Performance du modèle de crédit
Modélisation du risque de crédit en Python

Michael Crabtree
Data Scientist, Ford Motor Company
Score d’accuracy du modèle
- Calculer l’accuracy
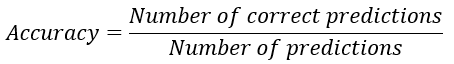
- Utiliser la méthode
.score()de scikit-learn
# Vérifier l’accuracy sur les données de test
clf_logistic1.score(X_test,y_test)
0.81
- 81 % des valeurs de
loan_statusprédites correctement
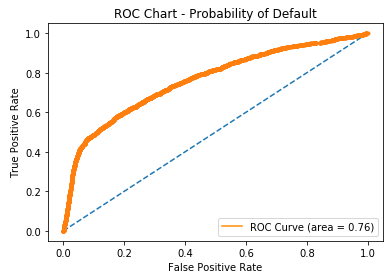
Courbes ROC
- Courbe ROC (Receiver Operating Characteristic)
- Trace le taux de vrais positifs (sensibilité) vs taux de faux positifs (fall-out)
fallout, sensitivity, thresholds = roc_curve(y_test, prob_default)
plt.plot(fallout, sensitivity, color = 'darkorange')
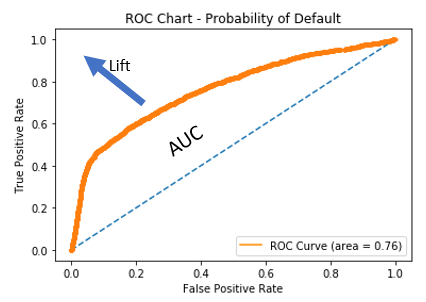
Analyser les courbes ROC
- Aire sous la courbe (AUC) : zone entre la courbe et la prédiction aléatoire
Seuils de défaut
- Seuil : à partir de quelle probabilité il y a défaut
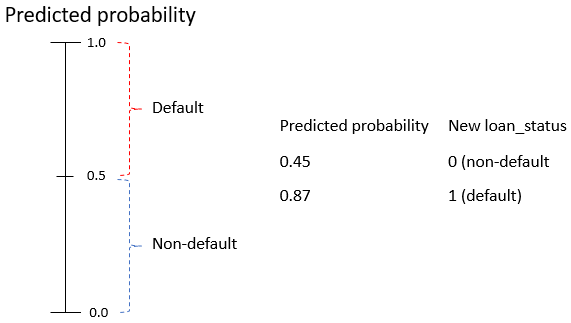
Définir le seuil
- Reclasser les prêts selon un seuil de
0.5
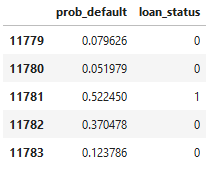
preds = clf_logistic.predict_proba(X_test)
preds_df = pd.DataFrame(preds[:,1], columns = ['prob_default'])
preds_df['loan_status'] = preds_df['prob_default'].apply(lambda x: 1 if x > 0.5 else 0)
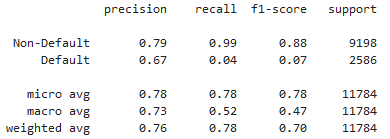
Rapports de classification du crédit
classification_report()dans scikit-learn
from sklearn.metrics import classification_report
classification_report(y_test, preds_df['loan_status'], target_names=target_names)
Choisir des métriques de classification
- Sélectionner et stocker des éléments précis de
classification_report() - Utiliser la fonction
precision_recall_fscore_support()de scikit-learn
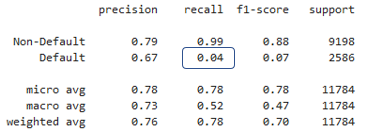
from sklearn.metrics import precision_recall_fscore_support
precision_recall_fscore_support(y_test,preds_df['loan_status'])[1][1]

