Double Q-Learning
Reinforcement Learning mit Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Q-Learning
- Schätzt die optimale Aktions-Wert-Funktion
- Überschätzt Q-Werte, da auf max Q aktualisiert wird
- Kann zu suboptimaler Policy führen

Double Q-Learning
- Verwendet zwei Q-Tabellen
- Jede Tabelle wird anhand der anderen aktualisiert
- Verringert das Risiko der Überschätzung von Q-Werten
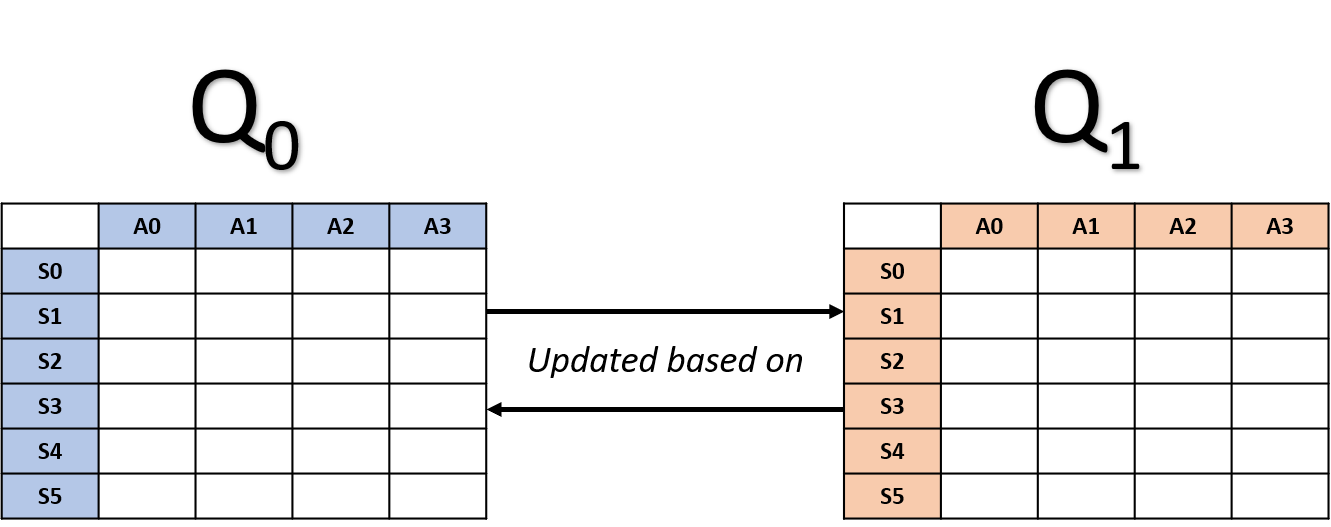
Double Q-Learning: Updates
- Zufällig eine Tabelle wählen
Update von Q0
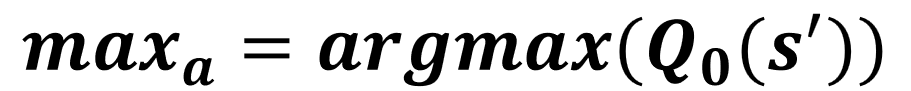
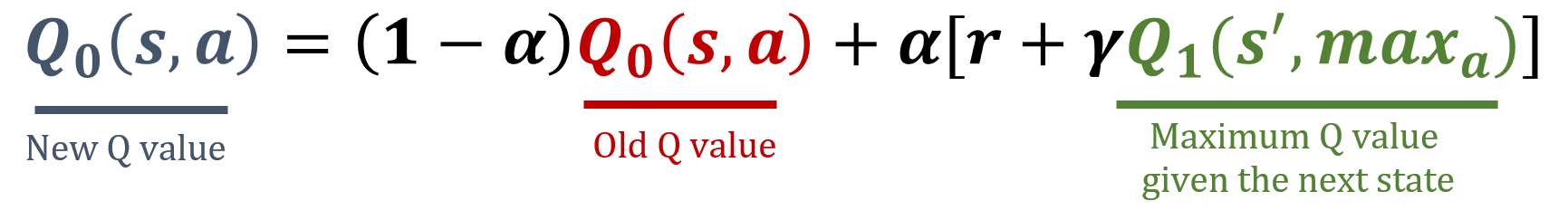
Update von Q1
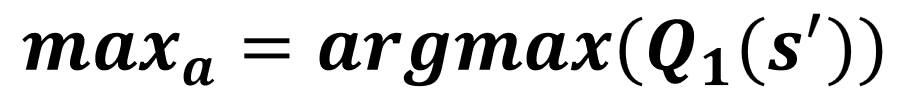
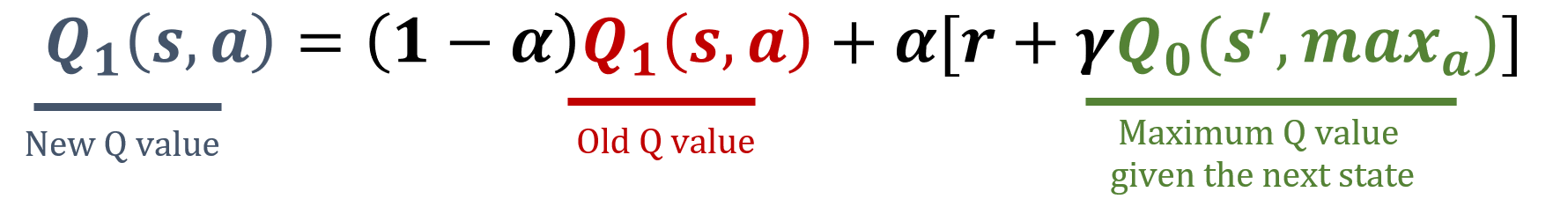
Double Q-Learning
- Verringert Überschätzungs-Bias
- Wechselt zwischen Updates von Q0 und Q1
- Beide Tabellen tragen zum Lernen bei
Implementierung mit Frozen Lake

update_q_tables() implementieren
def update_q_tables(state, action, reward, next_state): # Select a random Q-table index (0 or 1) i = np.random.randint(2)# Update the corresponding Q-table best_next_action = np.argmax(Q[i][next_state])Q[i][state, action] = (1 - alpha) * Q[i][state, action] + alpha * (reward + gamma * Q[1-i][next_state, best_next_action])
Policy des Agents