Multi-Armed Bandits
Reinforcement Learning mit Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Multi-Armed Bandits

Spielautomaten

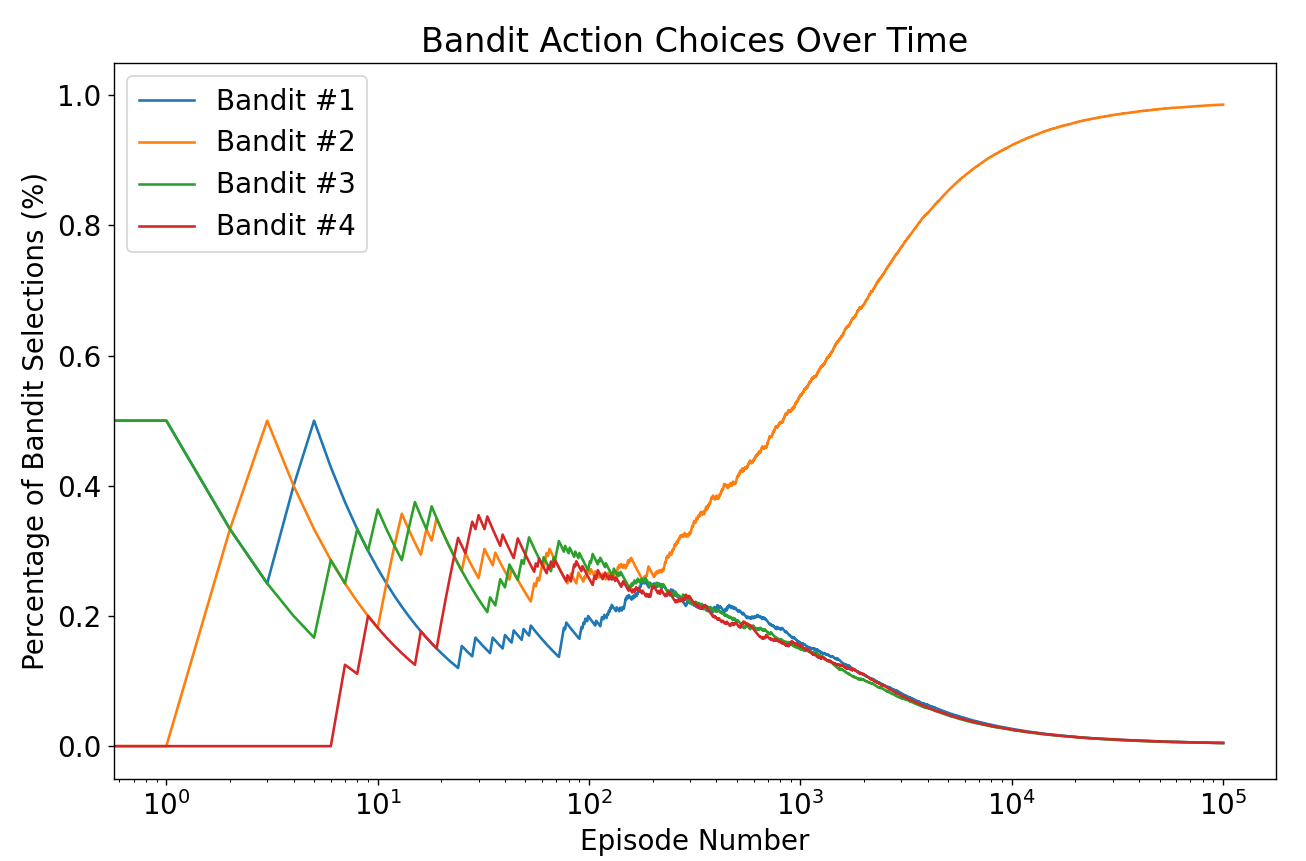
- Reward eines Arms ist 0 oder 1
- Ziel des Agents → maximale Gesamtreward
Das Problem lösen
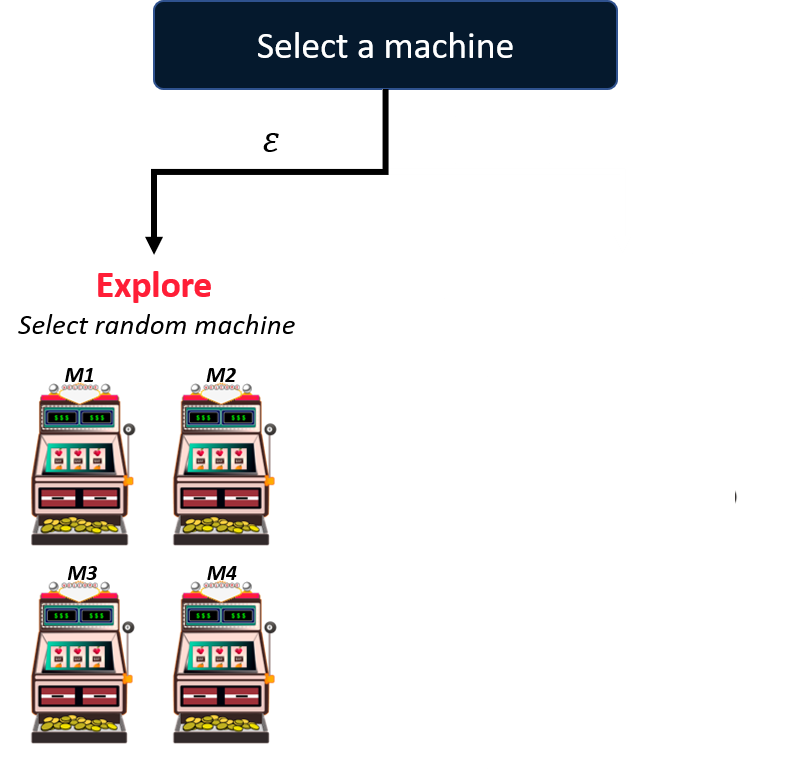
Das Problem lösen

Auswahlen analysieren
selections_percentage = np.zeros((n_iterations, n_bandits))

Auswahlen analysieren
selections_percentage = np.zeros((n_iterations, n_bandits))for i in range(n_iterations): selections_percentage[i, selected_arms[i]] = 1
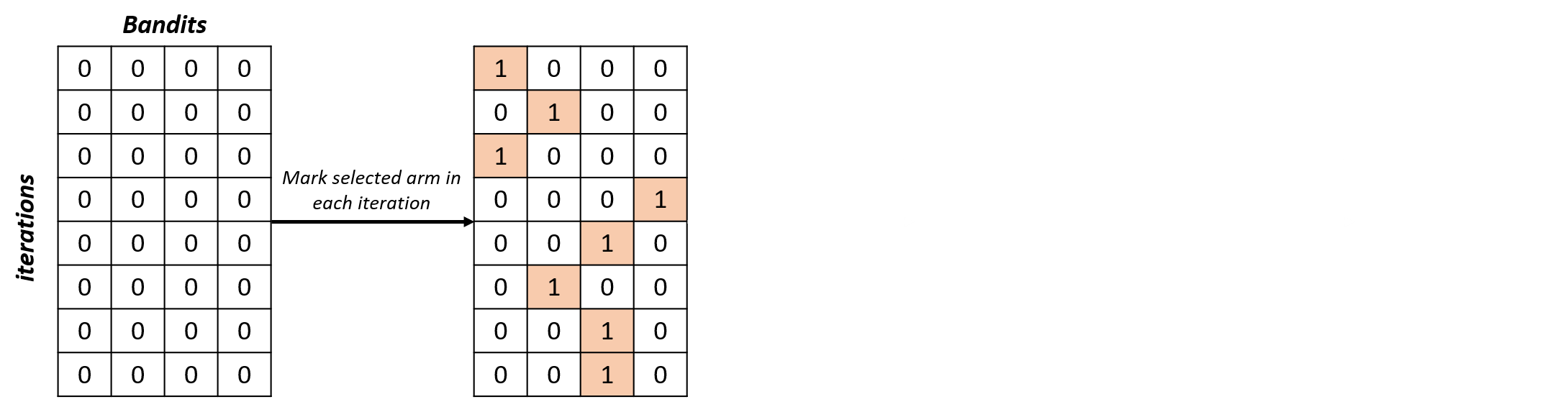
Auswahlen analysieren
selections_percentage = np.zeros((n_iterations, n_bandits))for i in range(n_iterations): selections_percentage[i, selected_arms[i]] = 1selections_percentage = np.cumsum(selections_percentage, axis=0) / np.arange(1, n_iterations + 1).reshape(-1, 1)
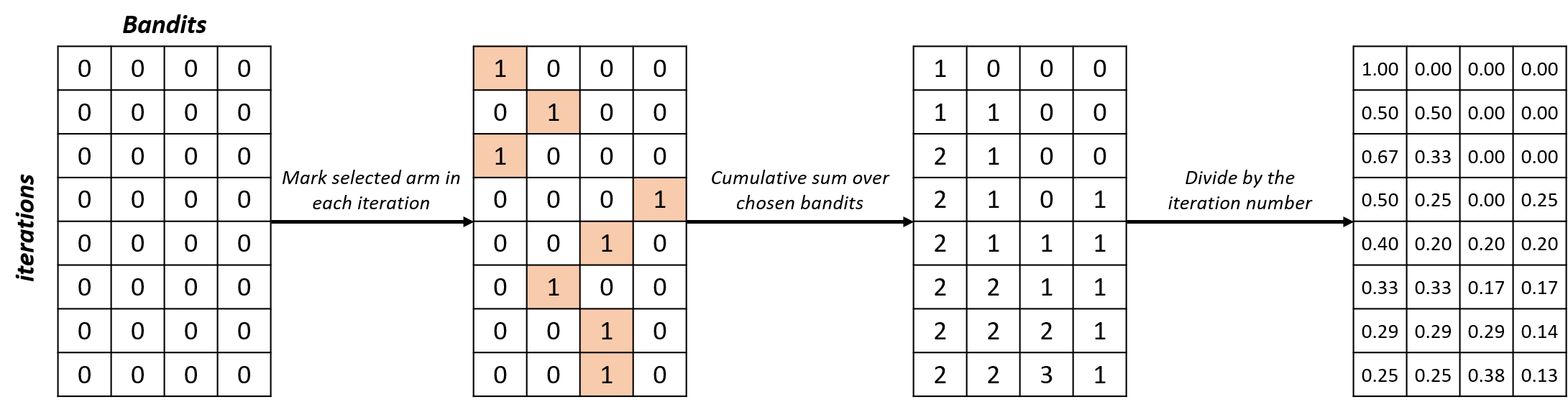
Auswahlen analysieren