Monte-Carlo-Methoden
Reinforcement Learning mit Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Rückblick: Model-based Learning
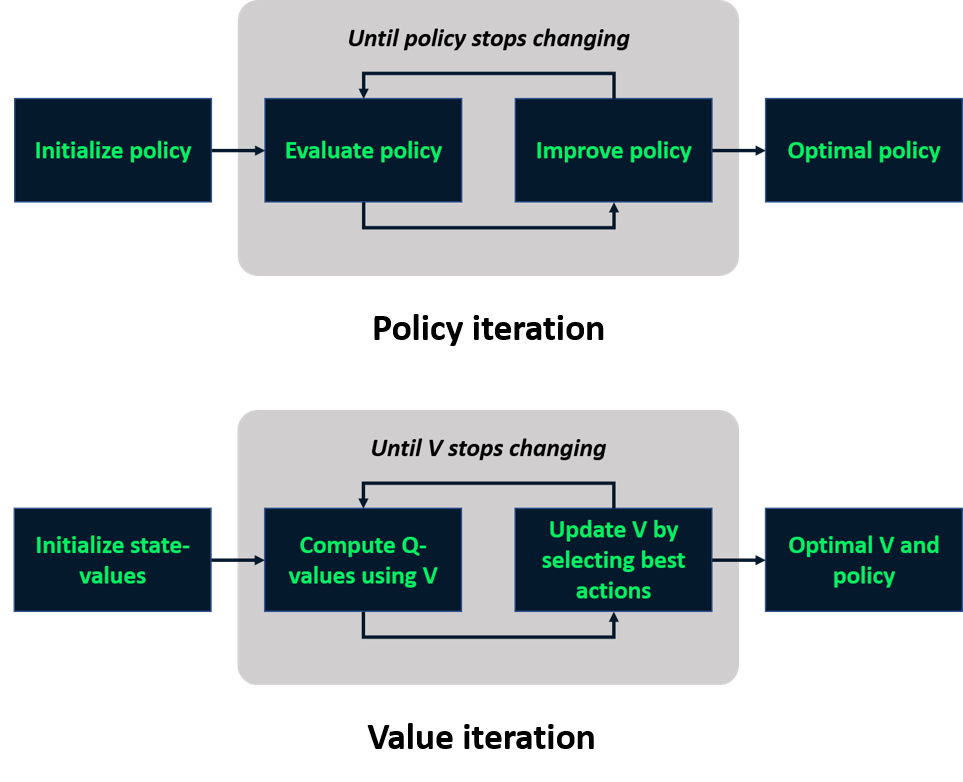
Modellfreies Lernen

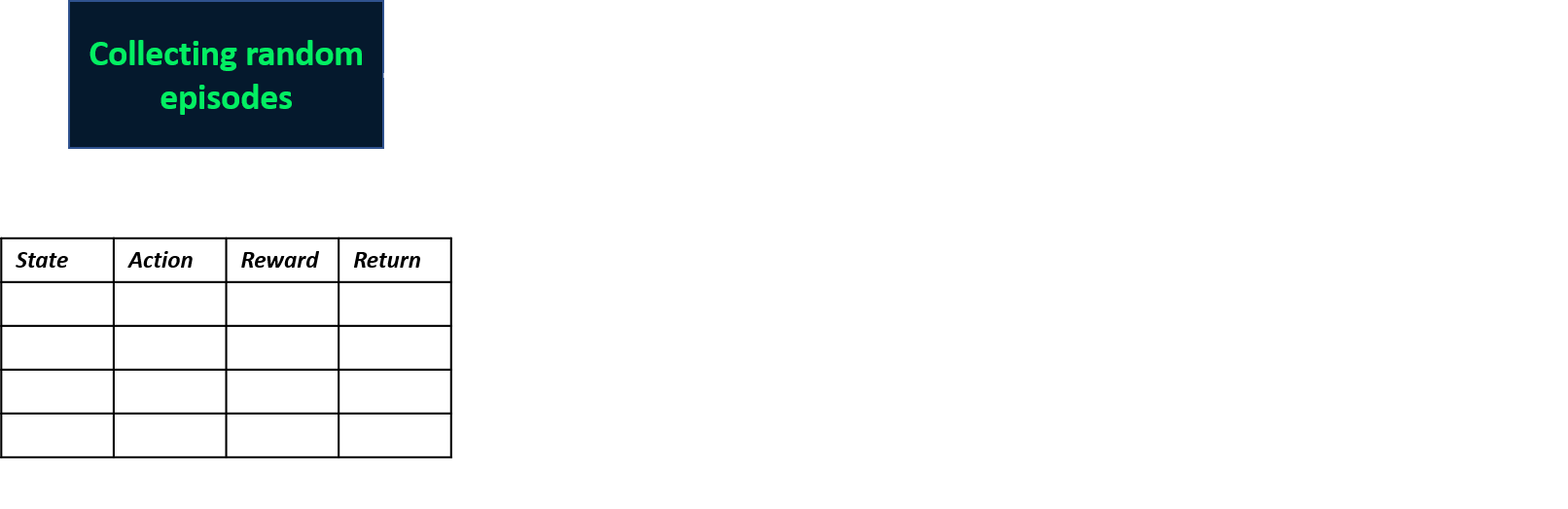
Monte-Carlo-Methoden
- Modellfreie Verfahren
- Schätzen Q-Werte aus Episoden
Monte-Carlo-Methoden
- Modellfreie Verfahren
- Schätzen Q-Werte aus Episoden

Monte-Carlo-Methoden
- Modellfreie Verfahren
- Schätzen Q-Werte aus Episoden

- Zwei Varianten: First-Visit, Every-Visit
Eigene Gridworld
Zwei Episoden sammeln
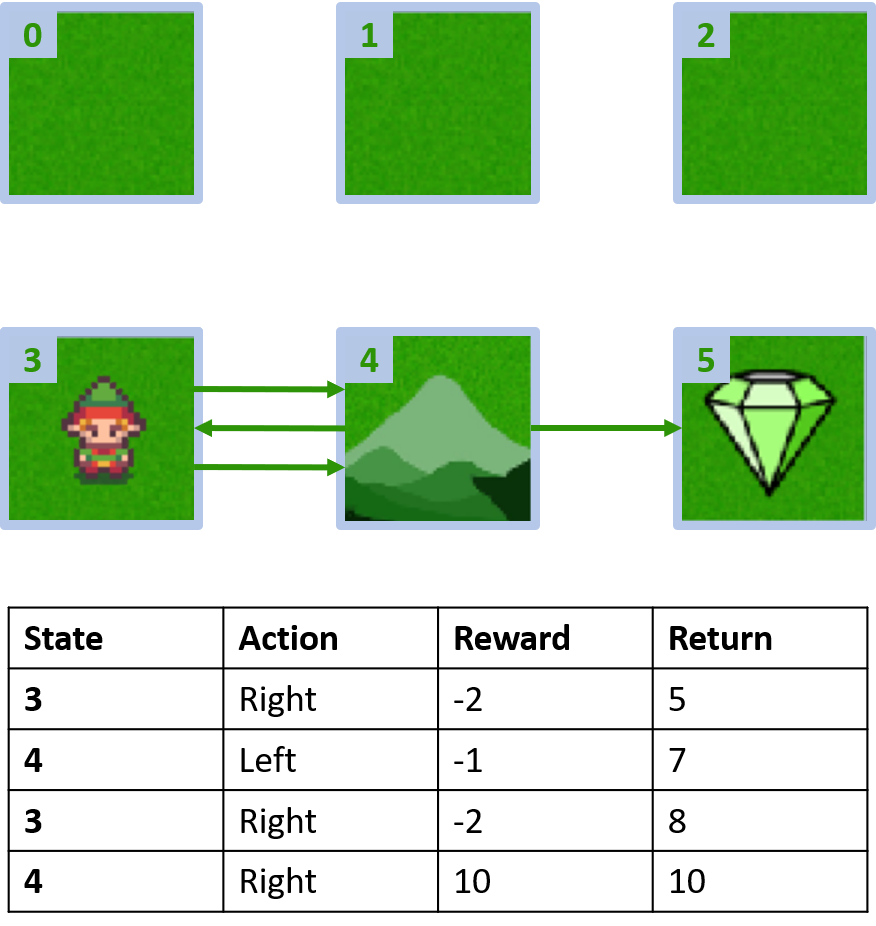
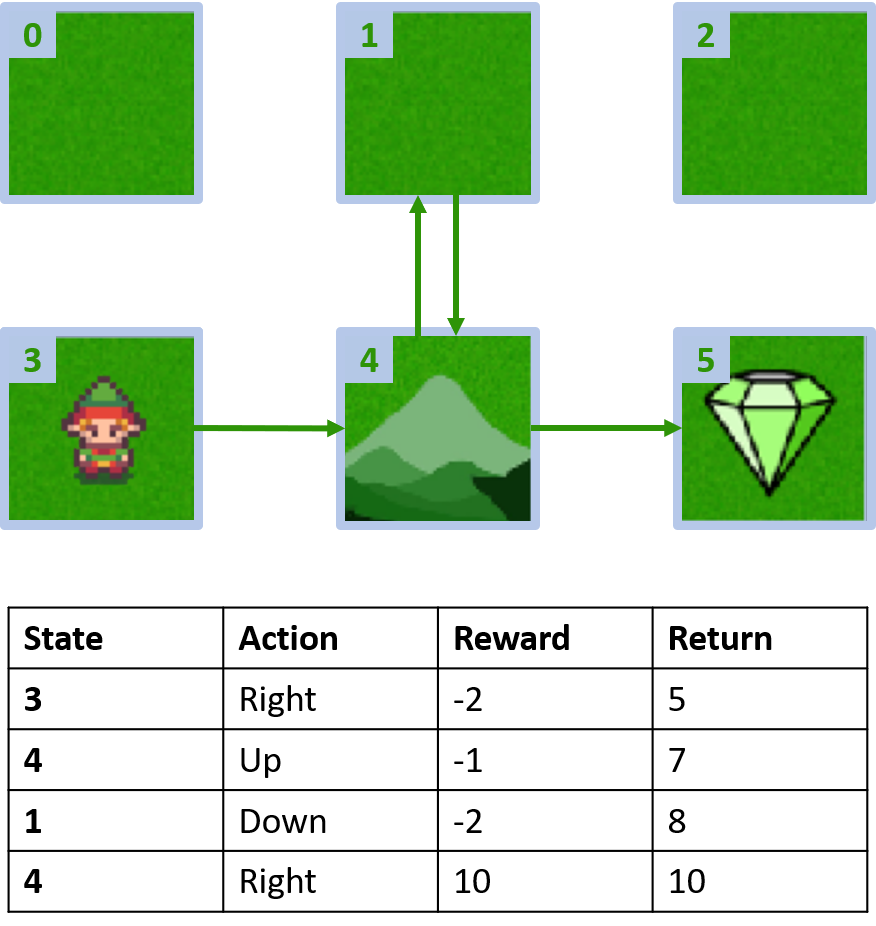
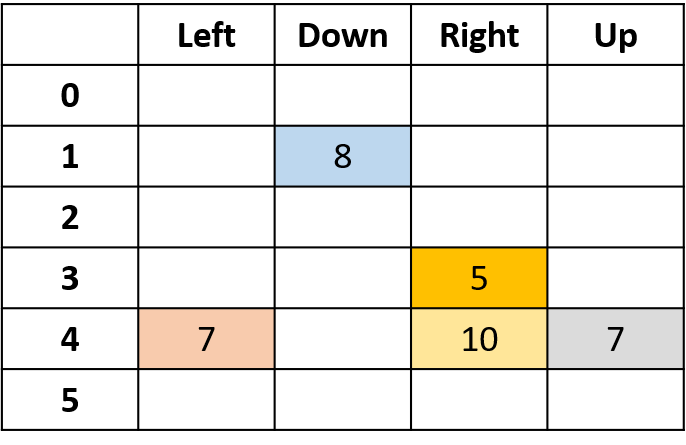
Q-Werte schätzen
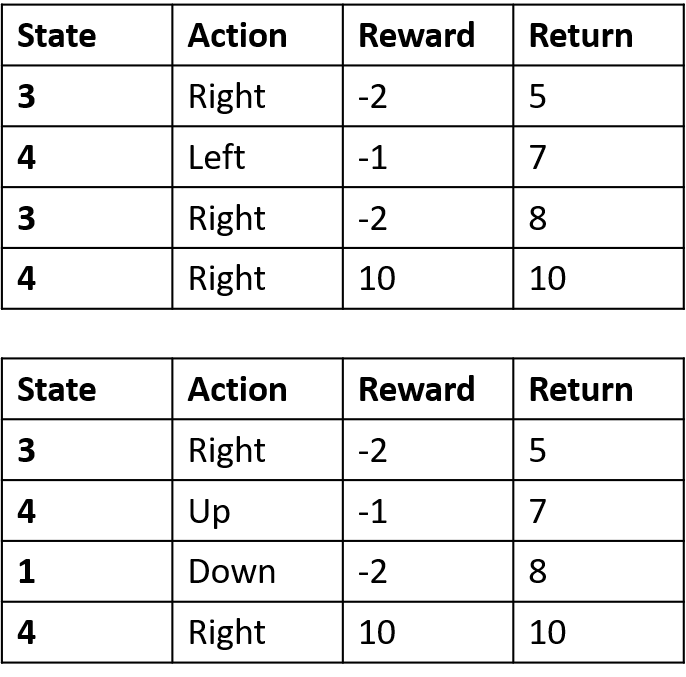
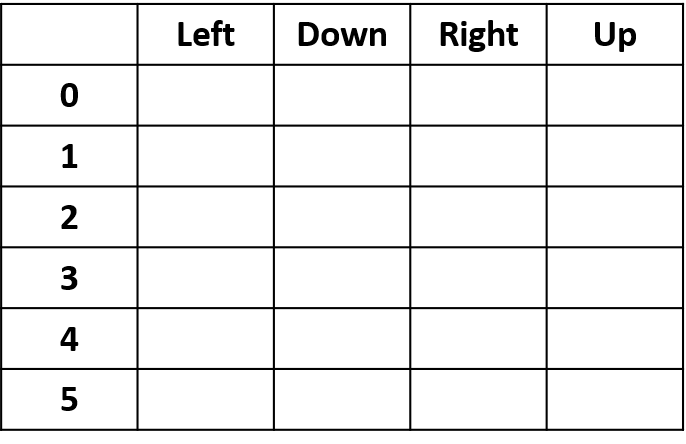
- Q-Tabelle: Tabelle der Q-Werte
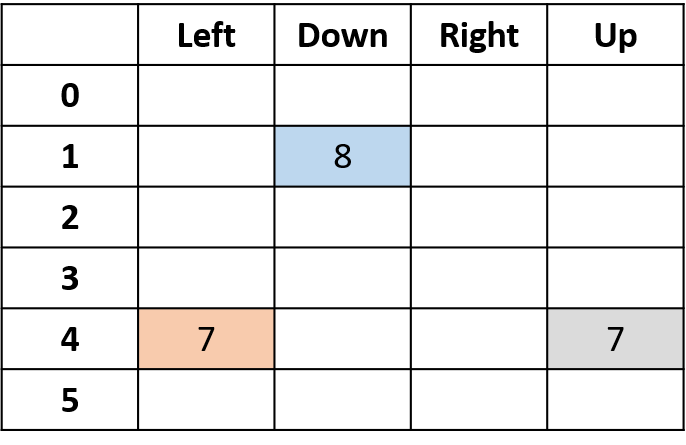
Q(4, links), Q(4, oben) und Q(1, unten)
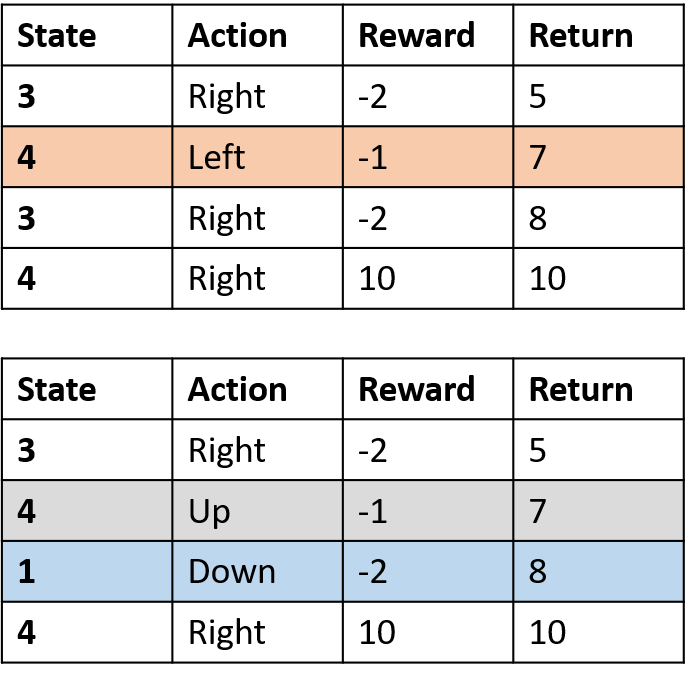
- (s,a) kommt einmal vor -> mit Return füllen
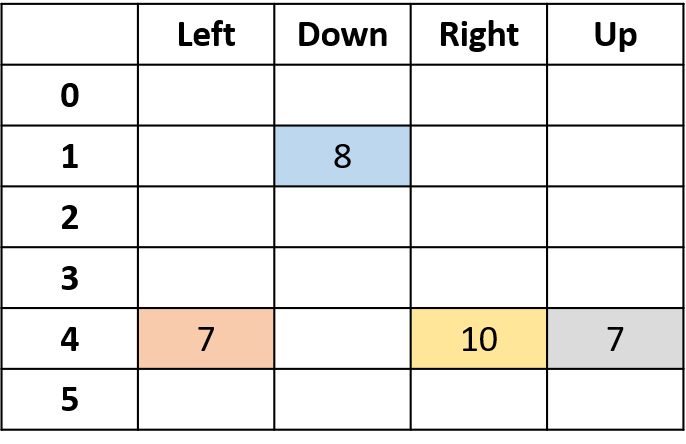
Q(4, rechts)
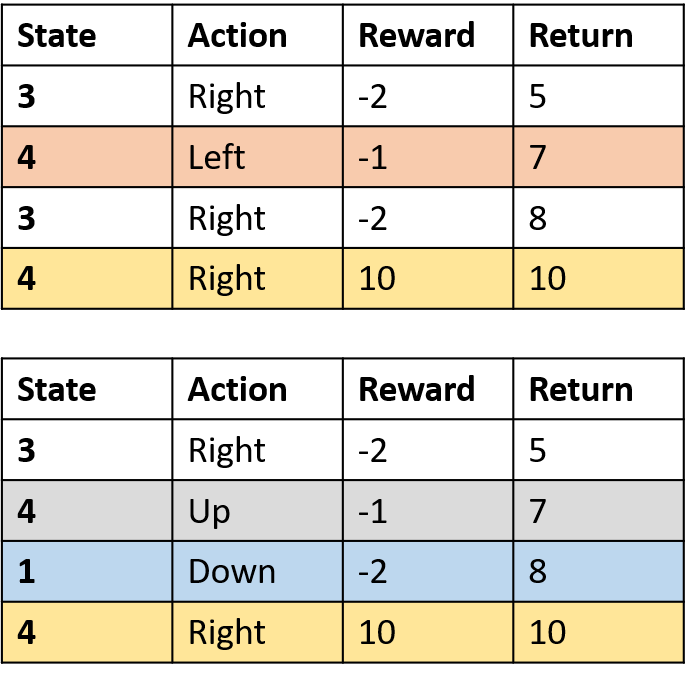
- (s,a) einmal pro Episode -> Mittelwert
Q(3, rechts) – First-Visit Monte Carlo
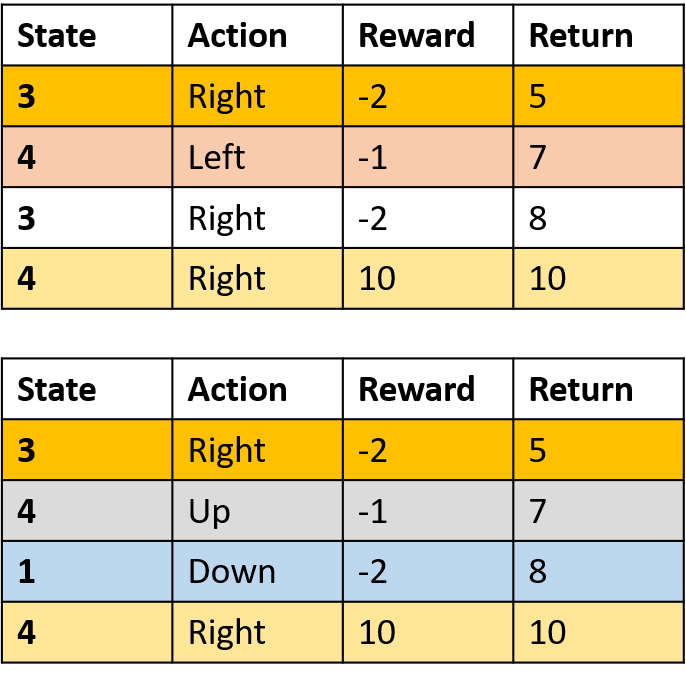
- Mittelwert über den ersten Besuch von (s,a) je Episode
Q(3, rechts) – Every-Visit Monte Carlo
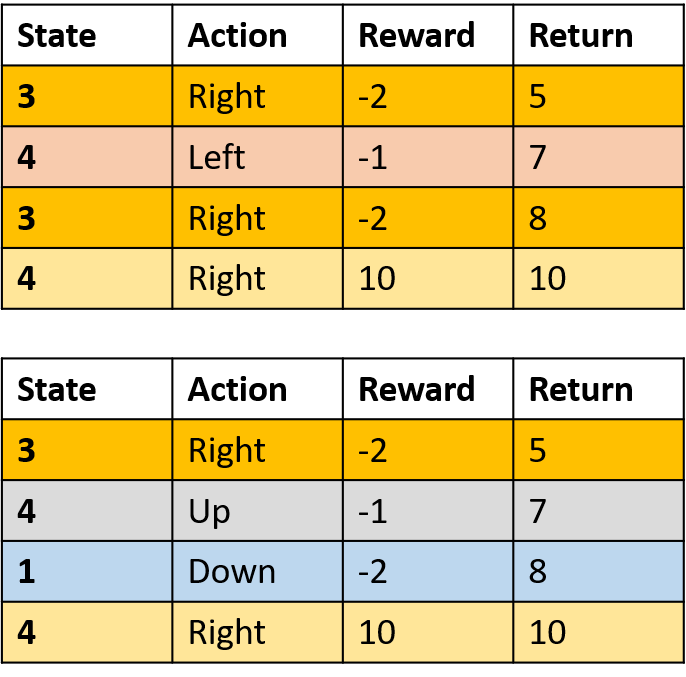
- Mittelwert über jeden Besuch von (s,a) je Episode
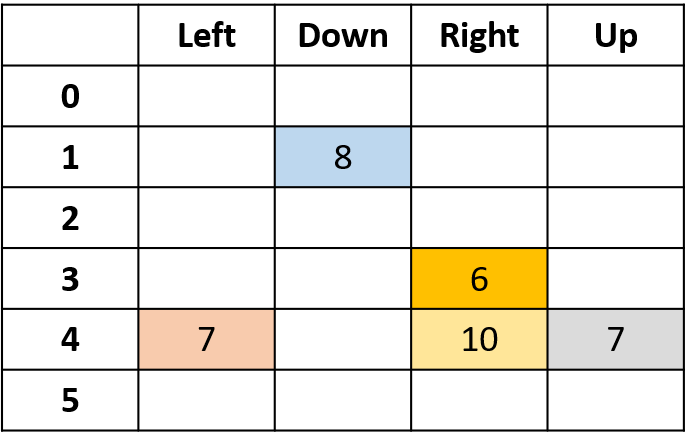
Alles zusammenführen