Policies und Zustandswertfunktionen
Reinforcement Learning mit Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Policies
- RL-Ziel → effektive Policies entwerfen
- Legt fest, welche Aktion in jedem Zustand den Return maximiert

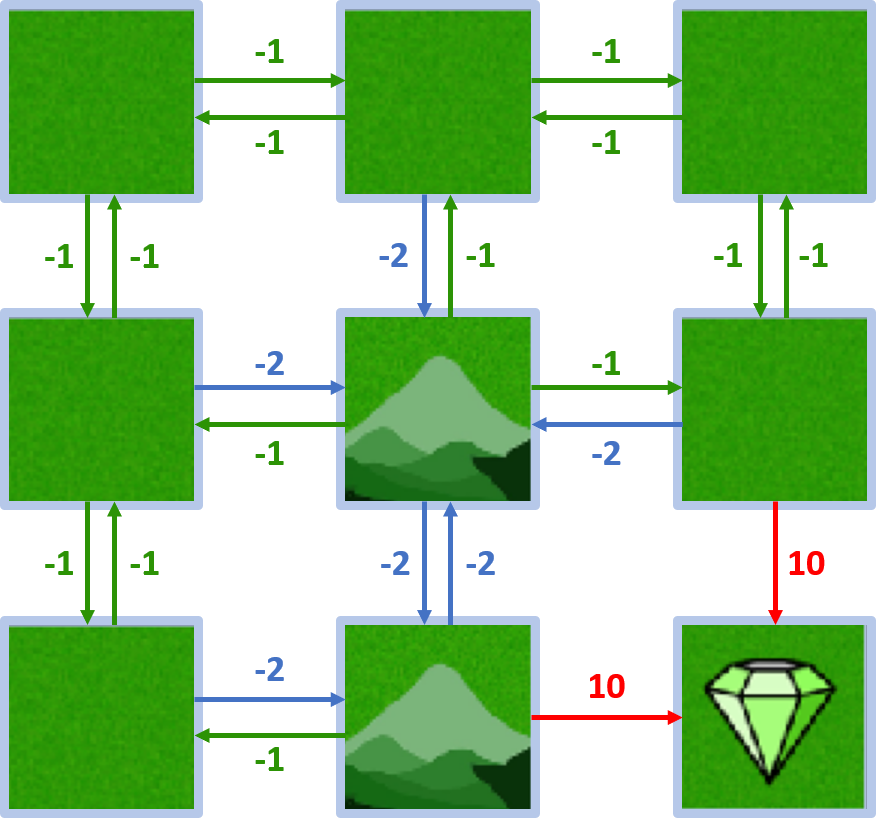
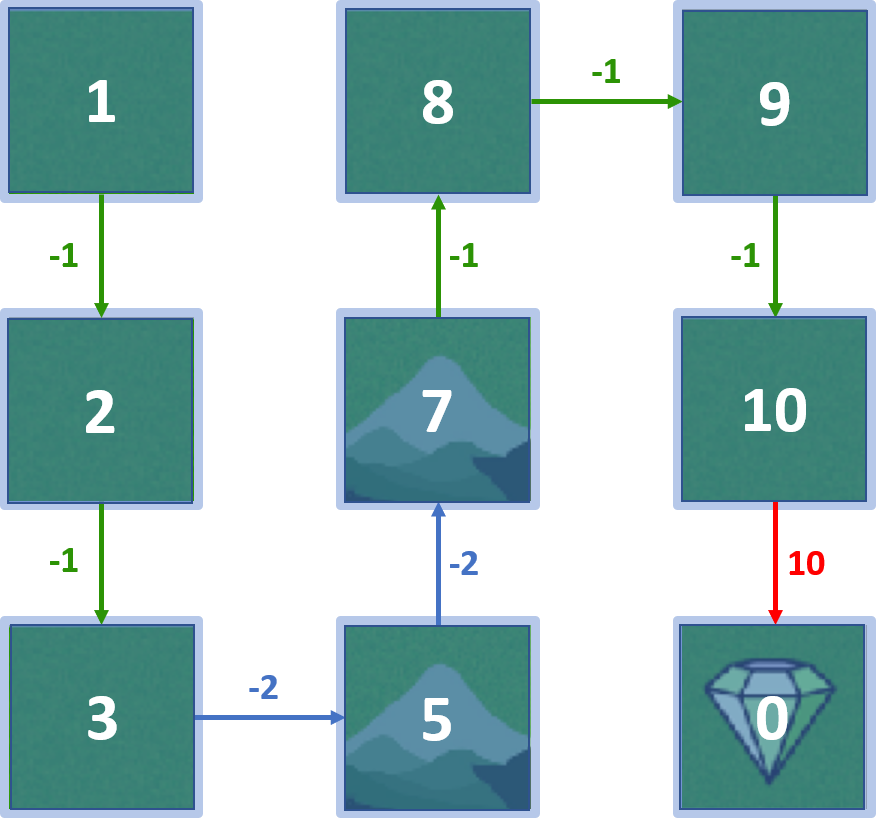
Gridworld-Beispiel
- Agent will den Diamanten erreichen und Berge meiden
- Neun Zustände
- Deterministische Bewegungen

Gridworld-Beispiel – Belohnungen
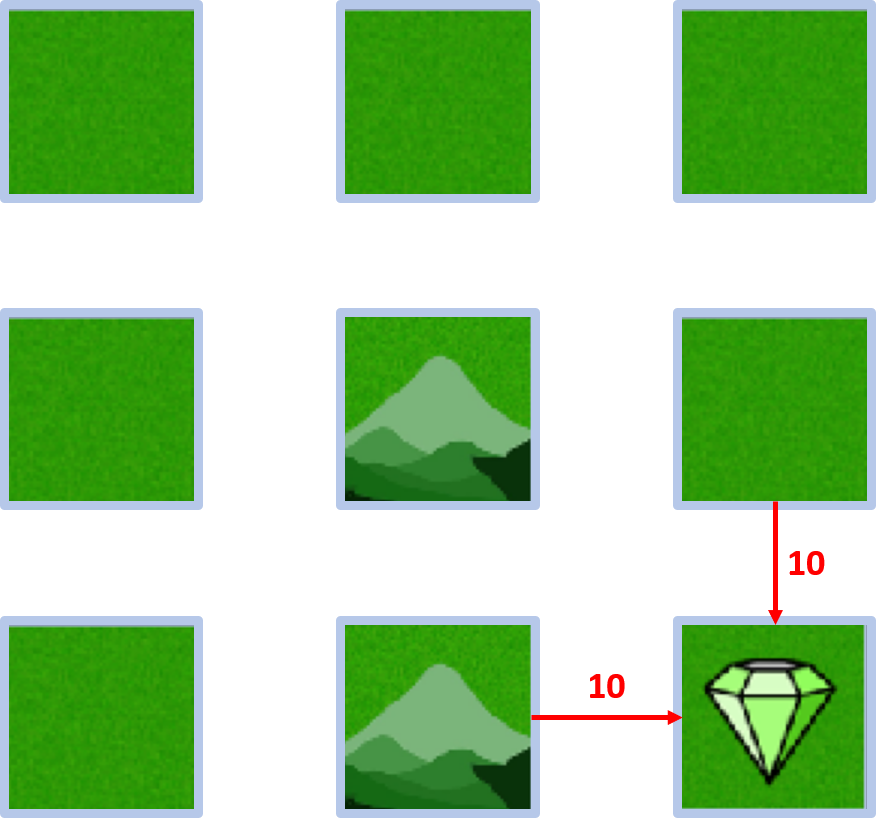
Gridworld-Beispiel – Belohnungen
Gridworld-Beispiel – Belohnungen
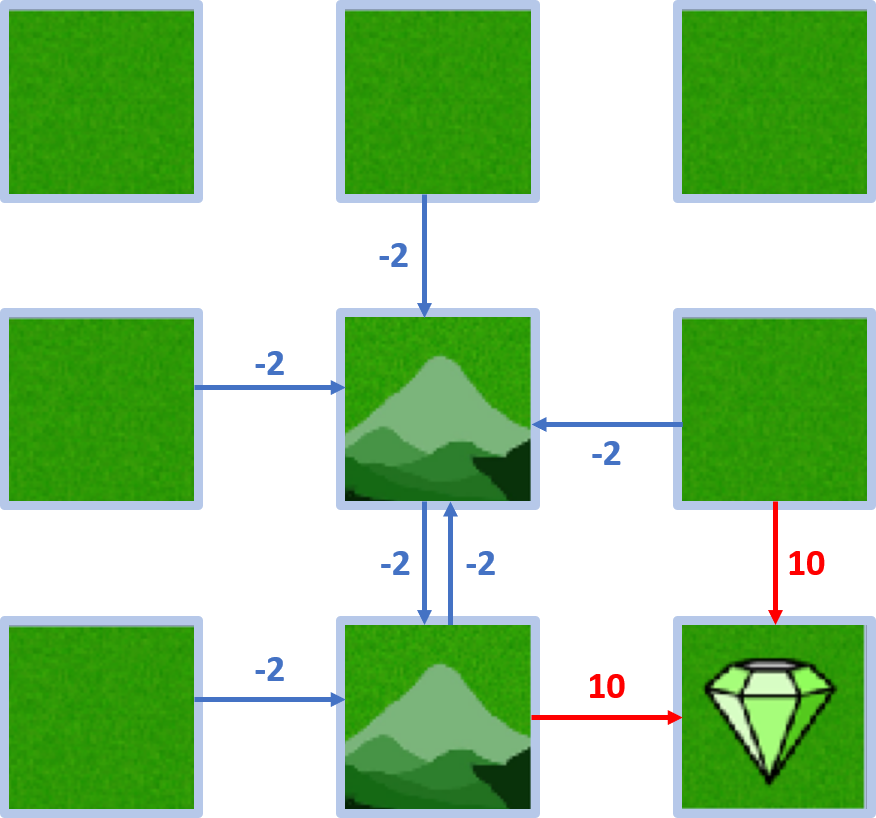
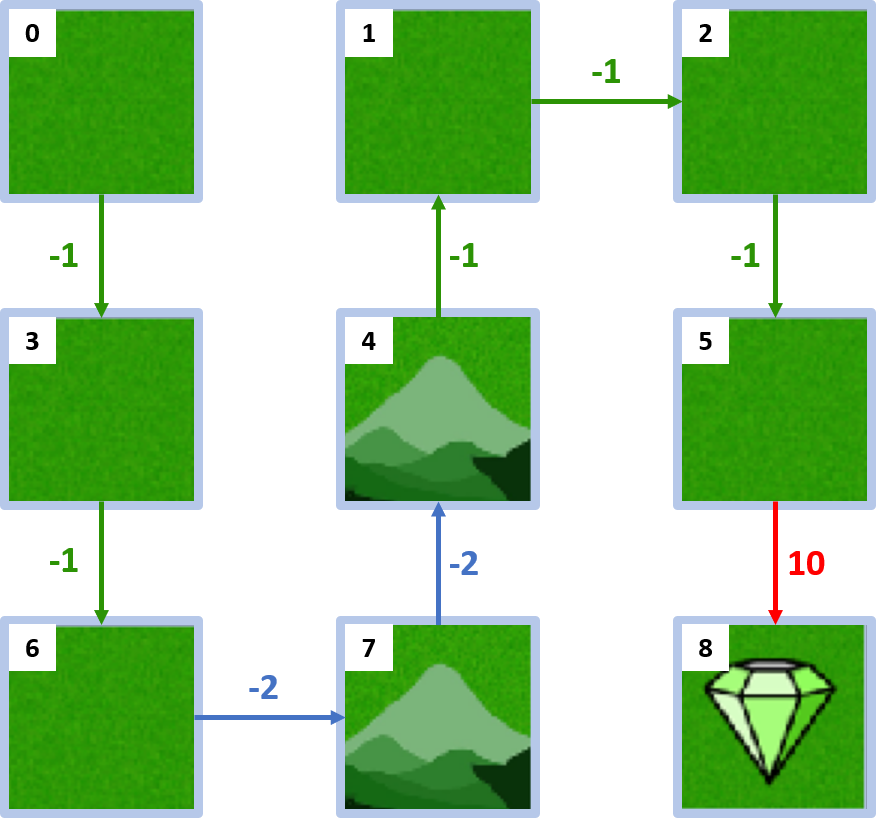
Gridworld-Beispiel: Policy
Zustandswertfunktionen
- Schätzt den Wert eines Zustands
- Erwartete Rückgabe ab Zustand, Policy folgend

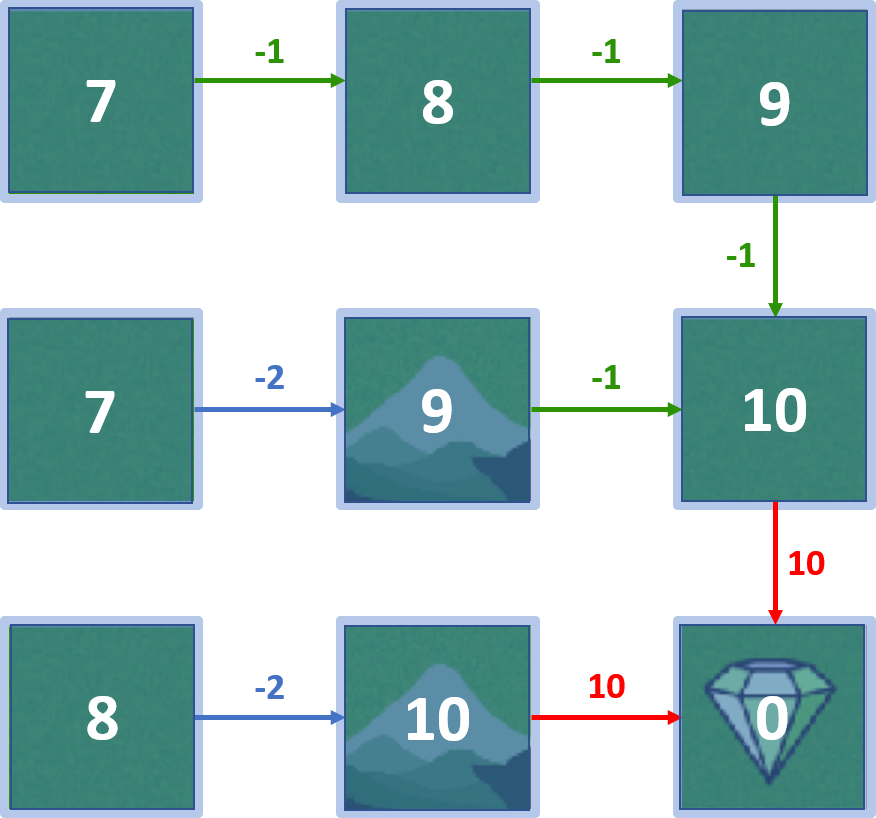
Gridworld-Beispiel: Zustandswerte
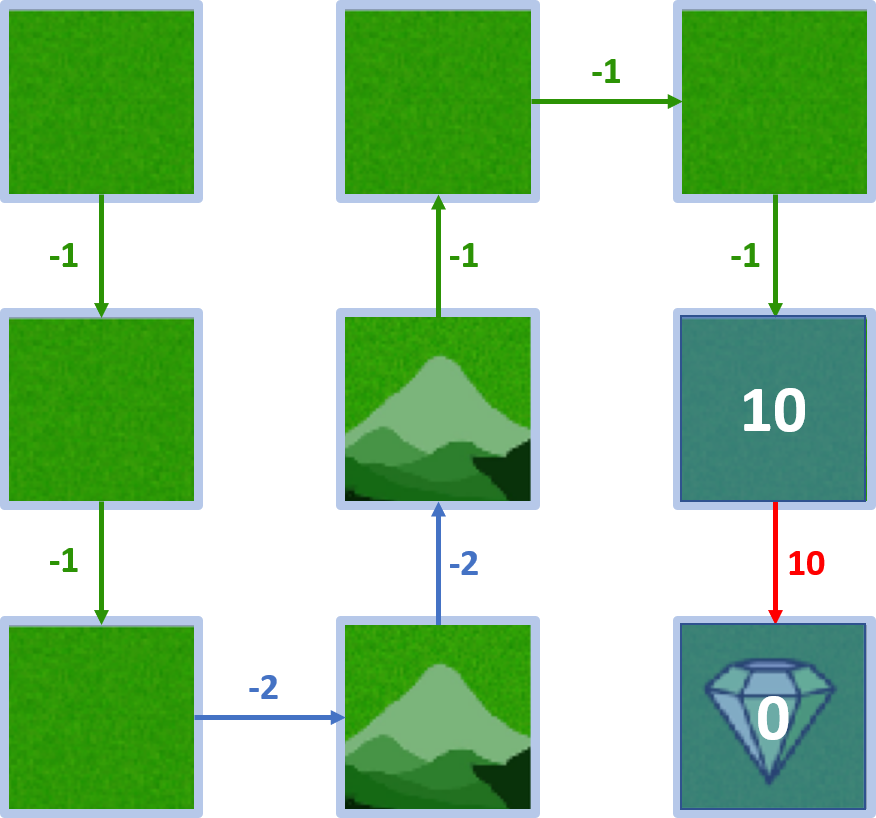
Wert des Zielzustands
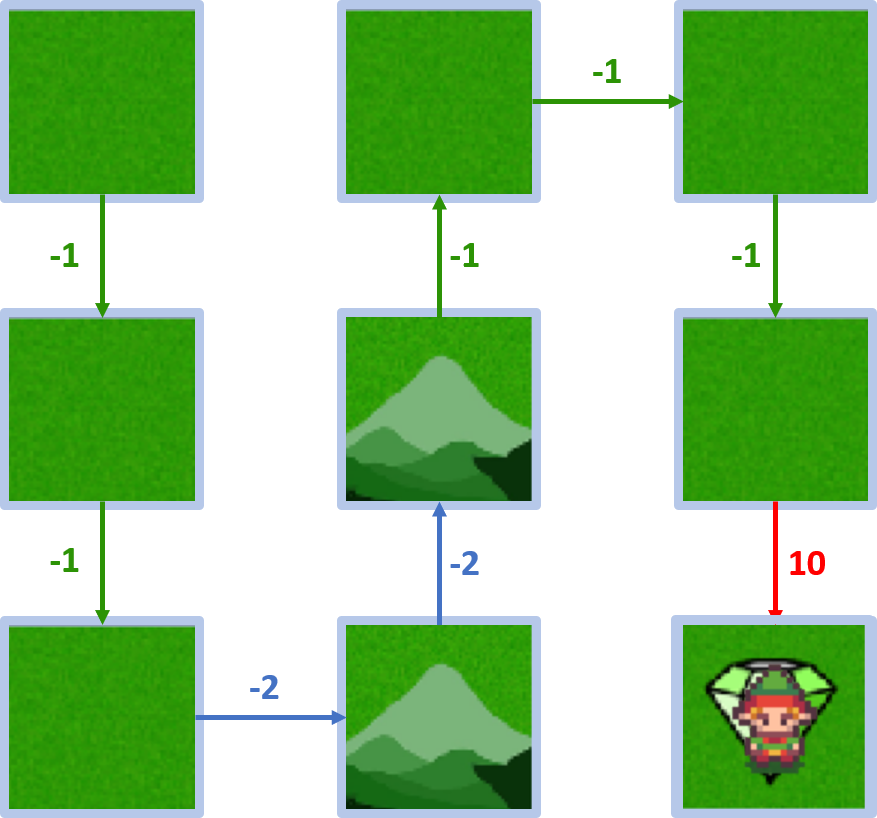
- Start im Zielzustand, Agent bewegt sich nicht
- $V(goal \, state) = 0$
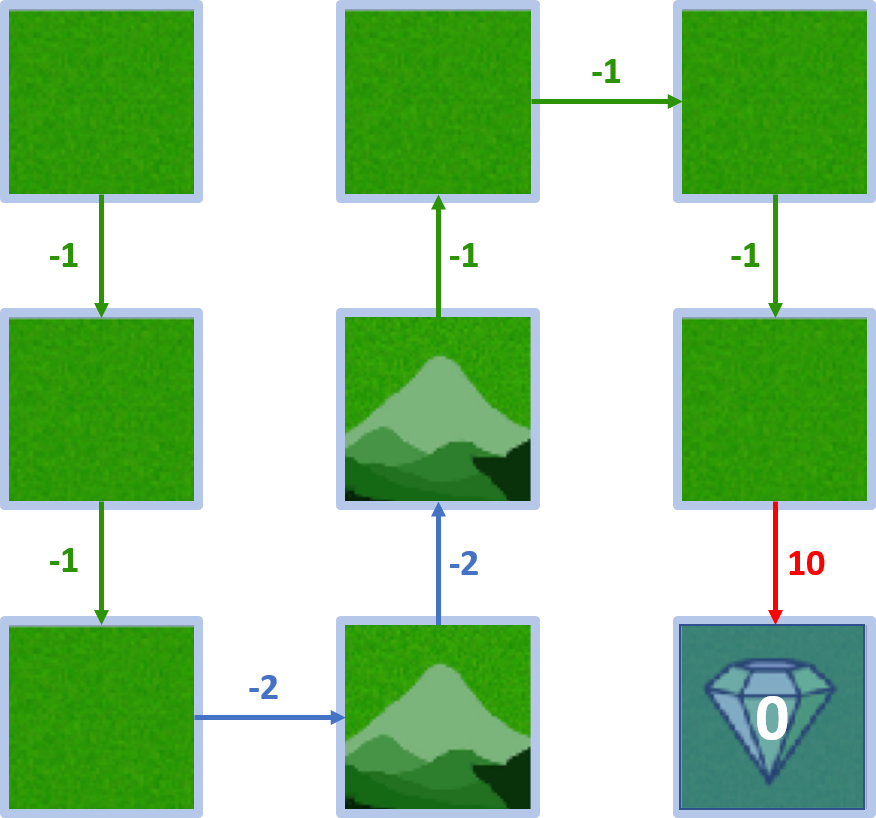
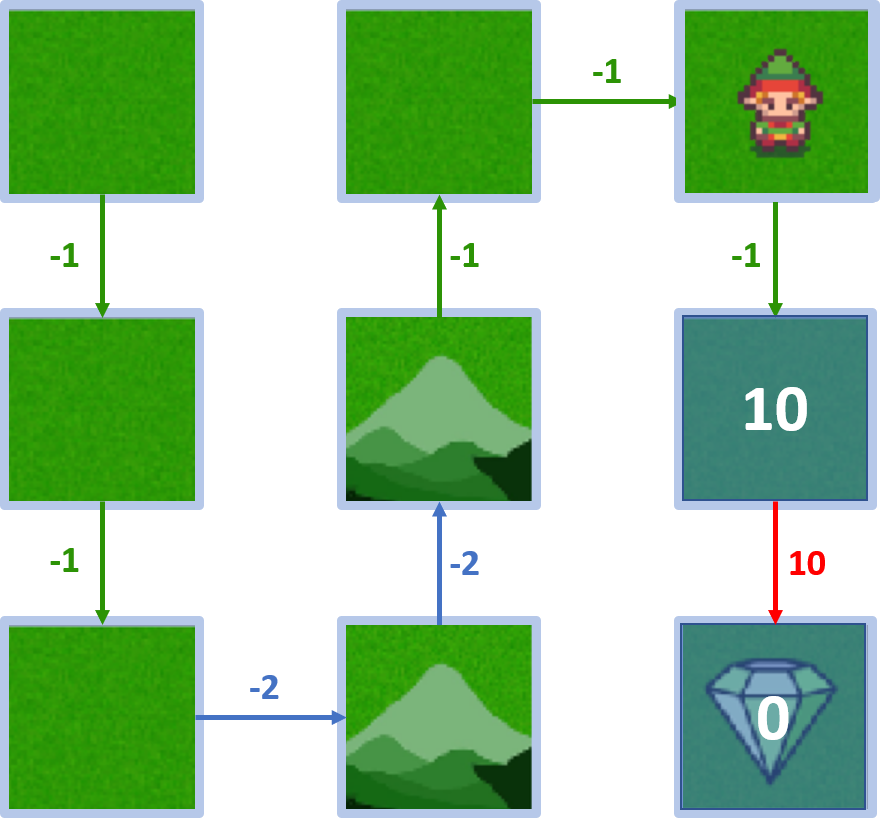
Wert von Zustand 5
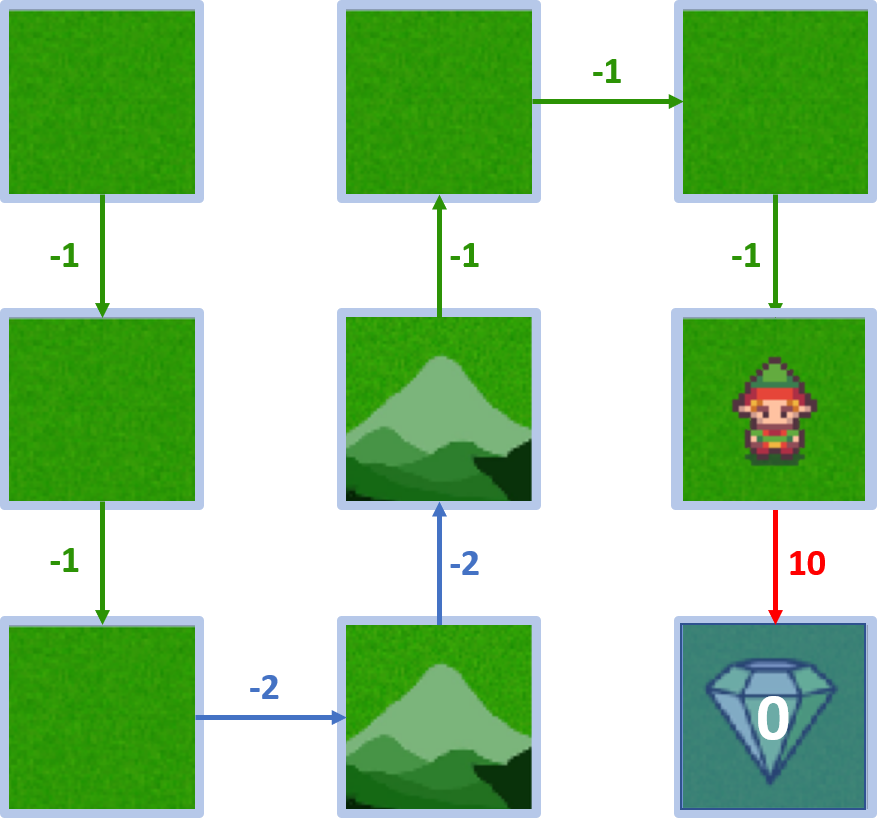
- Start in 5, Agent geht zum Ziel
- $V(5) = 10$
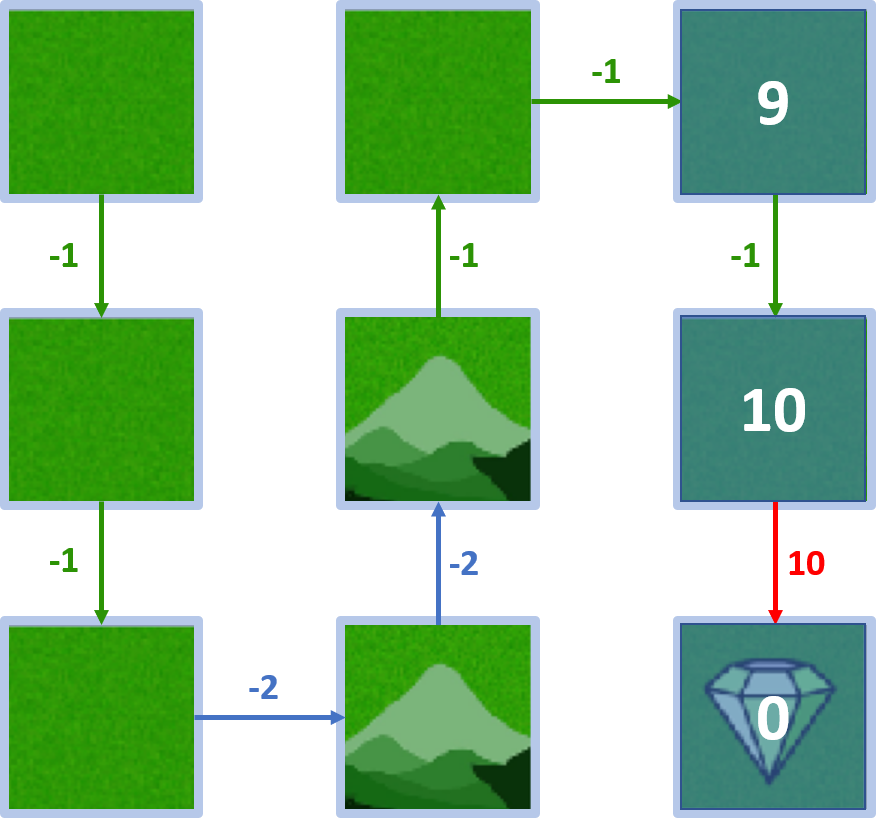
Wert von Zustand 2
- Start in 2, Belohnungen: $-1, 10$
- $ V(2) = (1 \times -1) + (1 \times 10) = 9$
Alle Zustandswerte
Bellman-Gleichung
- Rekursive Formel
- Berechnet Zustandswerte

Zustandswerte berechnen
def compute_state_value(state):if state == terminal_state: return 0action = policy[state]_, next_state, reward, _ = env.unwrapped.P[state][action][0]return reward + gamma * compute_state_value(next_state)
Zustandswerte berechnen
Policies ändern
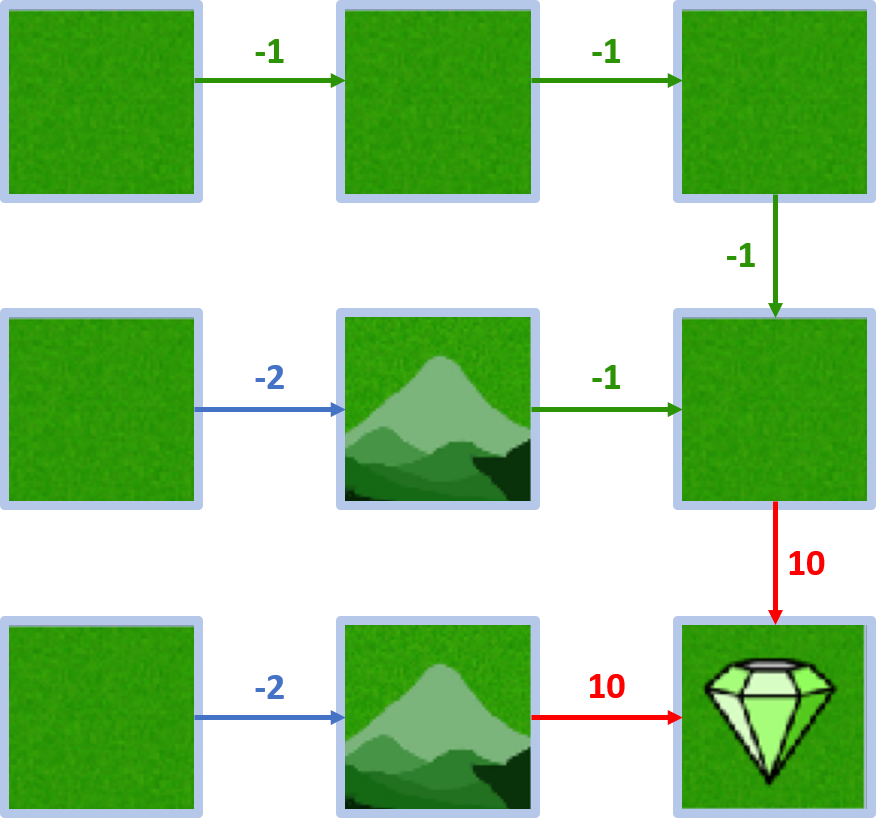
Policies vergleichen
Zustandswerte für Policy 1
{0: 1, 1: 8, 2: 9,
3: 2, 4: 7, 5: 10,
6: 3, 7: 5, 8: 0}
Zustandswerte für Policy 2
{0: 7, 1: 8, 2: 9,
3: 7, 4: 9, 5: 10,
6: 8, 7: 10, 8: 0}