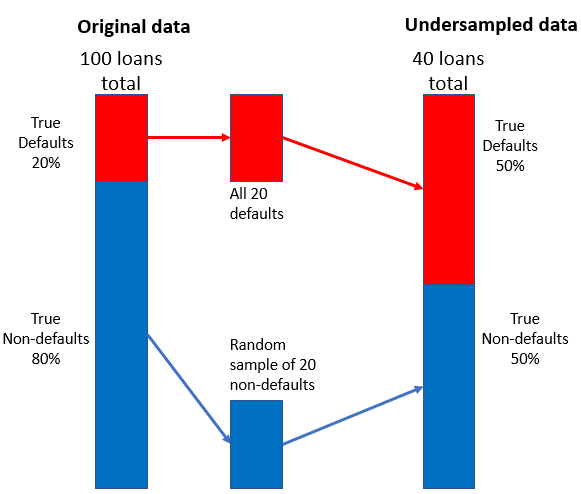
Klassenungleichgewicht bei Kreditdaten
Kreditrisikomodellierung in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Verlustfunktion des Modells
- Gradient Boosted Trees in
xgboostnutzen Log-Loss als Verlustfunktion- Ziel: diesen Wert minimieren
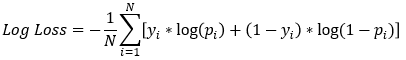
| Wahrer Status | Vorhergesagte Wahrscheinlichkeit | Log-Loss |
|---|---|---|
| 1 | 0.1 | 2.3 |
| 0 | 0.9 | 2.3 |
- Ein falsch vorhergesagter Ausfall hat höhere finanzielle Folgen
Undersampling-Strategie
- Kleinere Zufallsstichprobe der Nicht-Ausfälle mit Ausfällen kombinieren