Gradient-Boosted Trees mit XGBoost
Kreditrisikomodellierung in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Entscheidungsbäume
- Liefert Vorhersagen ähnlich wie logistische Regression
- Ist keine Regression
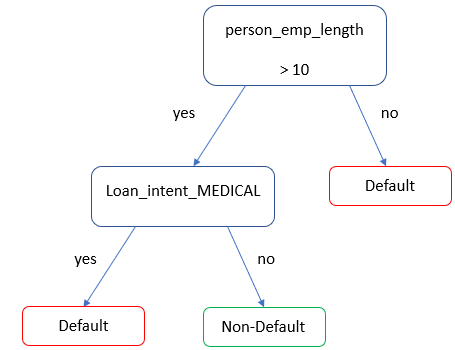
Entscheidungsbäume für den Loan-Status
- Einfacher Entscheidungsbaum zur Vorhersage der
loan_status-Ausfallwahrscheinlichkeit
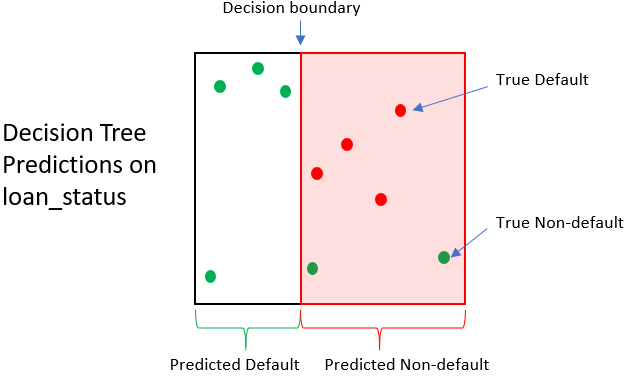
Wirkung des Entscheidungsbaums
| Kredit | Wahrer Status | Progn. Status | Rückzahlungswert | Verkaufswert | Gewinn/Verlust |
|---|---|---|---|---|---|
| 1 | 0 | 1 | $1,500 | $250 | -$1,250 |
| 2 | 0 | 1 | $1,200 | $250 | -$950 |
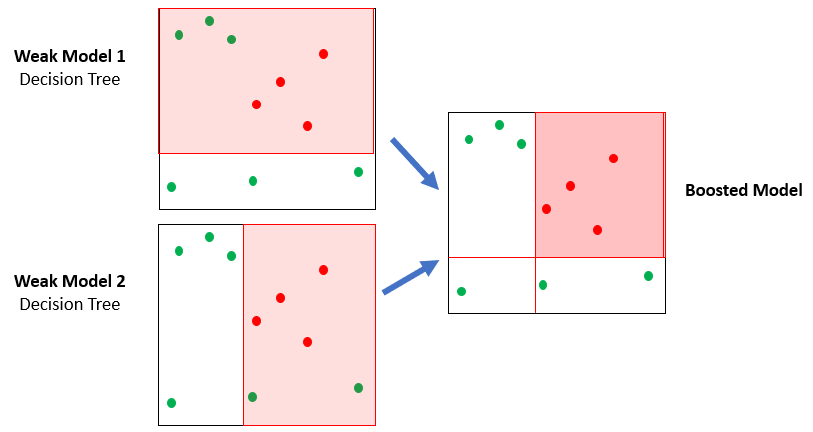
Ein Wald von Bäumen
- XGBoost nutzt viele einfache Bäume (Ensemble)
- Jeder Baum ist nur leicht besser als Münzwurf