Explorative Datenanalyse
End-to-End Machine Learning

Joshua Stapleton
Machine Learning Engineer
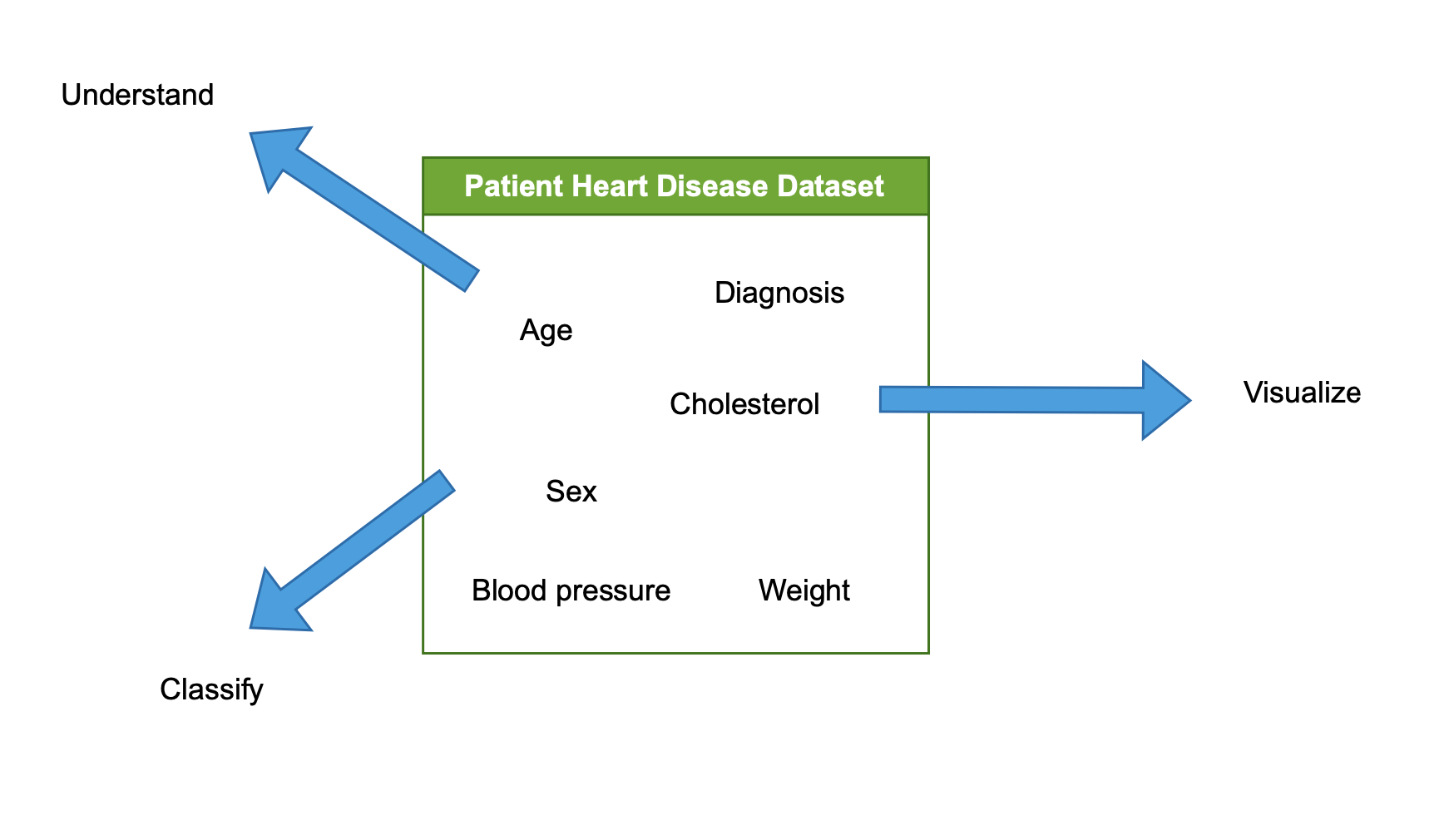
Der EDA‑Prozess
- Datensatz untersuchen und analysieren
- Datensatz verstehen
- Datensatz visualisieren
- Datensatz charakterisieren/klassifizieren
Daten verstehen
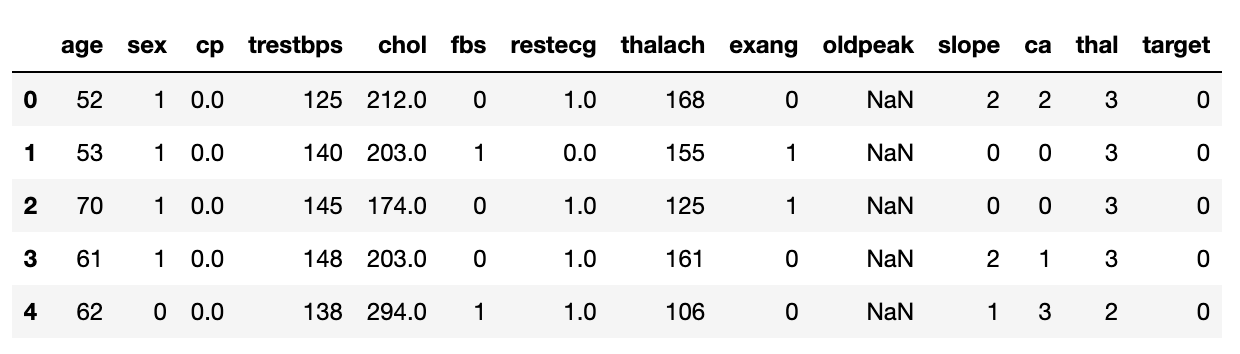
df.head()
- Zeigt die ersten Zeilen
- Gibt einen Überblick über die Struktur
# Print the first 5 rows
print(heart_disease_df.head())
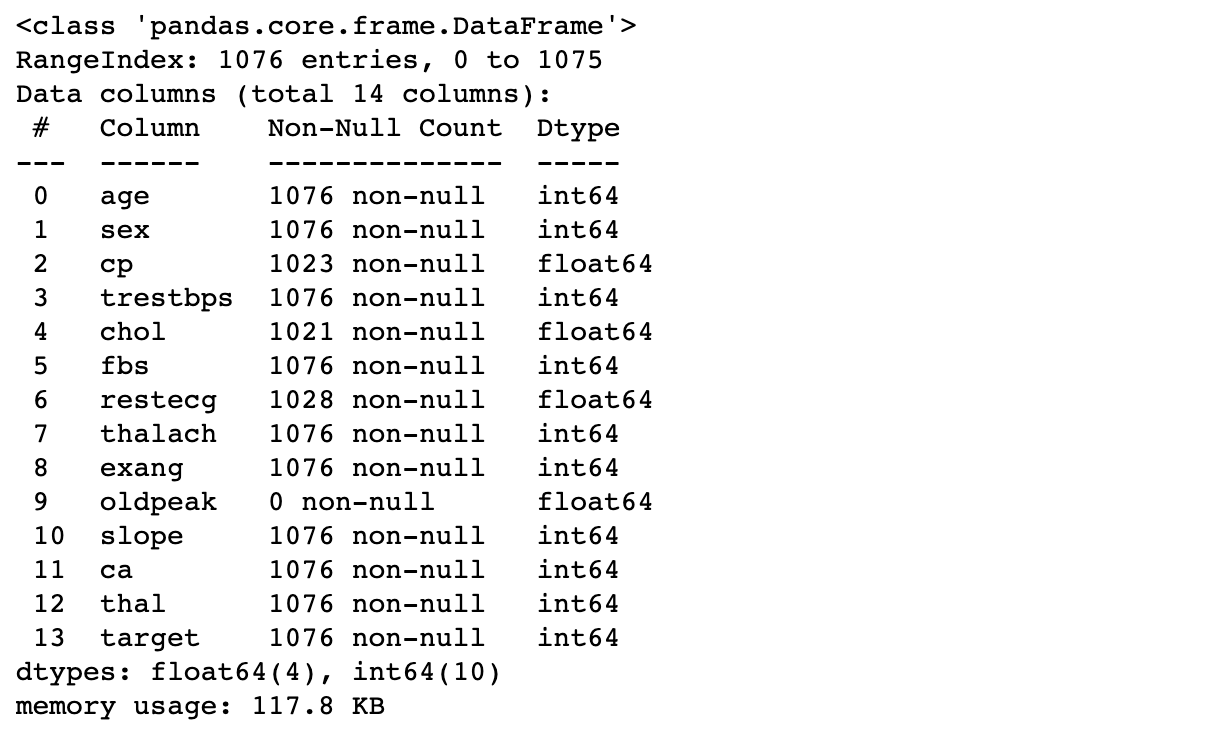
df.info()
- Fasst Features zusammen
- Zeigt Non-Null-Einträge und Typen
# Print out details
print(heart_disease_df.info())
Klassen(un)gleichgewicht
df.value_counts()
- Zählt Vorkommen je Klasse
- Klasse: binäre Herzkrankheit (1/0)
- Wichtig fürs Modeling
# print the class balance
print(heart_disease_df['target'].value_counts(normalize=True))

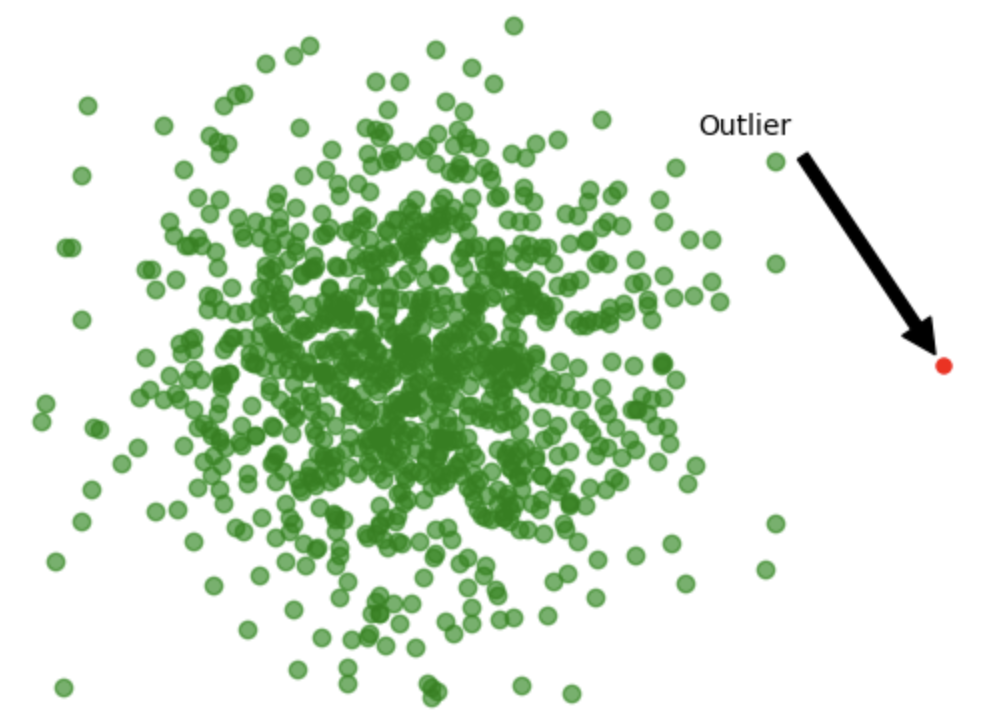
Ausreißer
Daten visualisieren
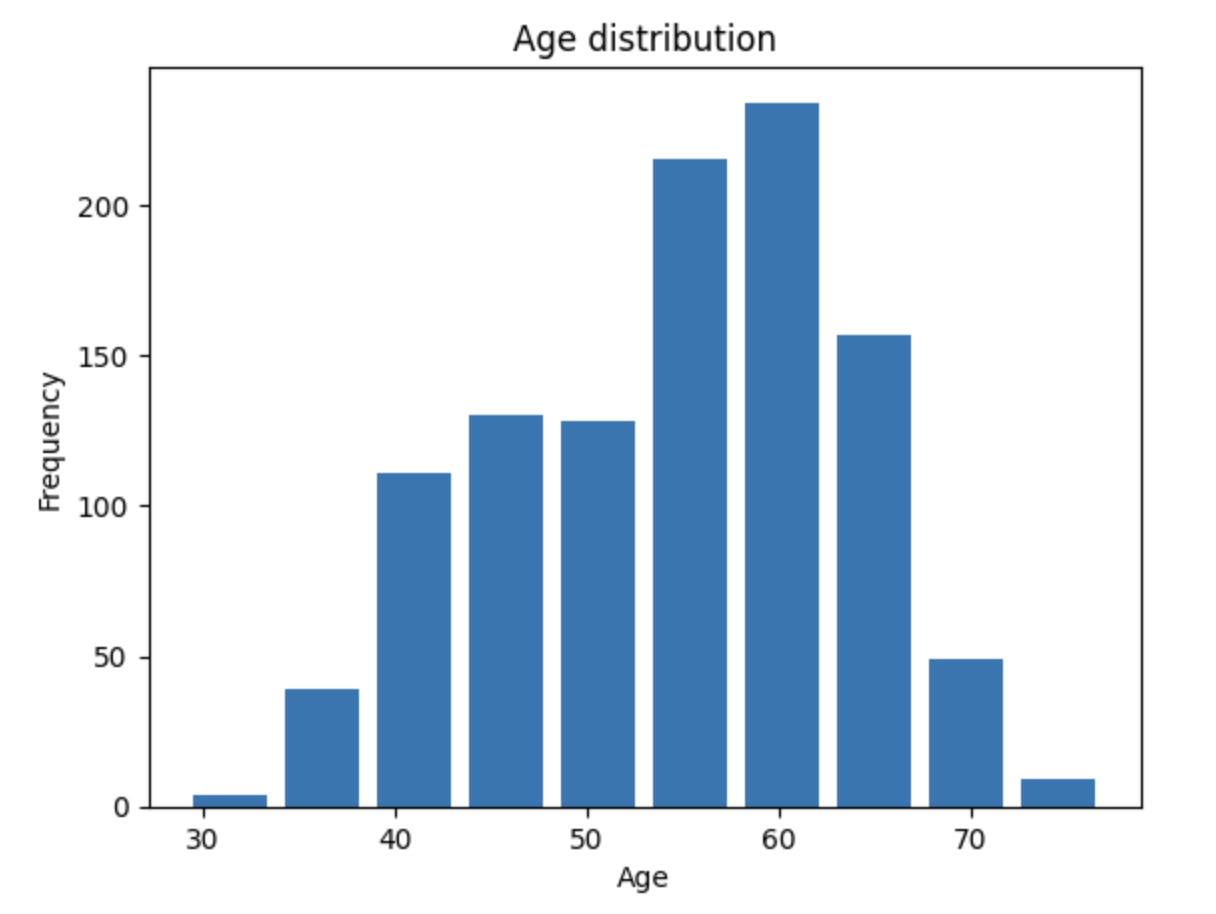
df['age'].plot(kind='hist')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()
1 https://seaborn.pydata.org/tutorial/distributions.html, https://app.datacamp.com/learn/courses/intermediate-data-visualization-with-seaborn

