Modelle bewerten und visualisieren
End-to-End Machine Learning

Joshua Stapleton
Machine Learning Engineer
Accuracy
- Die richtigen Genauigkeitsmetriken sind entscheidend für robuste Bewertung
- Ergebnisse lassen sich leicht fehlinterpretieren oder verschleiern
Standardgenauigkeit:
- Standardgenauigkeit = korrekte Vorhersagen / Gesamtvorhersagen
- Oft wenig hilfreich
Beispiel:
# erreicht ~99% Genauigkeit bei einem unausgewogenen Datensatz mit 99 Positiven und 1 Negativen
for patient_datapoint in heart_disease_dataset:
model.prediction(patient_datapoint) = 'positive'
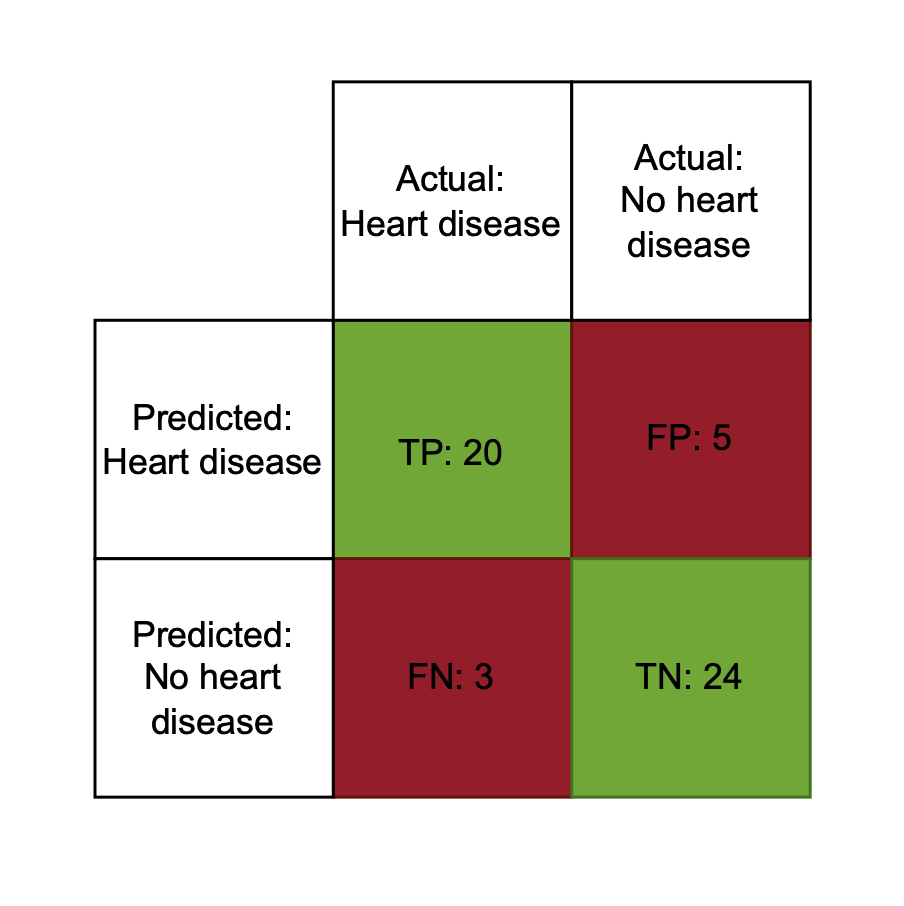
Konfusionsmatrix
True Positives (TP)
- Modellvorhersage = tatsächliche Klasse = positiv
- Modell sagt Herzkrankheit, Patient hat Herzkrankheit
False Positives (FP)
- Vorhersage = positiv, tatsächliche Klasse = negativ
- Modell sagt Herzkrankheit, Patient hat keine
False Negatives (FN)
- Vorhersage = negativ, tatsächliche Klasse = positiv
- Modell sagt keine Herzkrankheit, Patient hat eine
True Negatives (TN)
- Modellvorhersage = tatsächliche Klasse = negativ
- Modell sagt keine Herzkrankheit, Patient hat keine
Balanced Accuracy
- Bessere Metrik als einfache Accuracy für die meisten binären Klassifikationen
- Gewichtet beide Klassen gleich
- Balanced Accuracy = (TP + TN) / 2
from sklearn.metrics import balanced_accuracy_score
# Assume y_test is the true labels and y_pred are the predicted labels
y_pred = model.predict(X_test)
bal_accuracy = balanced_accuracy_score(y_test, y_pred)
print(f"Balanced Accuracy: {bal_accuracy:.2f}")
Balanced Accuracy: 0.85
Konfusionsmatrix: Einsatz
Cross-Validation
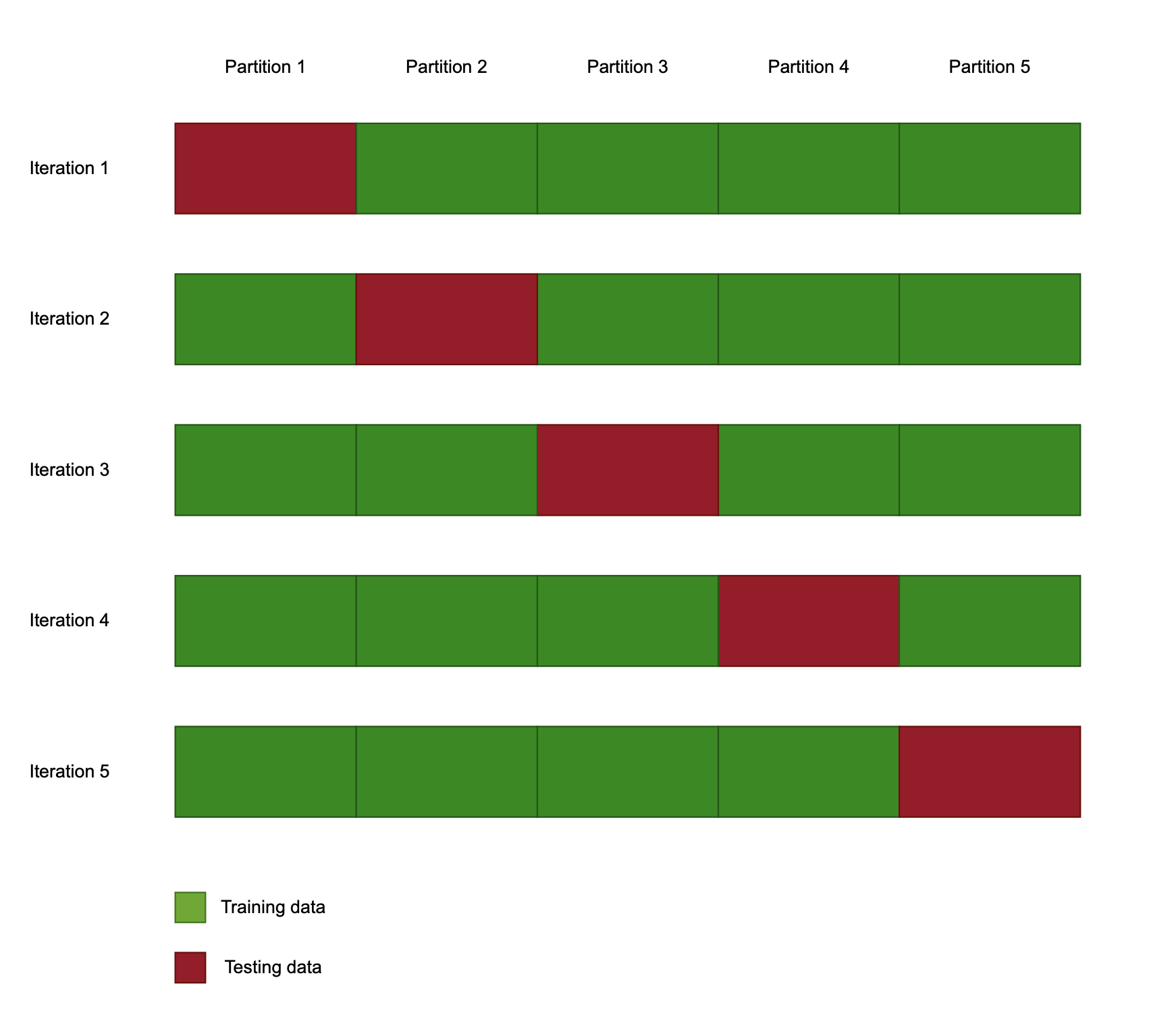
Cross-Validation
- Resampling-Verfahren
- Macht Ergebnisse robuster
k-fold Cross-Validation
- Parameter „k“ = Anzahl Datensatz-Splits
- Für jeden Lauf neuer Train/Test-Split
Cross-Validation: Verwendung
- Einfache k-fold Cross-Validation mit sklearn
- Modellunabhängiges Scoring
Verwendung:
from sklearn.model_selection import cross_val_score, KFold # split the data into 10 equal parts kfold = KFold(n_splits=5, shuffle=True, random_state=42)# get the cross validation accuracy for a given model cv_results = cross_val_score(model, heart_disease_X, heart_disease_y, cv=kfold, scoring='balanced_accuracy')
Hyperparameter-Tuning
Hyperparameter:
- Globaler Modellparameter (ändert sich nicht im Training)
- Zum Verbessern der Leistung anpassen
# Hyperparameters to test
C_values = [0.001, 0.01, 0.1, 1, 10, 100, 1000]
# Manually iterate over the hyperparameters
for C in C_values:
model = LogisticRegression(max_iter=200, C=C)
model.fit(X_train, y_train)
accuracy = cross_val_score(model, X, y, cv=kfold, scoring='balanced_accuracy')
print(f"C = {C}: Bal Acc: {accuracy.mean():.4f} (+/- {accuracy.std():.4f})")
Hyperparameter-Tuning: Beispiel
Beispielausgabe fürs Hyperparameter-Tuning:
C = 0.001: Bal Acc: 0.6200 (+/- 0.0215)
C = 0.01: Bal Acc: 0.7325 (+/- 0.0234)
C = 0.1: Bal Acc: 0.7923 (+/- 0.0202)
C = 1: Bal Acc: 0.8050 (+/- 0.0191)
C = 10: Bal Acc: 0.8034 (+/- 0.0185)
C = 100: Bal Acc: 0.8021 (+/- 0.0187)
C = 1000: Bal Acc: 0.8017 (+/- 0.0188)
Lass uns üben!
End-to-End Machine Learning

