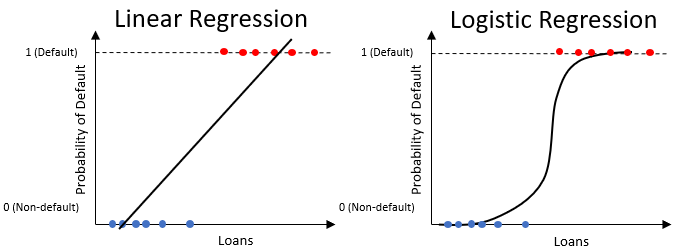
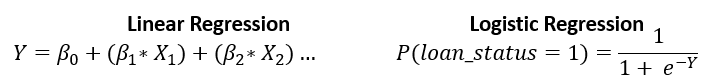Régression logistique pour la probabilité de défaut
Modélisation du risque de crédit en Python

Michael Crabtree
Data Scientist, Ford Motor Company
Prédire des probabilités
- Probabilités de défaut issues du machine learning
- Apprendre à partir des colonnes (features)
- Modèles de classification (défaut, non défaut)
- Deux modèles courants :
- Régression logistique
- Arbre de décision
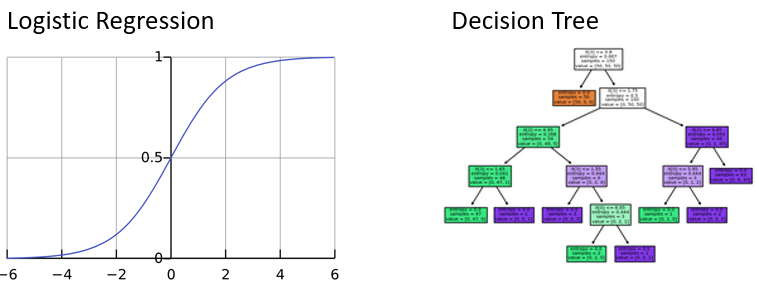
Régression logistique
- Similaire à la régression linéaire, mais produit seulement des valeurs entre
0et1