Expected SARSA
Reinforcement Learning mit Gymnasium in Python

Fouad Trad
Machine Learning Engineer
Expected SARSA
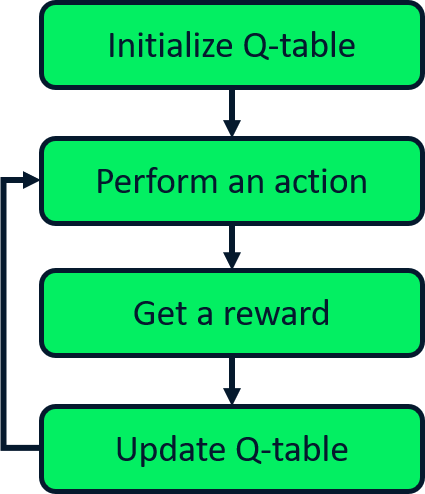
Expected-SARSA-Update
SARSA

Q-Learning

Expected SARSA
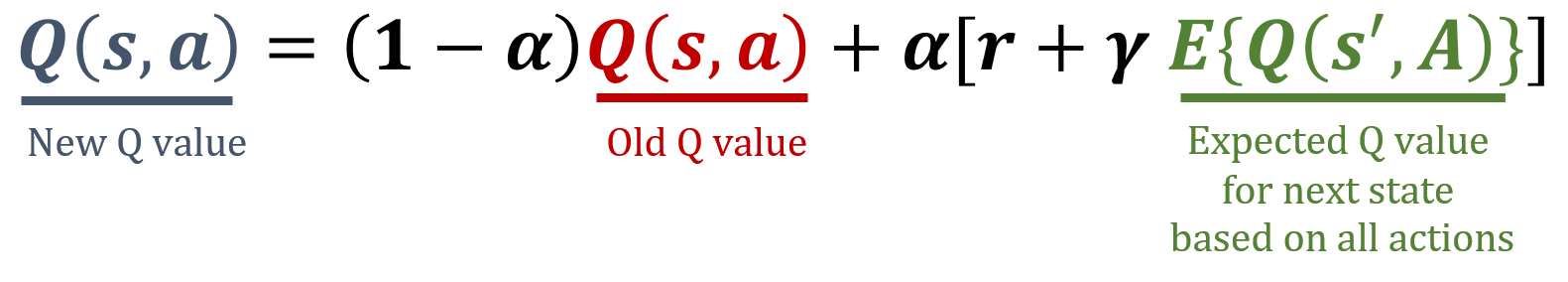
Erwartungswert des nächsten Zustands
- Berücksichtigt alle Aktionen

- Zufällige Aktionen → gleiche Wahrscheinlichkeiten

Implementierung mit Frozen Lake

Expected-SARSA-Update-Regel
def update_q_table(state, action, next_state, reward):expected_q = np.mean(Q[next_state])Q[state, action] = (1-alpha) * Q[state, action] + alpha * (reward + gamma * expected_q)
Policy des Agenten