Policy Iteration und Value Iteration
Reinforcement Learning mit Gymnasium in Python

Fouad Trad
Machine Learning Engineer
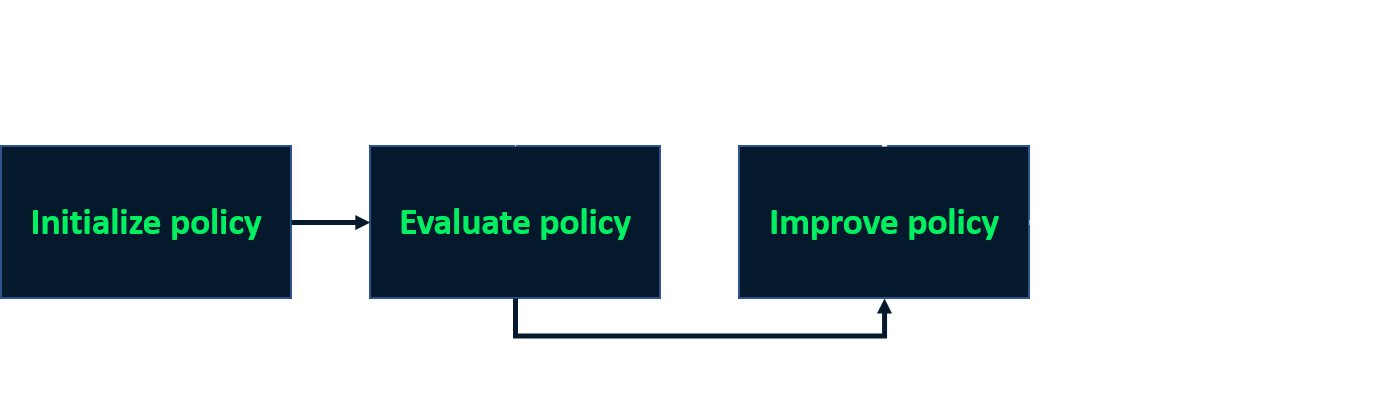
Policy Iteration
- Iterativer Prozess zur Bestimmung der optimalen Policy

Policy Iteration
- Iterativer Prozess zur Bestimmung der optimalen Policy

Policy Iteration
- Iterativer Prozess zur Bestimmung der optimalen Policy
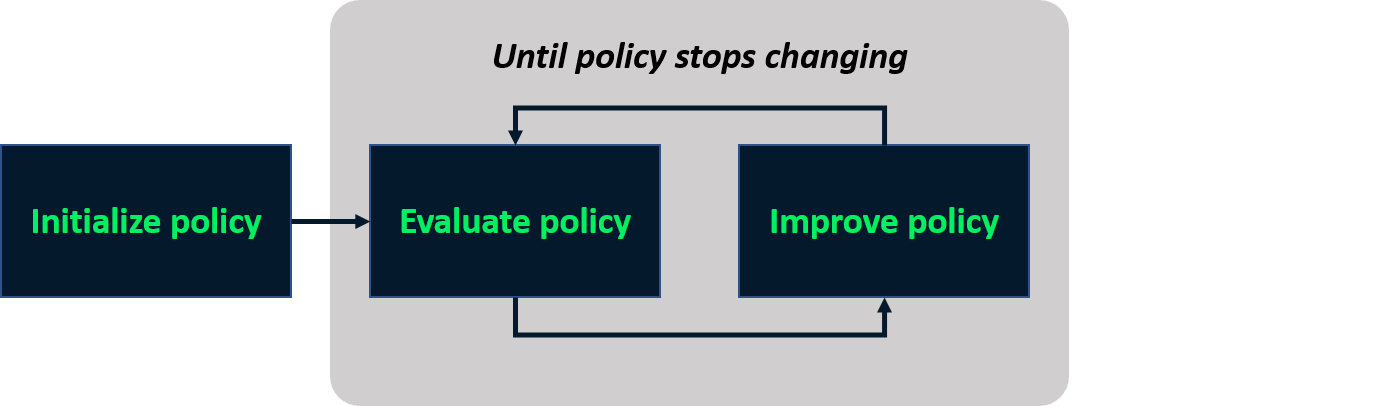
Policy Iteration
- Iterativer Prozess zur Bestimmung der optimalen Policy
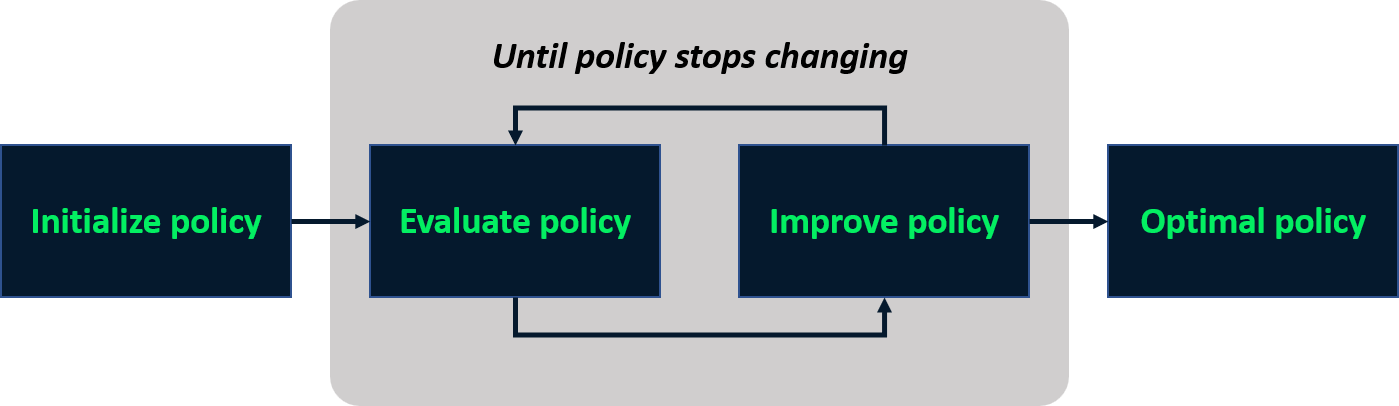
Policy Iteration
- Iterativer Prozess zur Bestimmung der optimalen Policy
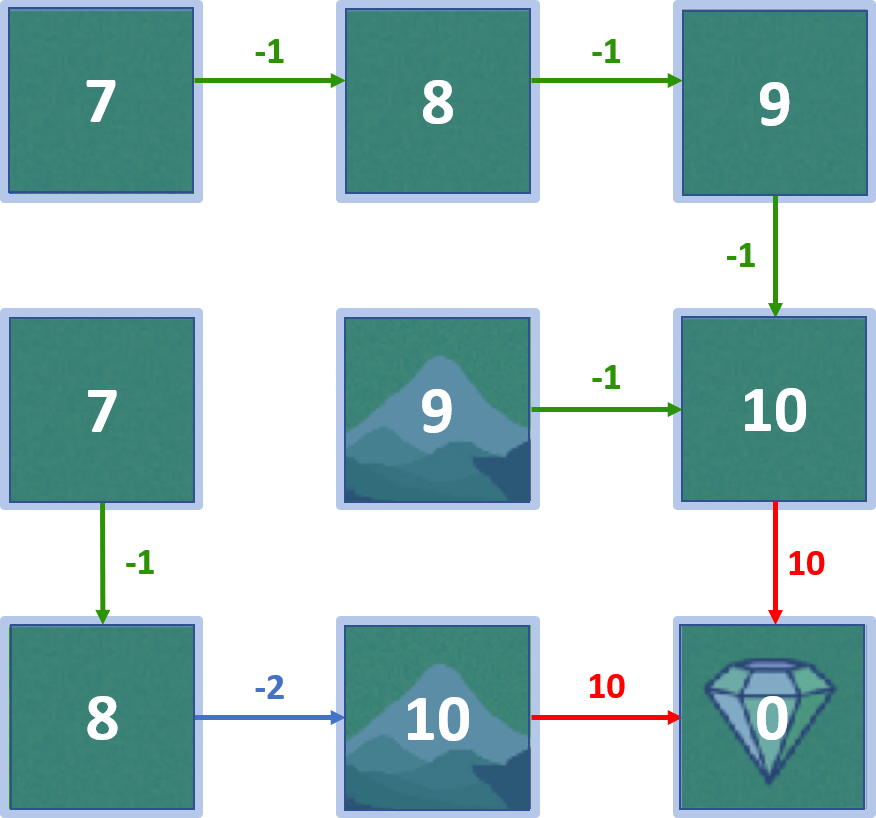
Gridworld
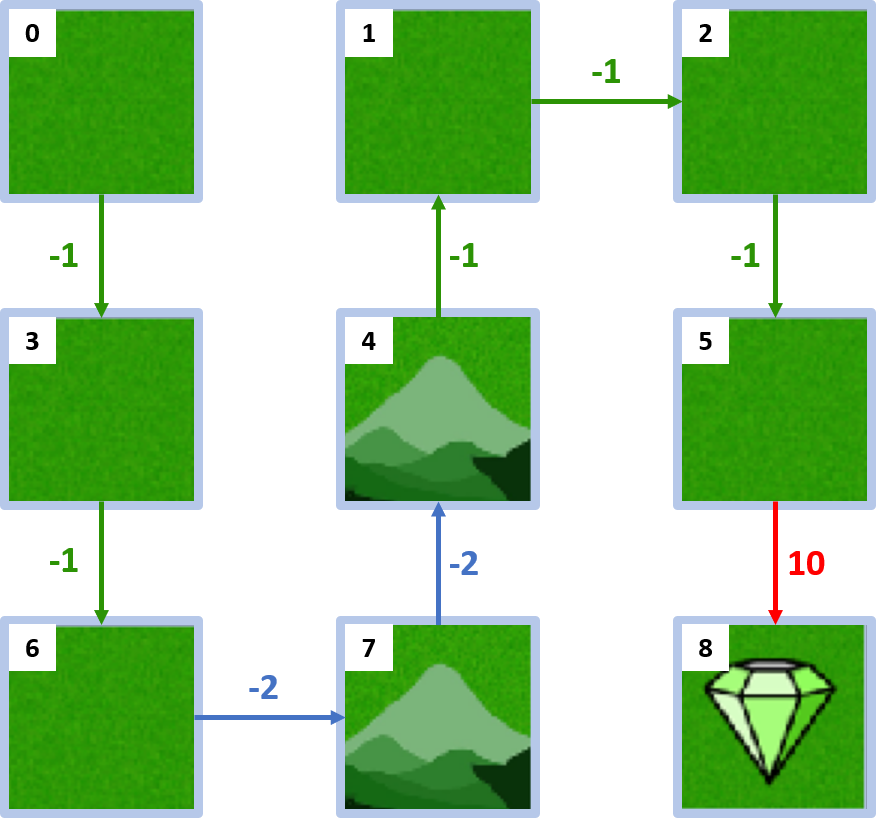
Optimale Policy
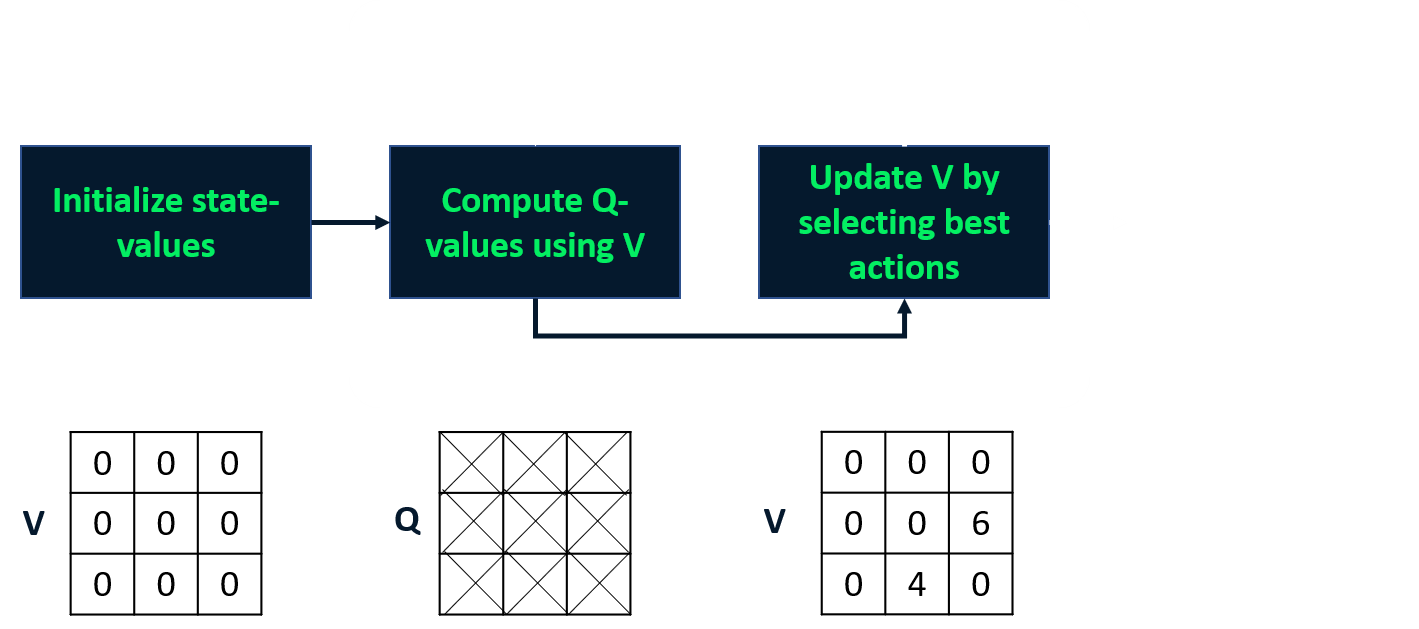
Value Iteration
- Kombiniert Policy Evaluation und Improvement in einem Schritt
- Berechnet die optimale Zustandswertfunktion
- Leitet daraus die Policy ab

Value Iteration
- Kombiniert Policy Evaluation und Improvement in einem Schritt.
- Berechnet die optimale Zustandswertfunktion
- Leitet daraus die Policy ab

Value Iteration
- Kombiniert Policy Evaluation und Improvement in einem Schritt.
- Berechnet die optimale Zustandswertfunktion
- Leitet daraus die Policy ab
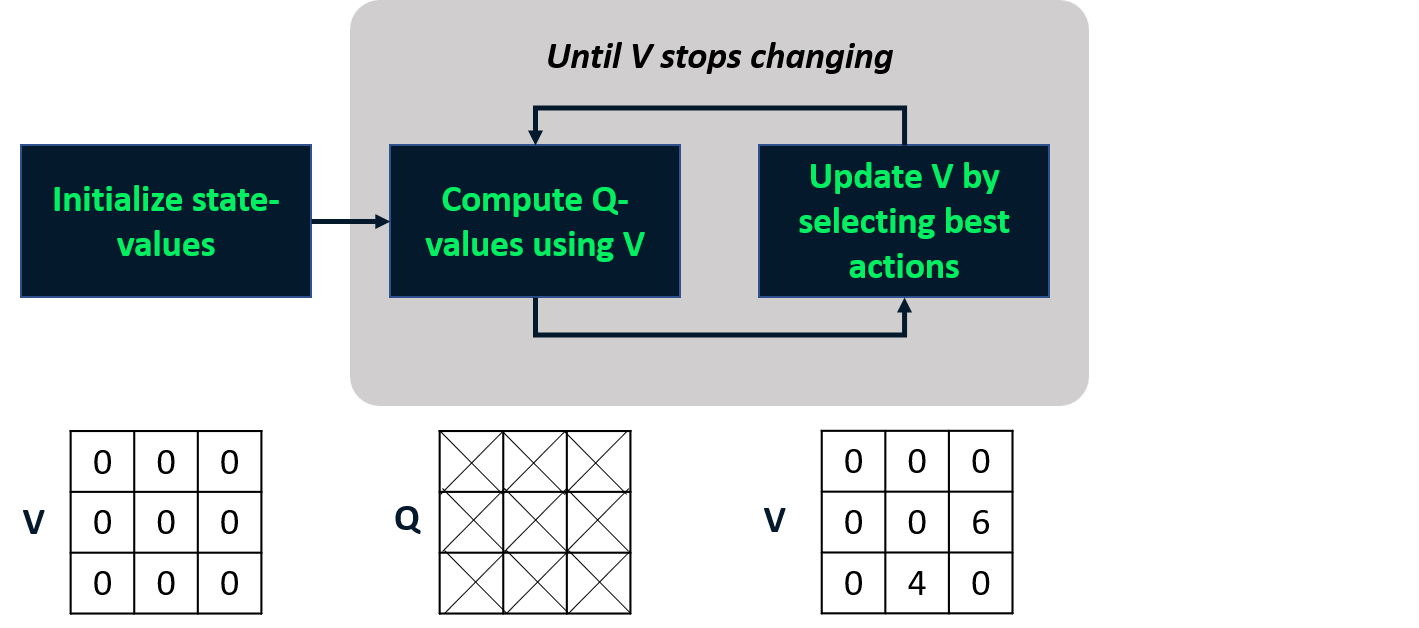
Value Iteration
- Kombiniert Policy Evaluation und Improvement in einem Schritt.
- Berechnet die optimale Zustandswertfunktion
- Leitet daraus die Policy ab
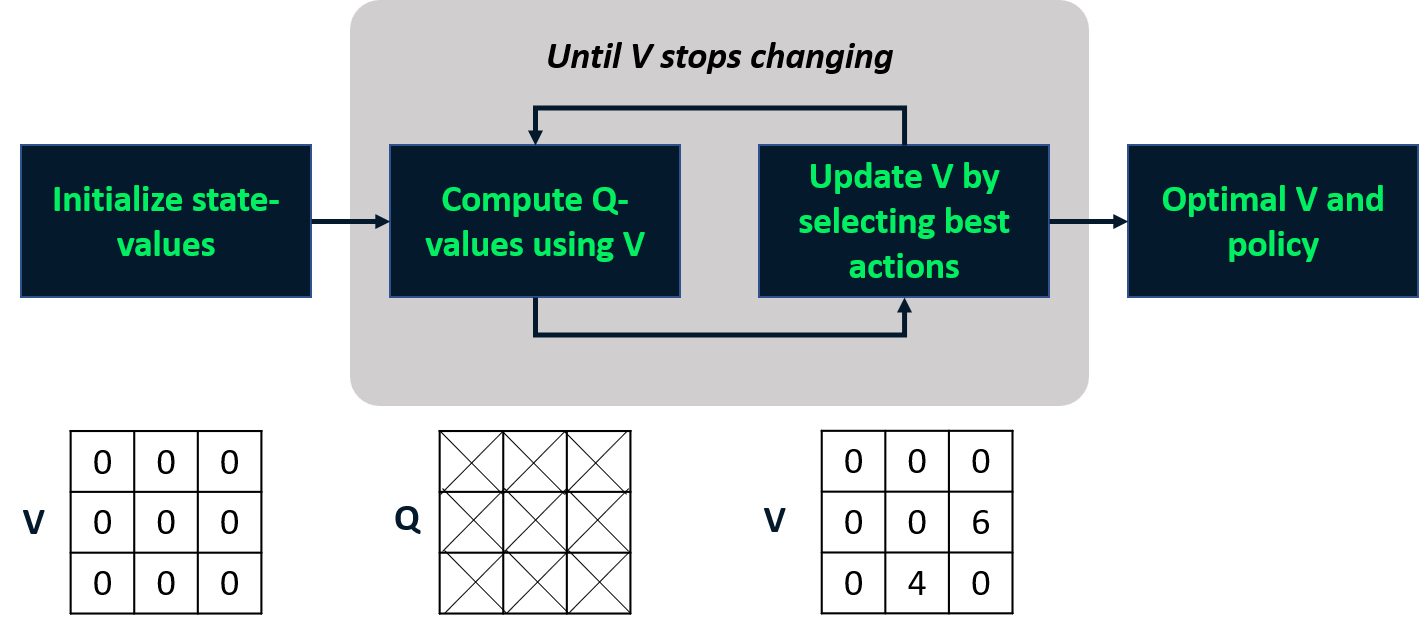
Value Iteration
- Kombiniert Policy Evaluation und Improvement in einem Schritt.
- Berechnet die optimale Zustandswertfunktion
- Leitet daraus die Policy ab
Optimale Policy

