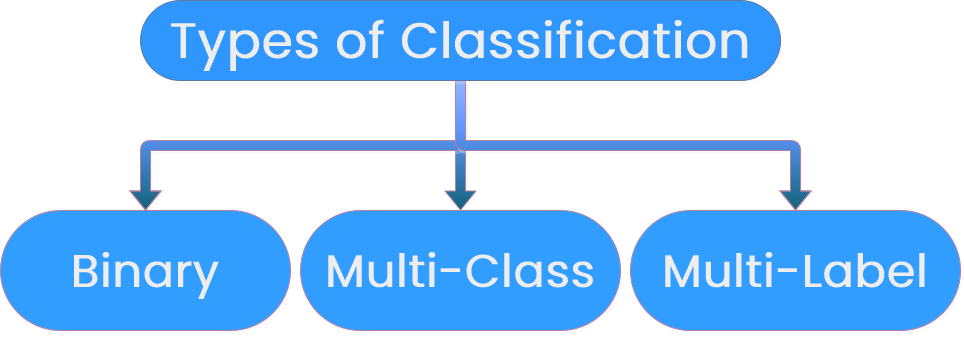
Définition de la classification des textes
"- Attribuer des étiquettes au texte
- Donner du sens aux mots et aux phrases
 {{6}}"
{{6}}"
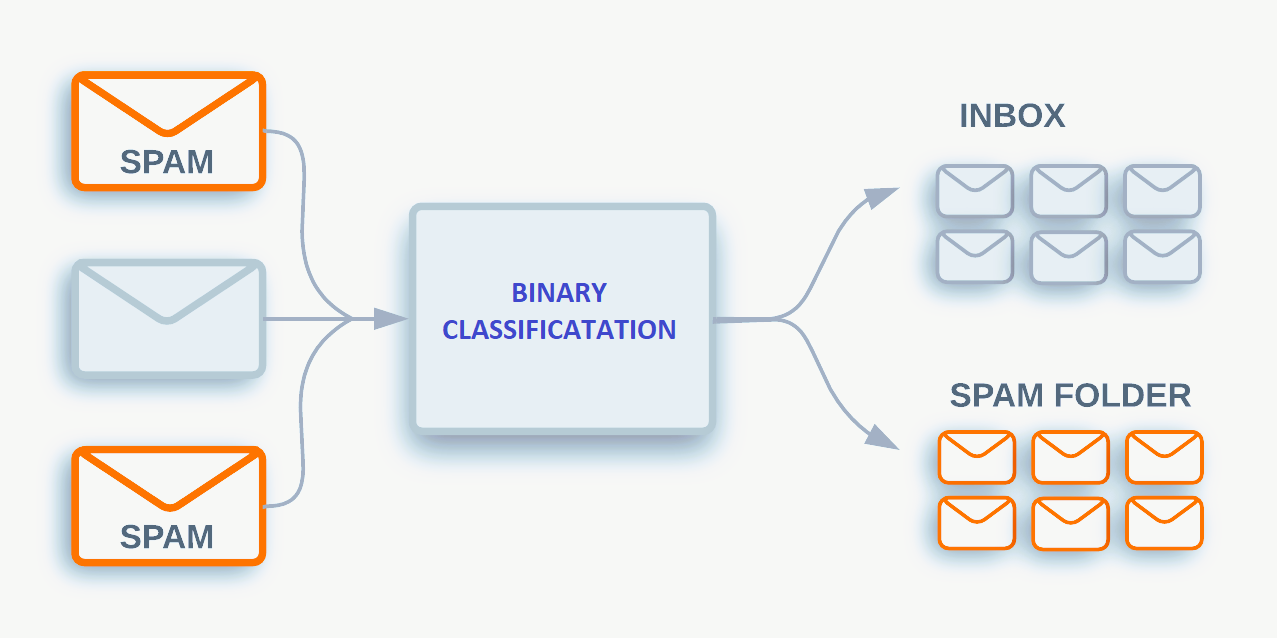
Classification binaire
" {{2}}"
{{2}}"
1 https://storage.googleapis.com/gweb-cloudblog-publish/images/image4_v2LFcq0.max-1200x1200.png
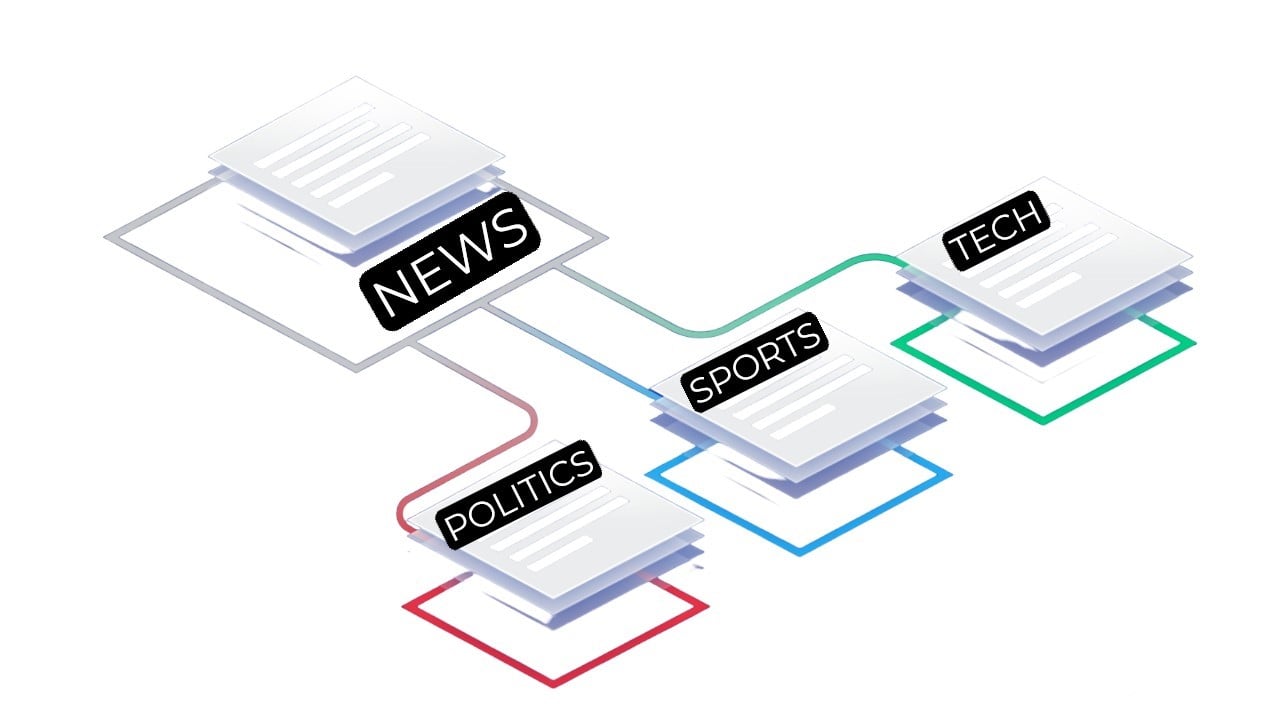
Classification multicatégorie
" {{2}}"
{{2}}"
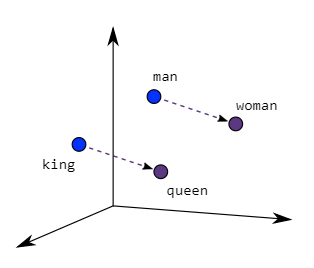
Que sont les embeddings de mots
"
 {{3}}"
{{3}}"

