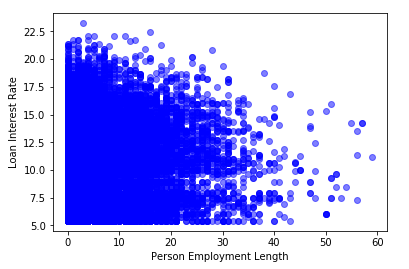
Valeurs aberrantes dans les données de crédit
Modélisation du risque de crédit en Python

Michael Crabtree
Data Scientist, Ford Motor Company
Traitement des données
- Des données préparées entraînent les modèles plus vite
- Améliorent souvent les performances du modèle
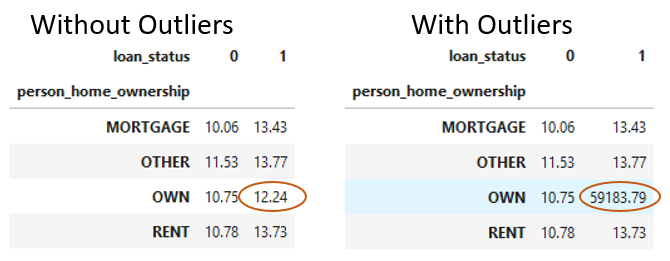
Détecter les valeurs aberrantes avec des tableaux croisés
Détecter visuellement les valeurs aberrantes
Détecter visuellement les valeurs aberrantes
- Histogrammes
- Nuages de points
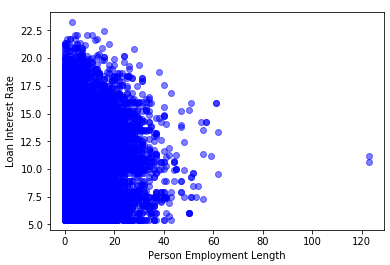
Supprimer les valeurs aberrantes
- Utiliser la méthode
.drop()de Pandas
indices = cr_loan[cr_loan['person_emp_length'] >= 60].index
cr_loan.drop(indices, inplace=True)