Kodierung von Textdaten
Deep Learning für Text mit PyTorch

Shubham Jain
Data Scientist
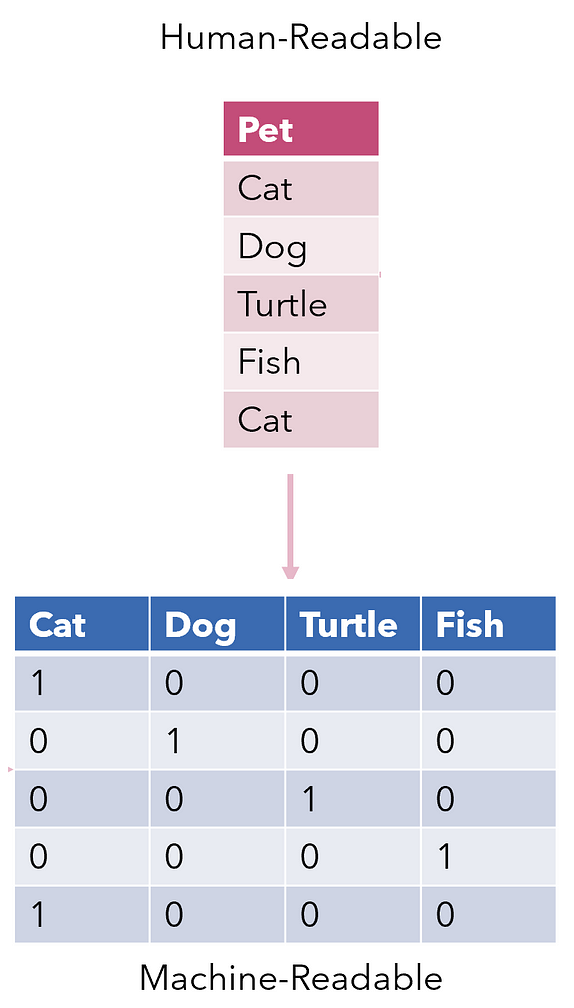
Textkodierung
"
- Text in maschinenlesbare Zahlen umwandeln
- Analyse und Modellierung ermöglichen{{2}}"
" {{3}}"
{{3}}"
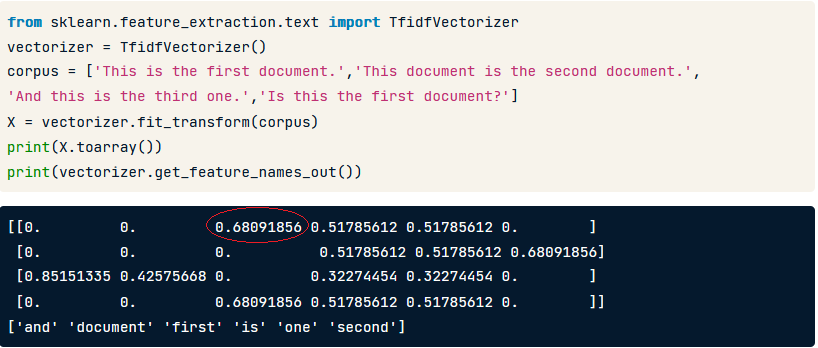
TfidfVectorizer
" "
"
Deep Learning für Text mit PyTorch
Shubham Jain
Data Scientist
"
"{{3}}"
""

