Exploration und Exploitation ausbalancieren
Reinforcement Learning mit Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Training mit zufälligen Aktionen

Exploration–Exploitation-Trade-off

Essenswahl

Epsilon-gierige Strategie
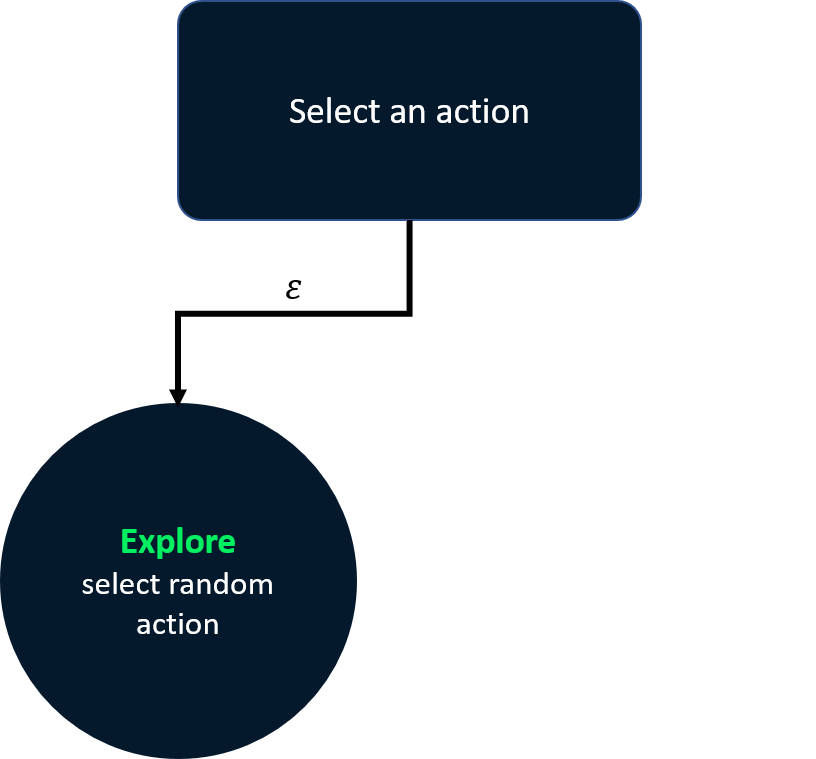
Epsilon-gierige Strategie
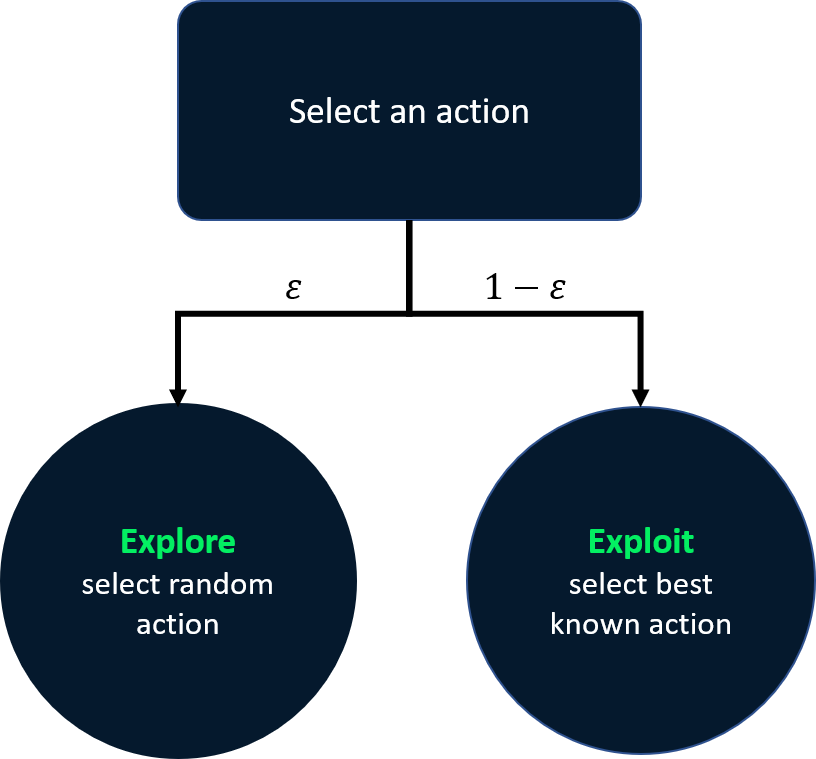
Abnehmende Epsilon-gierige Strategie

Implementierung mit Frozen Lake

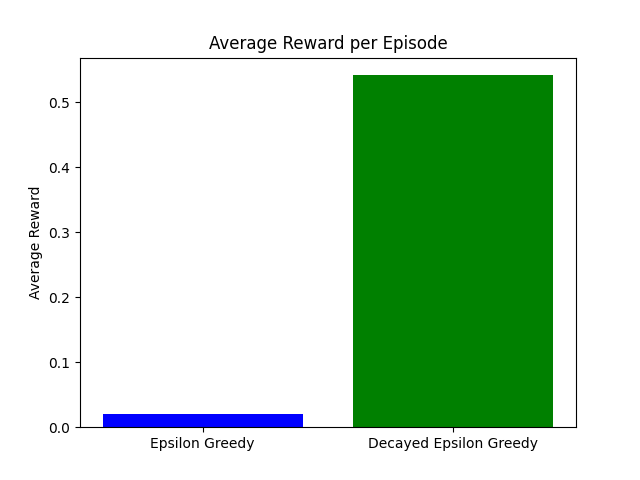
Strategien vergleichen