Arbres boosting de gradient avec XGBoost
Modélisation du risque de crédit en Python

Michael Crabtree
Data Scientist, Ford Motor Company
Arbres de décision
- Produit des prédictions comme la régression logistique
- N’est pas structuré comme une régression
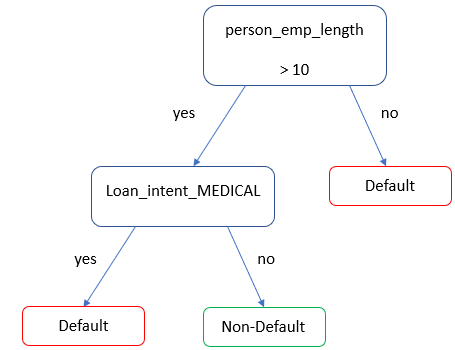
Arbres de décision pour l’état du prêt
- Arbre simple pour prédire la probabilité de défaut
loan_status
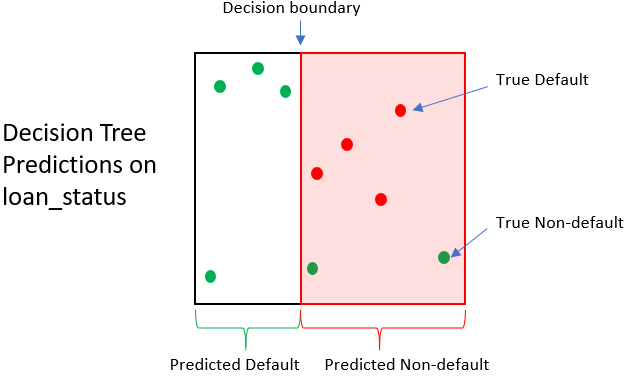
Impact d’un arbre de décision
| Prêt | État réel du prêt | État prédit | Valeur remboursement | Valeur revente | Gain/Perte |
|---|---|---|---|---|---|
| 1 | 0 | 1 | 1 500 $ | 250 $ | -1 250 $ |
| 2 | 0 | 1 | 1 200 $ | 250 $ | -950 $ |
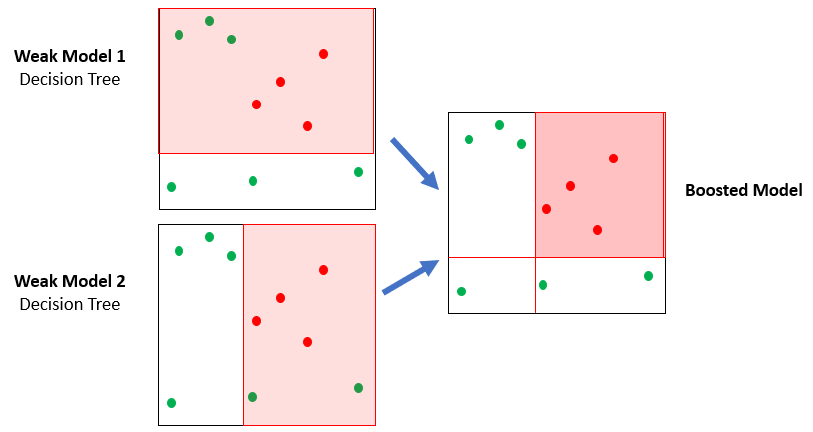
Une forêt d’arbres
- XGBoost utilise de nombreux arbres simples (ensemble)
- Chaque arbre fait un peu mieux qu’un pile ou face