Leistung des Kreditmodells
Kreditrisikomodellierung in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Genauigkeit des Modells bewerten
- Genauigkeit berechnen
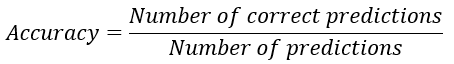
- Die
.score()-Methode von scikit-learn verwenden
# Genauigkeit auf den Testdaten prüfen
clf_logistic1.score(X_test,y_test)
0.81
- 81 % der Werte für
loan_statuskorrekt vorhergesagt
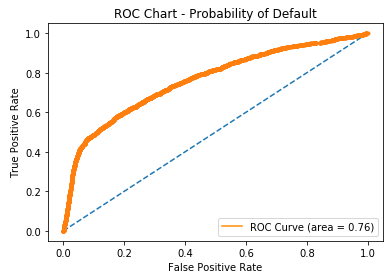
ROC-Kurven
- Receiver-Operating-Characteristic-Kurve
- Stellt True-Positive-Rate (Sensitivität) gegen False-Positive-Rate (Fall-out) dar
fallout, sensitivity, thresholds = roc_curve(y_test, prob_default)
plt.plot(fallout, sensitivity, color = 'darkorange')
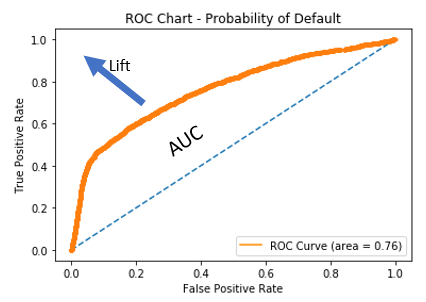
ROC-Diagramme analysieren
- Area Under Curve (AUC): Fläche zwischen Kurve und Zufallsprognose
Schwellen für Zahlungsausfall
- Schwelle: ab welcher Wahrscheinlichkeit ein Ausfall vorliegt
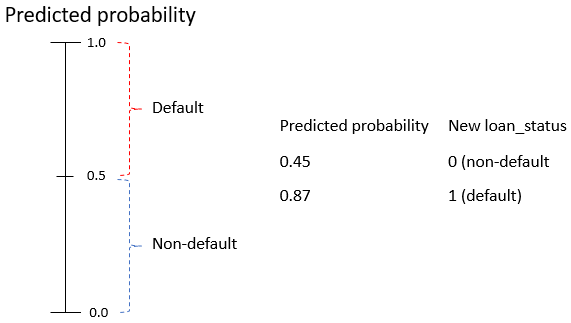
Schwelle festlegen
- Kredite anhand unserer Schwelle
0.5neu labeln
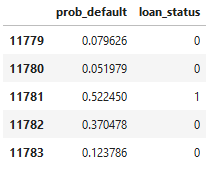
preds = clf_logistic.predict_proba(X_test)
preds_df = pd.DataFrame(preds[:,1], columns = ['prob_default'])
preds_df['loan_status'] = preds_df['prob_default'].apply(lambda x: 1 if x > 0.5 else 0)
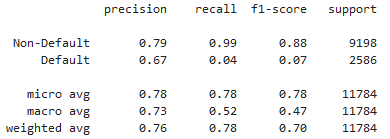
Kredit-Klassifikationsberichte
classification_report()in scikit-learn
from sklearn.metrics import classification_report
classification_report(y_test, preds_df['loan_status'], target_names=target_names)
Klassifikationsmetriken auswählen
- Ausgewählte Komponenten aus
classification_report()entnehmen - Funktion
precision_recall_fscore_support()aus scikit-learn nutzen
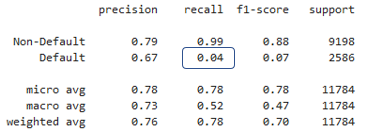
from sklearn.metrics import precision_recall_fscore_support
precision_recall_fscore_support(y_test,preds_df['loan_status'])[1][1]

