Comprendre le risque de crédit
Modélisation du risque de crédit en Python

Michael Crabtree
Data Scientist, Ford Motor Company
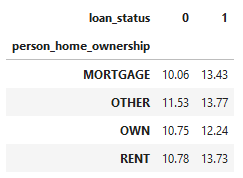
Explorer avec des tableaux croisés
pd.crosstab(cr_loan['person_home_ownership'], cr_loan['loan_status'],
values=cr_loan['loan_int_rate'], aggfunc='mean').round(2)
Explorer avec des visuels
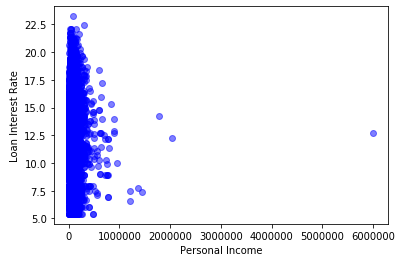
plt.scatter(cr_loan['person_income'], cr_loan['loan_int_rate'],c='blue', alpha=0.5)
plt.xlabel("Personal Income")
plt.ylabel("Loan Interest Rate")
plt.show()