Validation croisée pour les modèles de crédit
Modélisation du risque de crédit en Python

Michael Crabtree
Data Scientist, Ford Motor Company
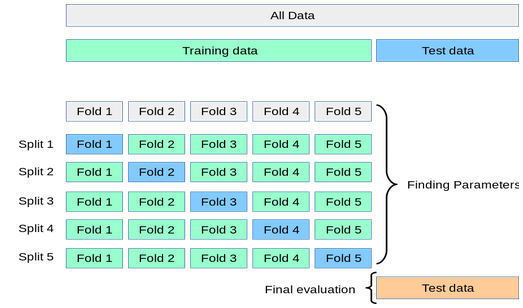
Fonctionnement de la validation croisée
- Traite des parties des données d’entraînement (appelées folds) et teste sur la partie non utilisée
- Test final sur le véritable jeu de test
1 https://scikit-learn.org/stable/modules/cross_validation.html
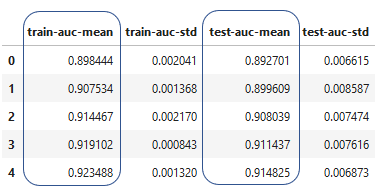
Résultats de la validation croisée
- Crée un DataFrame des valeurs issues de la validation croisée