Encodage des données textuelles
Deep Learning pour le texte avec PyTorch

Shubham Jain
Data Scientist
Encodage de texte
"
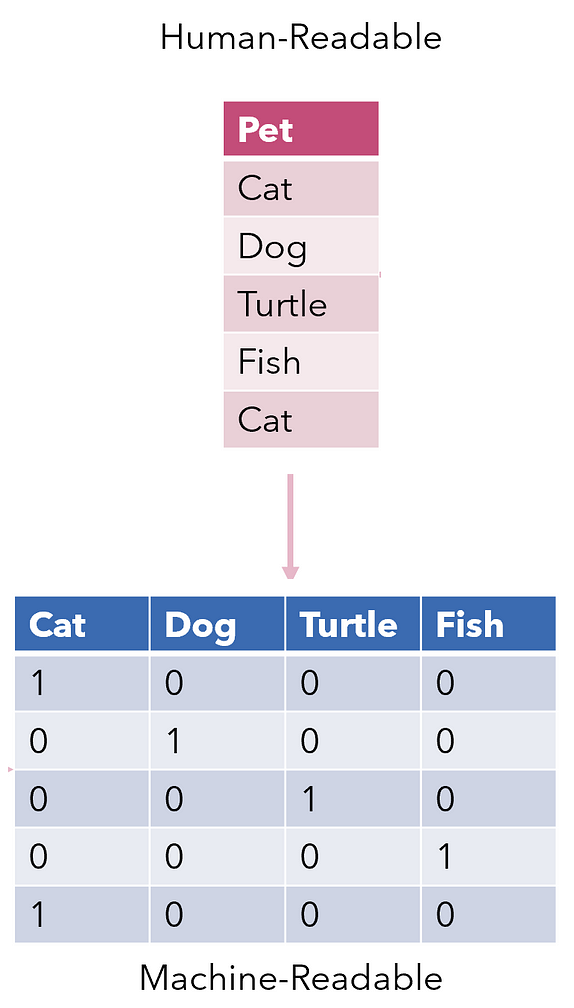
- Convertir le texte en nombres lisibles par la machine
- Permettre l’analyse et la modélisation{{2}}"
" {{3}}"
{{3}}"
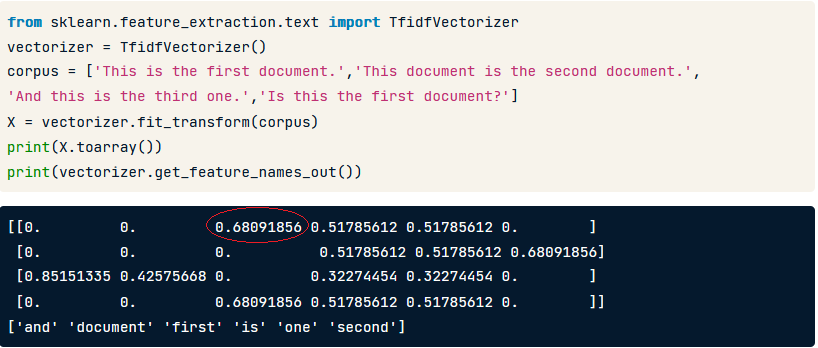
TfidfVectorizer
" "
"

