Déséquilibre des classes dans les données de prêt
Modélisation du risque de crédit en Python

Michael Crabtree
Data Scientist, Ford Motor Company
Fonction de perte du modèle
- Les arbres Boostés de Gradient dans
xgboostutilisent la log-perte- Objectif : minimiser cette valeur
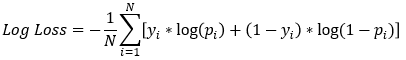
| Statut réel du prêt | Probabilité prédite | Log-perte |
|---|---|---|
| 1 | 0,1 | 2,3 |
| 0 | 0,9 | 2,3 |
- Un défaut mal prédit a un impact financier plus négatif
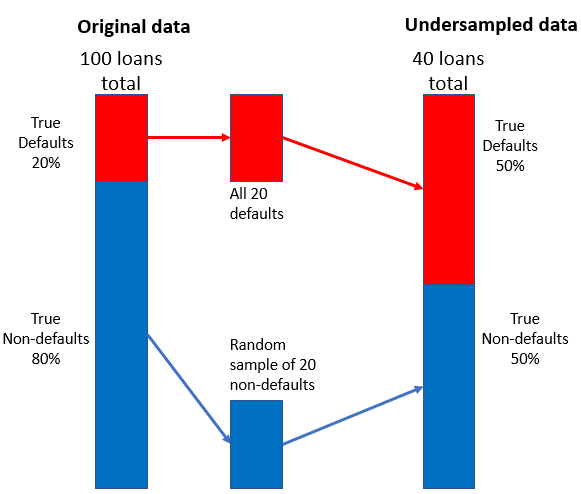
Stratégie de sous-échantillonnage
- Combiner un petit échantillon aléatoire de non-défauts avec les défauts