Feature Engineering und -Auswahl
End-to-End Machine Learning

Joshua Stapleton
Machine Learning Engineer
Feature Engineering
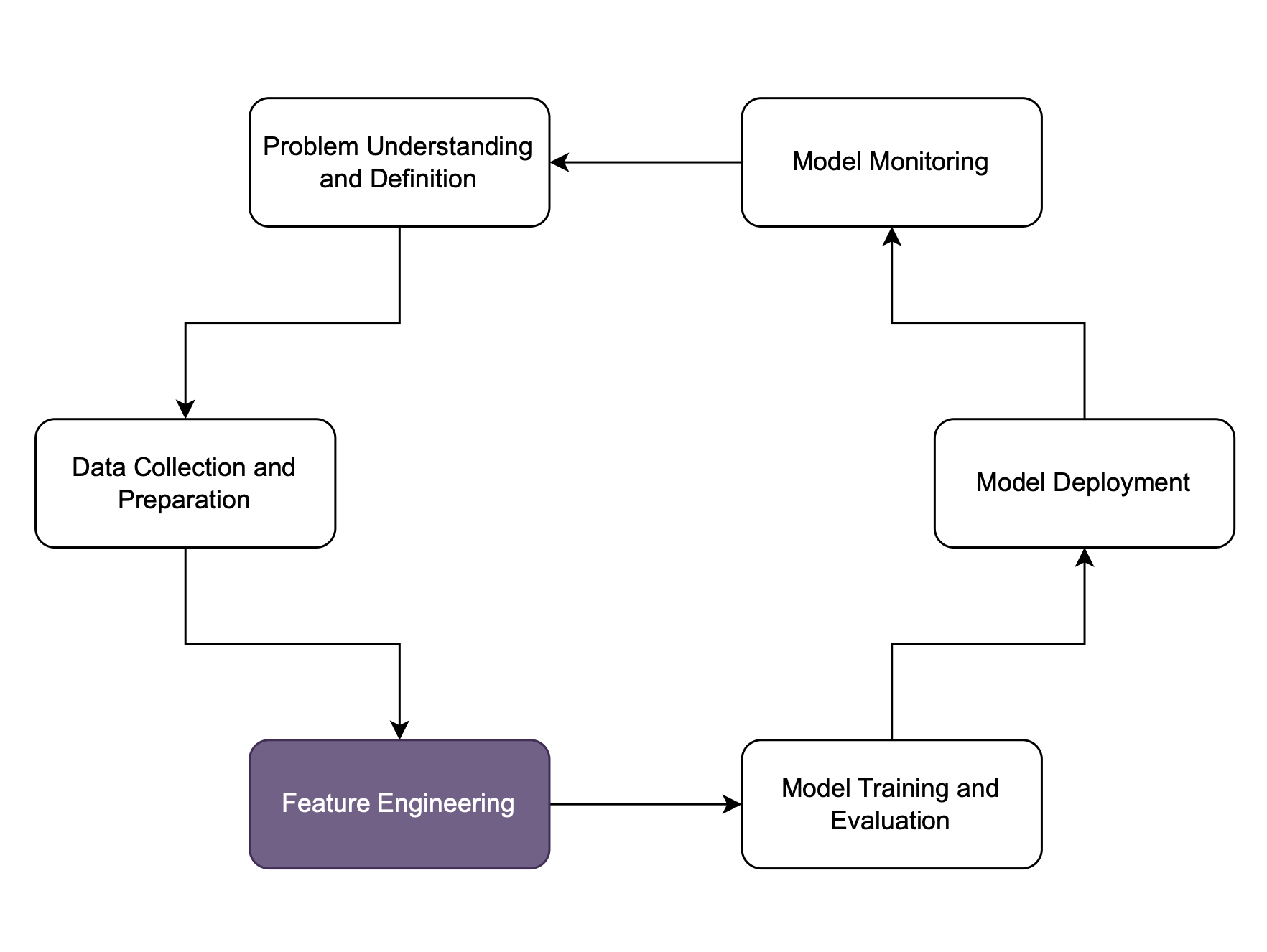
Was macht ein gutes Feature aus?
- Relevante Features nutzen
- Wetter am Tag des Termins beeinflusst die Diagnose nicht

- Dissimile (orthogonale) Features nutzen
- Alter in Monaten und in Jahren ist nicht hilfreich