Überblick über die Textklassifikation
Deep Learning für Text mit PyTorch

Shubham Jain
Instructor
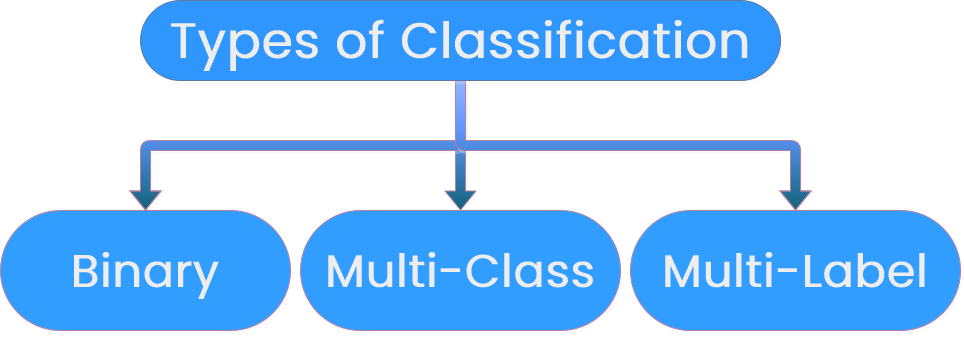
Textklassifizierung definiert
"- Texten Labels zuweisen
- Wörtern und Sätzen Bedeutung geben
 {{6}}"
{{6}}"
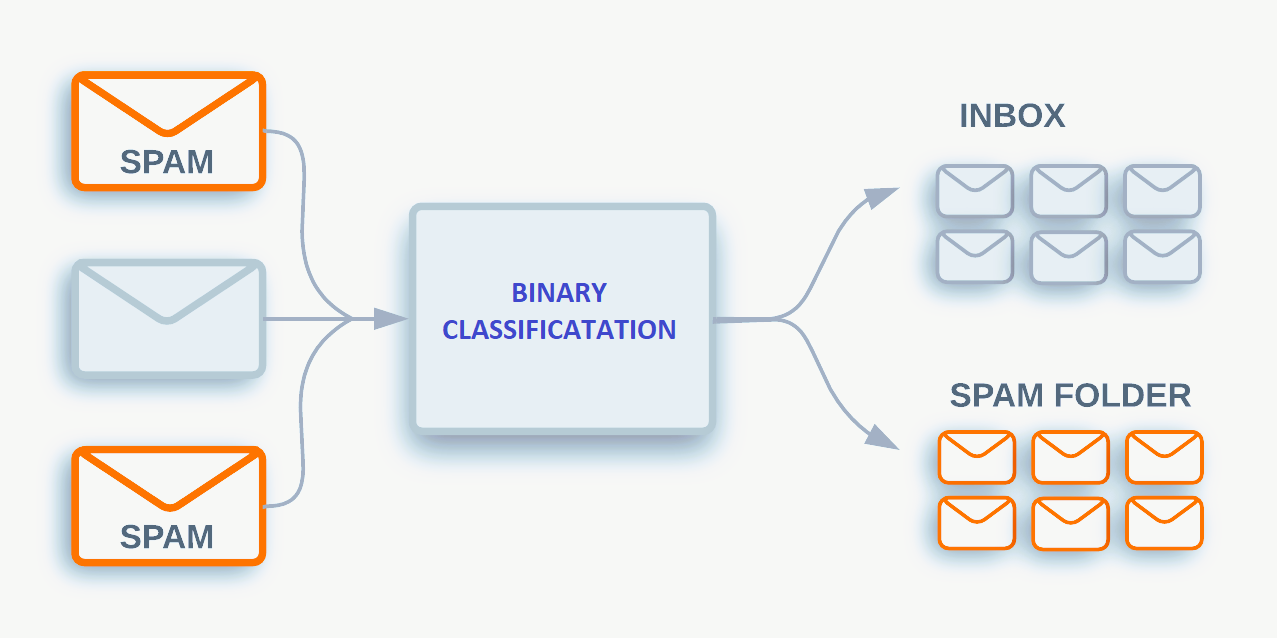
Binäre Klassifikation
" {{2}}"
{{2}}"
1 https://storage.googleapis.com/gweb-cloudblog-publish/images/image4_v2LFcq0.max-1200x1200.png
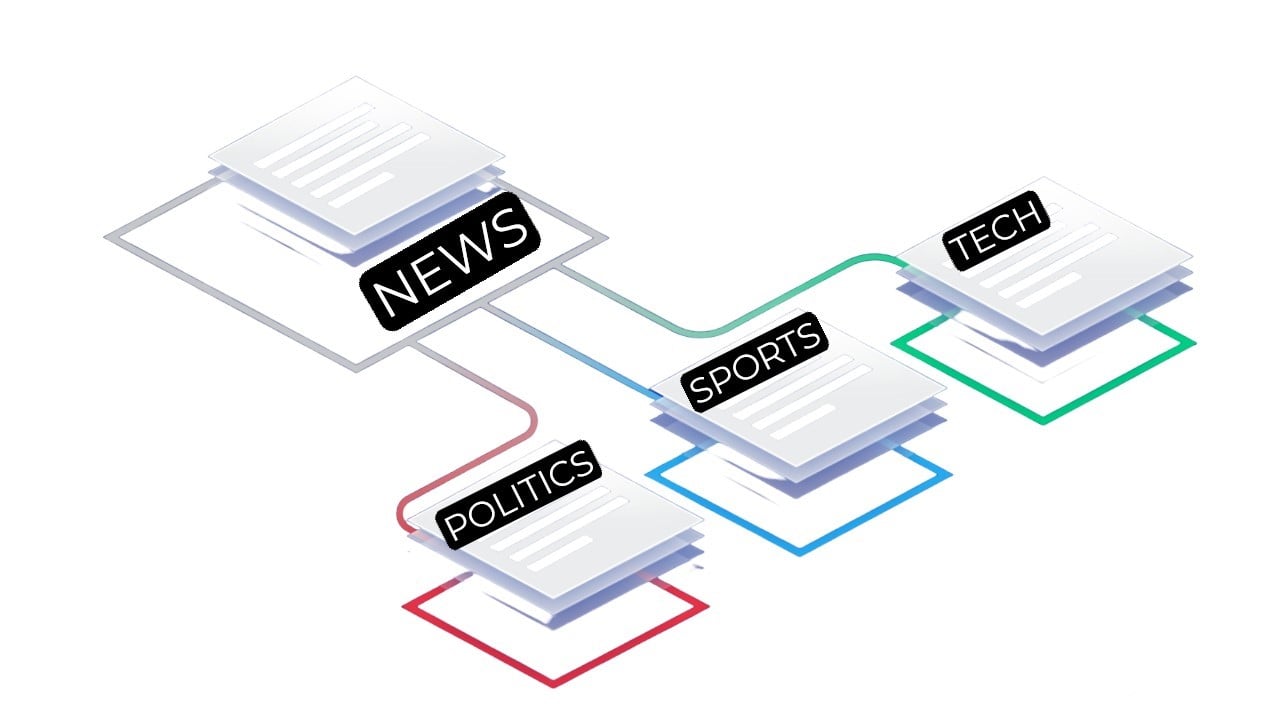
Mehrklassenklassifizierung
" {{2}}"
{{2}}"
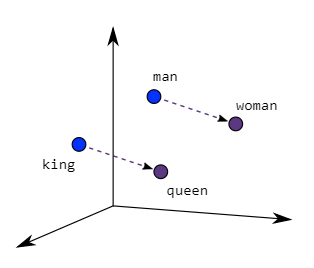
Was sind Wort-Embeddings
"
 {{3}}"
{{3}}"

