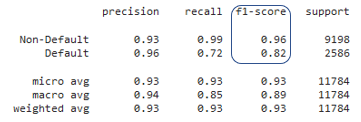
Spaltenauswahl für Kreditausfallrisiko
Kreditrisikomodellierung in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Interpretation der Spaltenwichtigkeit
# Spaltenwichtigkeiten mit importance_type = 'weight'
{'person_home_ownership_RENT': 1, 'person_home_ownership_OWN': 2}
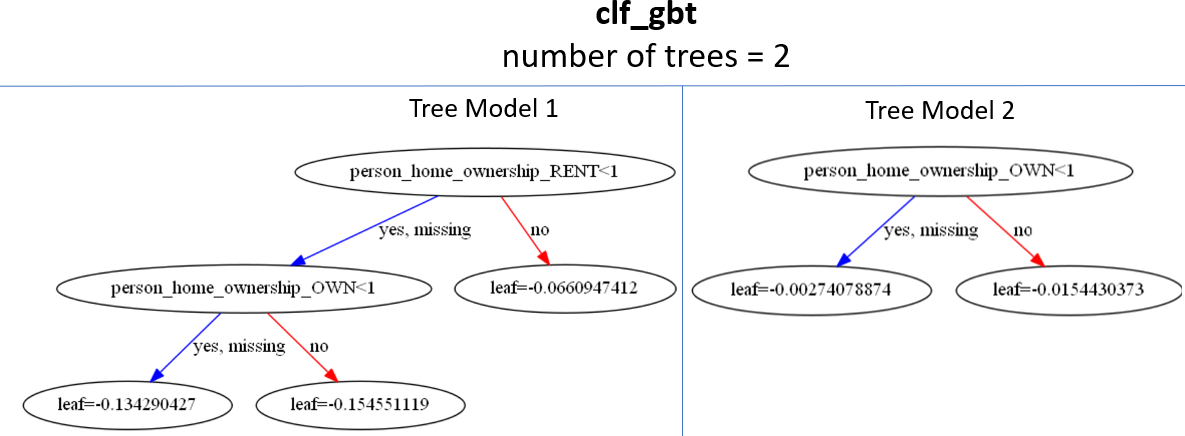
Spaltenwichtigkeiten plotten
- Nutze die Funktion
plot_importance()
xgb.plot_importance(clf_gbt, importance_type = 'weight')
{'person_income': 315, 'loan_int_rate': 195, 'loan_percent_income': 146}
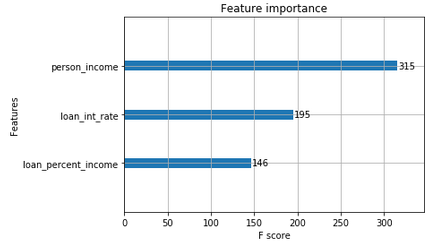
F1-Score für Modelle
- Genauigkeit und Recall für verschiedene Spaltengruppen zu prüfen kostet Zeit
- Der F1-Score fasst Genauigkeit und Recall in einer Kennzahl zusammen
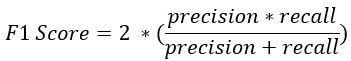
- Erscheint im
classification_report()