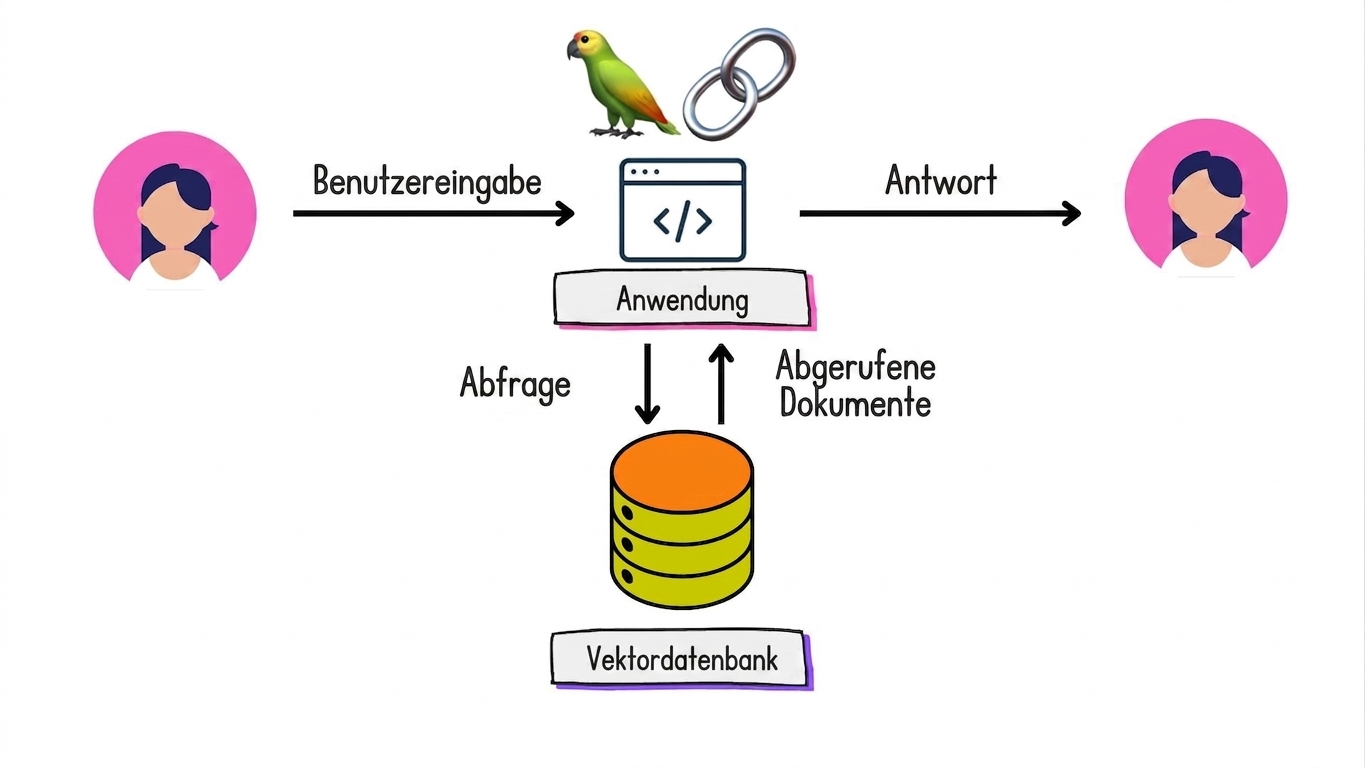
Dokumentenabruf optimieren
Retrieval Augmented Generation (RAG) mit LangChain

Meri Nova
Machine Learning Engineer
Das R in RAG einbauen …
Dense
Chunks als einzelnen Vektor mit nicht-null Komponenten encodieren
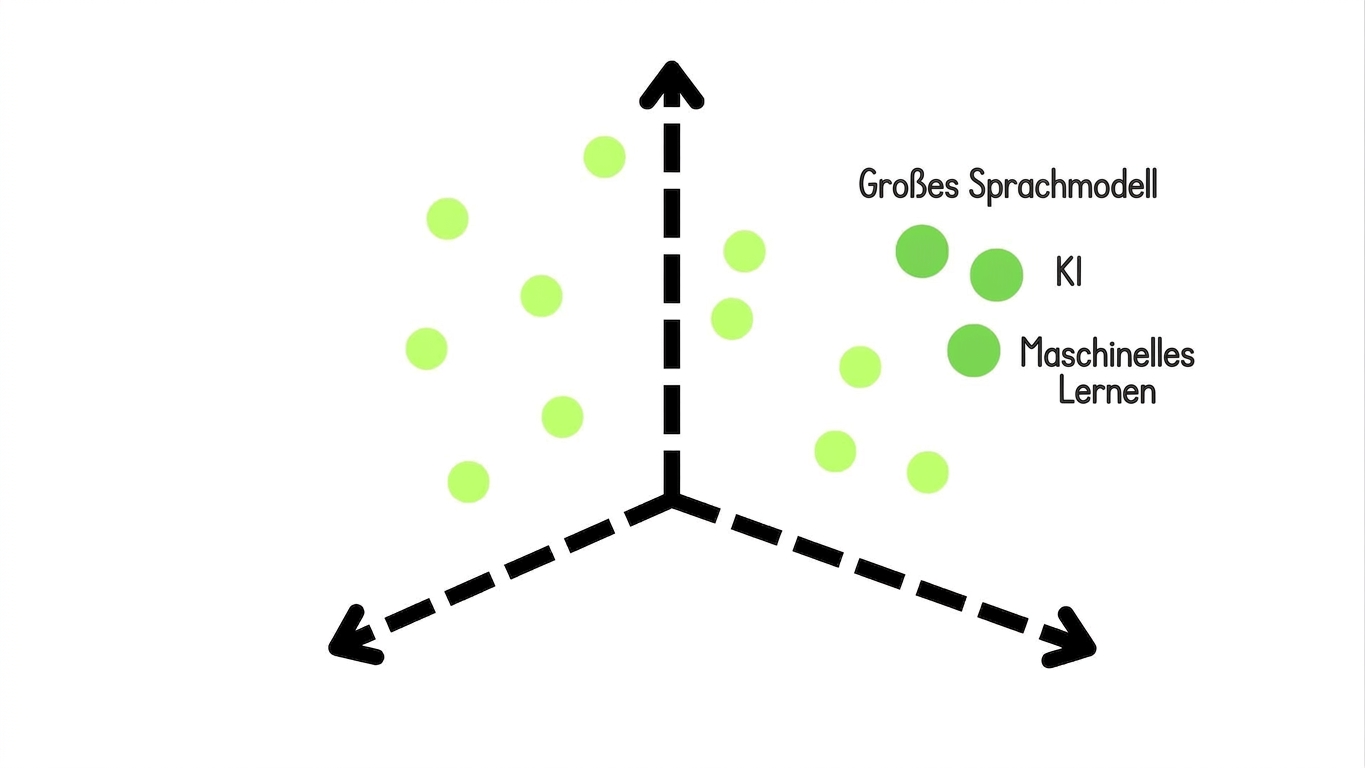
- Vorteile: Erfasst Semantik
- Nachteile: Rechenintensiv
Dense
Chunks als einzelnen Vektor mit nicht-null Komponenten encodieren
- Vorteile: Erfasst Semantik
- Nachteile: Rechenintensiv
Sparse
Encodierung per Wortabgleich mit überwiegend Null-Komponenten
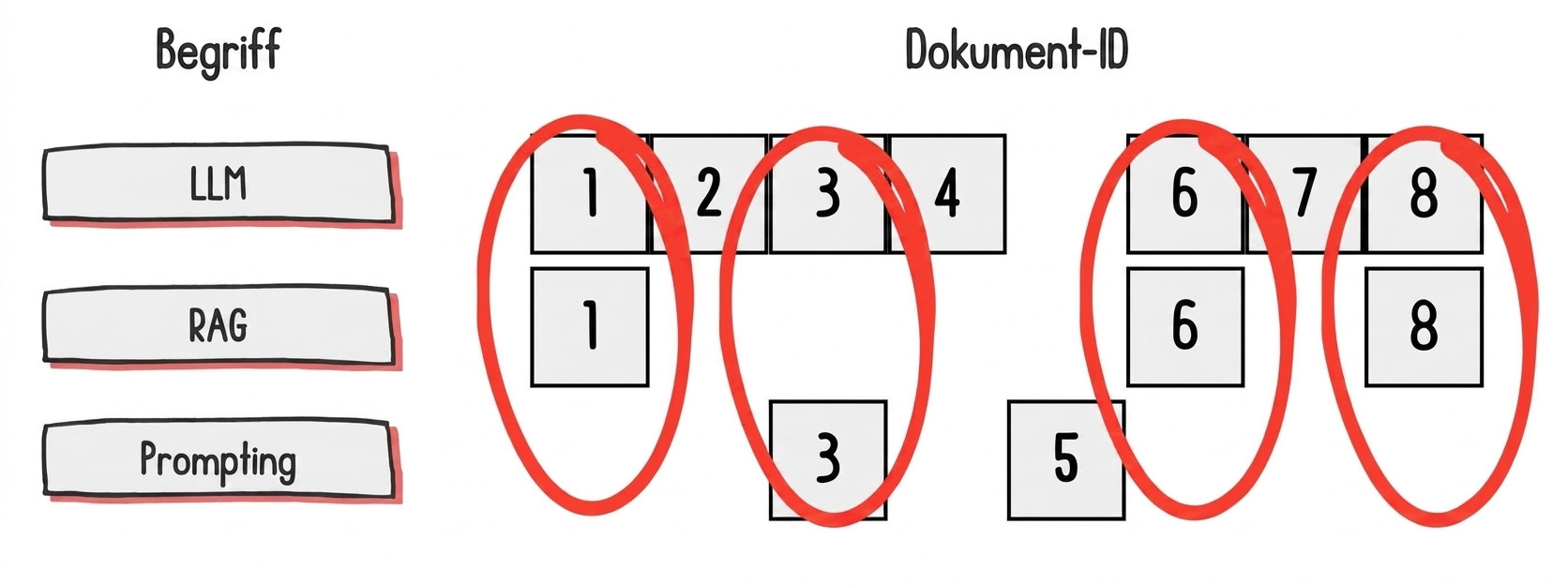
- Vorteile: Präzise, erklärbar, seltene Wörter
- Nachteile: Geringe Generalisierbarkeit
Sparse-Retrieval-Methoden
TF-IDF: Encodiert Dokumente über Wörter, die sie einzigartig machen
BM25: Dämpft den Einfluss hochfrequenter Wörter auf die Encodierung

